An interesting week in FLOSS it was, indeed.
For those of you who don't know, Codeberg e.V. is a German nonprofit organization specializing in open-source software hosting. It's often touted as "the EU alternative to GitHub", and since its launch in 2019 it has become important, and attracted many FLOSS projects, mostly driven by the GitHub exodus following Microsoft acquisition and subsequent enshittification.
Codeberg, as an association, has an established decision-making process by its voting members. Following a general assembly at the end of June, a vote for two motions was initiated, and the voting period ended a couple of days ago. The motions were about a change in the Terms of Use of Codeberg git hosting service: banning LLM- and cryptocurrency-related projects. Both passed.
Let that sink in for a moment: Codeberg now disallows hosting and sharing of:
- Projects related to cryptocurrency;
- Projects "heavily tied to the LLM ecosytem [sic]";
- Projects "that are created by LLM agents in autonomous ways";
- Projects "written and maintained with heavy use of LLMs".
This is all so wrong that I don't even know where to start, so maybe it's easier to start with what is not wrong. Usual caveat applies: personal opinions, blahblah.
Codeberg is an association, and an association is bound by the democratic decision-making process of its members. They have every right to decide anything that falls within their legal boundaries. However, I notice that both PRs were filed after the assembly and after the ballots went out, and the voted text was frozen before public review. I don't know exactly how the process at Codeberg works, but this doesn't scream transparency to me.
Cryptocurrency is controversial. I work in Web3-adjacent areas, and yet I have never embraced the cryptobro culture, I have never endorsed the use of blockchain for anything but an extremely limited set of applications, and I have previously written about it. So, I understand if a community is averse to anything that is Web3-related.
LLMs are controversial. There are problems with this technology and with the surrounding ecosystem, and if you are a regular reader of this blog you already know that I'm not shy about pointing them out. Others issues are also relevant, such as the environmental aspects, the socioeconomic impact of datacenters, and the copyright issue. So, I understand if a community is averse to anything that is LLM-related.
I understand it, but I don't agree with it, because it's 2026, and if you still think you can just stick your head in the sand and wish for these ugly bad things to go away, well, I have bad news for you.
All this unbridled hatred for AI and Web3 reeks of neo-Luddism. It's the same fear of the unknown that fuels distrust in other areas, such as quantum computing, nuclear fusion, and most forms of deep tech. Social media amplifies it. I also wrote before about it.
Let's talk about the AI angle. The original wording of the amendment and discussion around are very confusing. The recently released explanatory blog post from Codeberg tries some form of damage control, but does a very poor job at it. It lists various reasons, from the undue burden that LLMs put on the already strained Codeberg infrastructure to the human aspect. It all reads as a political declaration, but it does not explain how the new resolution fixes, or even just mitigates, any of these things.
Strained servers due to crawling - how does banning LLM-related projects protect against this? Codeberg already uses Anubis to hinder bot crawling. Whether this is still relevant in 2026, or whether there is irony in the fact that a PoW antibot system is deployed to fight environmentally hostile LLMs, is a topic for another post. But my point is: how does banning Codeberg-hosted LLM-related or vibe-coded projects help on this angle?
Emphasis on community and human collaboration - this blog post refuted this point very well. TL;DR: FLOSS is not mainly about collaboration. Collaboration is enabled by being FLOSS, but most FLOSS projects are one-man shows. So, this explanation is BS.
At least the blog post has the decency of not touching the copyright issue, because most of the arguments I've seen floating around from the ban-happy fancrowd are childish and wannabe-lawyer ones.
But most importantly: what does "heavy use of LLM" mean? And, how does one even detect AI-generated code in 2026?
Even if I can sympathize with the intent of not having Codeberg turn into another SlopHub, this fairy-tale wishful thinking is not constructive. If there were a magic spell able to flag with confidence code generated with AI by more than X% amount, whatever X or surrounding policy is, then one could be silly enough to think of enforcing the ban. But I don't believe in magic, and you shouldn't either. I can already smell the mutual witch hunts across projects and "camps":
- FLOSS project "OpenHemorrhoid" splits over a dev dispute on tabs-VS-spaces; now we have "OpenHemorrhoid" and "LibreHemorrhoid" accusing each other of AI-generated code at every PR;
- Indie dating sim game "Kawaii Shinobi Kanojo" is targeted and harassed with unproven AI-gen reporting because the lack of nonbinary characters is interpreted as a queer-phobic political stance of the dev;
- Libre "ICE tracker and reporting" app is taken down not by US authority overreach, but by mass allegations of AI-generated code.
But wait: digging in the discussion thread reassures us that:
"No one has any 'right' to get AI or crypto projects removed from Codeberg. Trolls cannot file false claims en masse and demand action to get someone else in trouble. If they do, then Codeberg mods can quickly dismiss those false claims, they do not have to disprove them. Banning a project is way more work than not banning it, so there will be no 'purge' and no mass-banning. No one has time for that. We just need to get rid of the worst and most obvious offenders, that's all. Humans with brains will decide on a per-project basis."
I leave to the reader to decide whether this reassurance is acceptable or even realistic.
Let's talk about the cryptocurrency projects ban. Interpreted as it is, it also covers privacy-related projects like Monero, or educational projects. One has to dig into one of the comments in the discussion thread to be reassured that, no, that is not the intent! It's only about "Content that harms the reputation of Codeberg, such as cryptocurrency related projects".
I think the reputation of Codeberg has now been harmed enough. This decision will backfire badly, it's just a knee-jerk reaction that has clearly not been thought through well enough.
Supporters of the ban say that this "draws a line", that "it does not need to be perfect", nor "black-or-white enforceable", that "is not meant to be applied blanket-wide to all projects, only those which are harmful to the community", as if having to constantly worry about the next mood swing of the Codeberg general assembly were an acceptable Sword of Damocles for any reputable project. What's next? Banning US users? Banning software aligned with "capital-fascist" values? Open-source banking/wallet apps? Quantum computing tools? Robotics? Here is another HN comment I found:
"My issue [...] is that this is changing the rules on people. [...] It is unclear to me if the specific community that Codeberg wants to be today will be the one it wants to be in a year from now, because clearly it's changing. I cannot rely on a service provider that does change that quickly."
To me, this is a perfect recipe to relegate Codeberg to irrelevance. And we are already seeing the beginning of a new exodus.
Here is my conspiracy theory: the vote was pushed or manipulated from the inside by Big Tech. Whether this is true or not, one thing is sure: folks at Microsoft, GitHub, OpenAI etc. are now popping champagne.
I am a regular Codeberg user, left GitHub in 2019, and co-maintain Libre projects that have nothing to do with Web3, and which have seen little to no AI in development. I, like most Codeberg users, was not even aware that this discussion was taking place. When I originally escaped GitHub, I chose Codeberg exactly for the ethical stance and values. For me, anti-censorship is a non-negotiable ethical value. The folks at Codeberg have the right to run their org as they want. However, having now shown that they consider "censorship" good when it's about things they dislike, this made it clear that their values and mine are not compatible (even if I dislike those same things, mind you).
I'm moving off Codeberg, probably to Radicle. But I feel a bit sad, because Codeberg had the potential, in my opinion, to become the European alternative to GitHub, and they have made it clear that they are neither ready nor willing to become so. Which is fine: software is political, and everyone has the right to express their political stance.
But we are now back at square one: we still desperately need an alternative to GitHub.
(2026-06-03) Quantum Security Misconceptions: PQ Encryption is not the only Urgency
Today I have read A Post-Quantum Future for Let's Encrypt and, oh boy, it's refreshing! TL;DR, Letsencrypt considers migration to quantum-resistant certificates a priority, and lays down a reasonable path to migrate. In so doing, they take the time to explain how, so far, the security community has been mainly focused on the problem of quantum-resistant secrecy (encryption) rather than authentication (signatures/certificates), and they explain why the sentiment is changing now, and why it is particularly relevant for Letsencrypt.
Not wanting to be the "told you so" guy, I've been saying this for at least 2 years now:
Post-quantum authentication is no longer a problem the Web PKI ecosystem should defer. Long-lived keys (root certificate authorities, code-signing keys, identity systems) are particularly valuable targets, and new technology takes years to gain broad adoption, so the work has to start early.
This is a problem that I have met so many times talking with people: they parrot the "Harvest-Now-Decrypt-Later is the only urgent problem, signatures can wait" mantra, and this piece of misinformation has spread so much that even AI repeats it (because it has been trained on open data, where the overwhelming sentiment has been following this trend), thereby reinforcing the problem. Ask Claude/ChatGPT/Gemini about this issue, and they will invariably tell you that PQ signature migration is less urgent because signatures are not subject to retroactive quantum compromise.
There are two problems here.
The first one is included by the Letsencrypt announcement: the migration path for signatures/certificates is typically longer and more complex than encryption: long-lived certificates, firmware update keys, secure boot certificates, these are all objects that are painful to migrate.
The second one, even more serious in my opinion, is: "retroactive" in respect to what? "Retroactive" presupposes you can observe the trigger (the arrival of a cryptanalytically-relevant quantum computer), but this is precisely the kind of capability that an adversary keeps secret, and a quantum forgery is operationally indistinguishable from, e.g., key exfiltration, a library bug, or a classical break. You may see a forged signature, a drained wallet, a failing certificate, and you would have no way to attribute it to quantum cryptanalysis. The threat is dark: reactive migration against an unobservable trigger is structurally impossible.
This is not to say that Harvest-Now-Decrypt-Later is a less urgent threat, but it's not as asymmetric as people have been believing so far. Glad to see things are changing!
(2026-05-28) Rise and Fall of Hosting Provider Gandi.net
It's been a while I wanted to write this post, but it always slipped at the bottom of my priorities. Why, after all, spending time to bash a service like Gandi.net? Surely there are countless, more worthy targets of my snarky rage. But I think Gandi is a good case, because of the many expectations that were betrayed, and the deeper reflection linking to vampire capitalism. Gandi is a textbook example of enshittification, which I think is sad but interesting to talk about.
Gandi: The Origins
For those of you who don't know, there was a time when recommending a domain registrar to a privacy-conscious friend was easy. Everyone in the FLOSS community knew: Gandi was the "good one".
Gandi (Gestion et Attribution des Noms de Domaine sur Internet) was founded in 2000 by a group of French digital rights activists and internet pioneers: Pierre Beyssac, Laurent Chemla, Valentin Lacambre, and David Nahmias. These were not your usual Silicon Valley folks: Lacambre had founded altern.org, one of the first independent web hosting services in France, and had been messing around with French courts for his principled stance on hosting freedom. Chemla was a vocal advocate for internet freedoms, first French hacker to be jailed for computer crimes, and who went on to co-found La Quadrature du Net. These people built Gandi with the explicit goal of opening up the domain name market, which at the time was dominated by a handful of US monopolies.
And they were successful: Gandi became one of the first ICANN-accredited registrars in Europe, and since its beginning it distinguished itself with a philosophy that was alien to the industry: transparency, ethical business practices, user privacy, and no advertising. Famously, their motto was "No Bullshit": no hidden fees, no dark patterns, no selling your data. The company grew entirely through word of mouth.
Gandi took its own motto seriously and beyond. The company ran an extensive sponsorship programme ("Gandi Supports") that provided free infrastructure to a remarkable portfolio of open-source projects and civil liberties organisations: Creative Commons, the Electronic Frontier Foundation, OpenStreetMap, and many others. The Open Source Initiative itself was hosted on Gandi-donated infrastructure. Creative Commons moved all of its domains to Gandi specifically because of the quality of service. Gandi was known for standing up to illegal takedown requests in court (although, from my own research, the internet rumour according to which Gandi fought off the French government takedown request for Wikileaks seems to be fabricated or misrepresented, just Gandi hosted for some time the mirror wikileaks.fr). Beyond domains, Gandi offered VPS cloud hosting, web hosting, SSL certificates, and (crucially for many of us) email hosting, with two free mailboxes included with every domain registration.
Until 2019, the company did not distribute profits and took no debt, reinvesting all margins into the business. For the technical crowd, Gandi was not just a service provider: it was an institution, a rare example of a company that aligned its business with its values. Sure, Gandi was never cheap: domains were always a bit above market rate, but customers paid that premium gladly, knowing that you got ethical infrastructure and "No Bullshit" included in the price. And for well over a decade, that promise held.
Enters Private Equity
And then, of course Private Equity arrived and fu**ed up everything.
The four founders eventually split into two factions: Lacambre and Chemla wanted to reinvest profits into solidarity, cooperative, and activist projects, while Beyssac and Nahmias favoured a more conventional commercial direction. The resulting deadlock led all four to sell the company in 2005 to an outside team led by Stephan Ramoin, formerly of Lycos. On 28 February 2019, Ramoin announced that private equity firm Montefiore Investment, together with M80 Partners, had acquired a majority stake in the company. Ramoin retained a minority as CEO.
The announcement was dressed in the usual language of "growth", "expansion", and "new opportunities", but for anyone who knows how PE operates, the rest of the story is easy to imagine.
Almost immediately, things started going south. In January 2020, a storage incident at Gandi resulted in temporary data loss for customers on their VPS hosting. The company's response was to offer affected users "cloud credits" in compensation. When customers grew angry on social media, a Gandi communications person tried to defend the position by arguing that the "No Bullshit" motto "does not exclude flaws". This was only a taste of the things to come.
In February 2023, Montefiore Investment sold its majority stake in Gandi to Total Webhosting Solutions (TWS), a Dutch pan-European hosting conglomerate. Together, they formed a new entity branded as "Your.Online". The merger was presented, in Gandi's own words, as "joining forces" with a company that shared its "DNA and entrepreneurial values". Except that Total Webhosting Solutions' business model is: buy established European hosting brands, absorb their customer bases, and extract value. The consequences should not surprise anyone.
The Shitpocalypse
In June 2023, Gandi informed its customers of a "pricing update".
Domain name renewals saw increases of 25–50%, depending on the TLD: .com renewals jumped by 34%, .net by 45%, .org by 32%, some country-code TLDs became almost comically expensive. But the real infamy was the email: Gandi had always included two free mailboxes with every domain registration (next to their Standard and Premium plans, which were anyway pretty good and cheap). This was a foundational part of the offering, and for many users (including me) it was a primary reason for choosing Gandi. Well, in 2023 Gandi announced the end of this included service: the free tier was being discontinued, replaced by a "new and improved" paid service. The pricing of this new service was ridiculous: the Standard mailbox plan went from €0.35/month to €3.99/month, while the Premium plan went from €1.75/month to €5.99/month. The justifications: "increased storage", "better anti-spam protection", "stronger security".
What made this particularly egregious was the treatment of customers who had pre-paid for multi-year domain registrations: many users had registered domains for 5 or even 10 years in advance, partly because the included email was part of the deal. Gandi now informed them that their email would be suspended unless they paid extra, effectively retroactively changing the terms of a service already paid for. The community reaction was furious. I don't even know how they could get away, legally, with a stunt like this, but it didn't finish here! Prices kept creeping up more and more over time.
My Own, Kafkesque Adieu
I had been a loyal Gandi customer for years. I paid the premium willingly, because I knew what I was getting in exchange, I recommended them to colleagues, to projects, to anyone who asked. When you work in cryptography and privacy, the choice of your infrastructure providers is not just a practical decision, it's kind of a statement of values. When the price hikes hit and the free email was killed, for me the writing was on the wall. This was the new Gandi: an empty husk with a legacy brand, being milked for every cent its captive customer base could be squeezed for. The ship was sinking.
I decided to migrate, but it took me longer than I would have liked, because finding a suitable alternative that met my requirements was a project in itself, and I will write about that in a future post. But the migration process itself deserves its own special mention, because it was a masterclass in hostile user experience.
First, I had to log in in my user panel and look for the "Delete Account" section (not easy to find). But then:
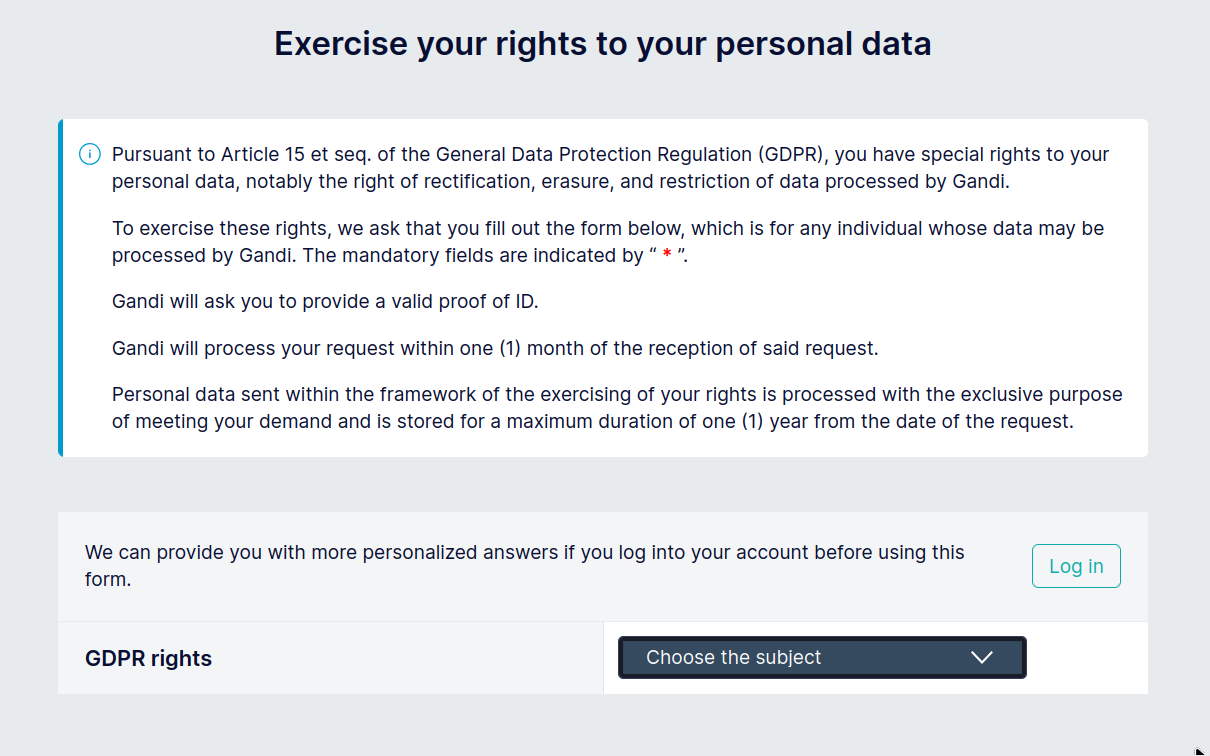
OK, sure, let's fill this other form instead.
Yes, you read it right: you need to provide a valid ID. Never mind the fact that you are already logged in with your already super-authenticated user account. The possible options in the drop-down menu are:
- Right of access (Article 15)
- Right to data portability (Article 20)
- Right to erasure (Article 17)
- Right to object (Article 21)
- Right to rectification (Article 16)
- Right to restriciton of processing (Article 18)
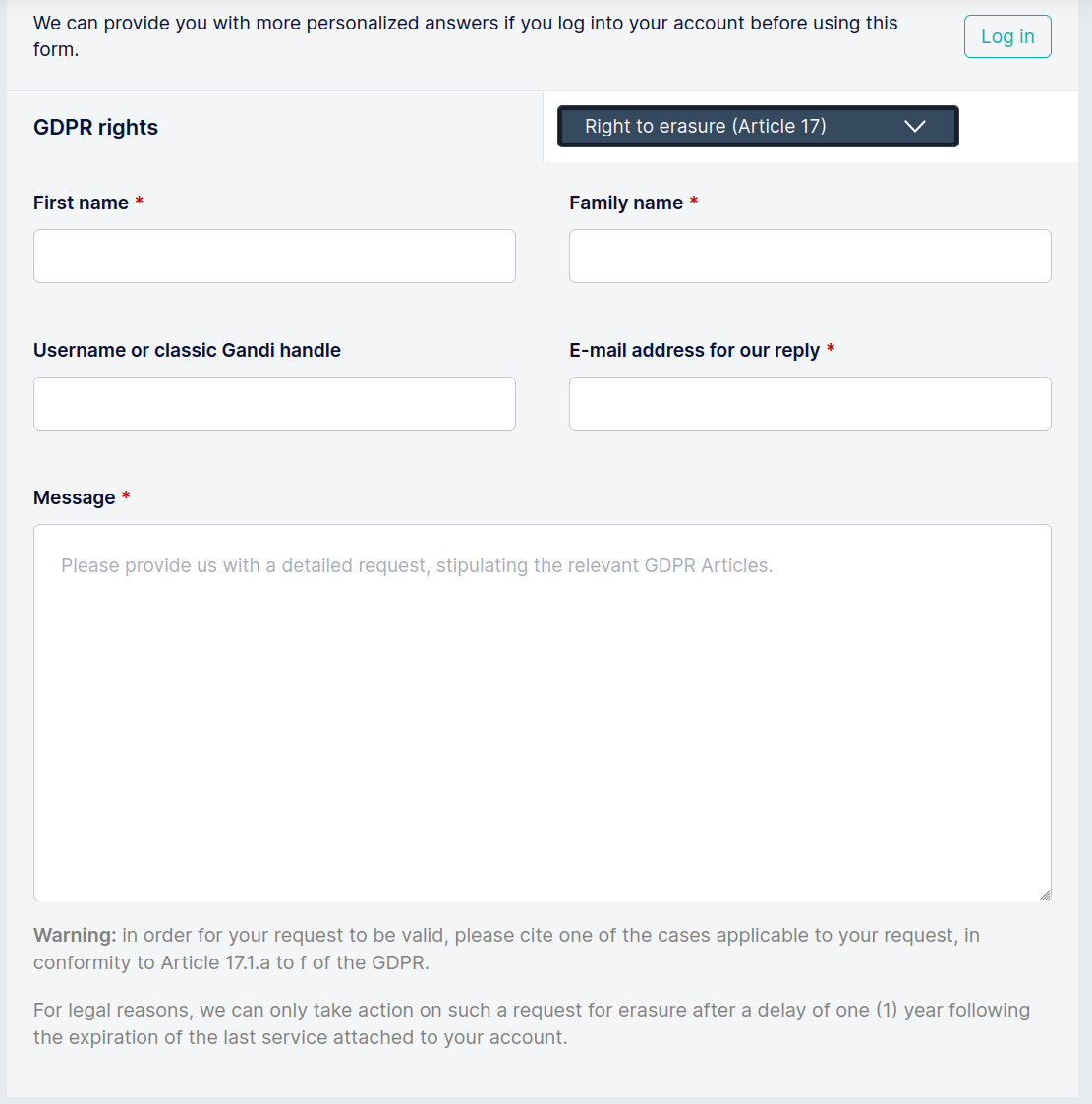
OK, let's go for Art. 17 and be done with it.
What the hell is "For legal reasons, we can only take action on such a request for erasure after a delay of one (1) year following the expiration of the last service attached to your account"? Is this even legal?
Whatever, let's do it and goodbye. Nope. After a few days I receive this email:
Dear Sir,
We acknowledge receipt of your request for deletion in accordance with Article 17 of the GDPR.
However, we are unable to comply with your request at this time because your account still contains active products (like issued-certificates). You must first delete them, and once we have received confirmation from you, we will then be able to proceed with the deletion of your account.
Thank you in advance for your understanding.
First, this is already way beyond the "undue effort" forbidden by GDPR. I am asking you to delete my account, you should terminate these leftover products for me.
Second... What active products? I thought I had already migrated away all my domains, closed all my mailboxes, etc. Issued certificates? I have never used Gandi-issued certificates. Let's check.
Well, there they were, hidden somewhere in the user product panel. A couple of Gandi-issued SSL certificates for my latest-acquired domains. Which I have never requested, never used, never been aware of, and that LUCKILY I am made aware of right now because, as it turns out, they are free only for the first year, then you are automatically billed for them, and the 1-year period is just about to expire. And I have to manually revoke them one by one, because there is no "select all" option. Surely this is something introduced recently, as my older domains did not have the associated certificate.
YOU EGREGIOUS SCUM.
Reflections: The Social Contract, Broken
The story of Gandi is not unique, it is a pattern so well-established that it has become almost boring: a company is built on genuine values by people who care, it earns the trust and loyalty of a community that shares those values, it grows sustainably on the strength of that trust. Then vampires arrive, see a captive customer base and a beloved brand, and acquire it. Enshittification is served.
What makes this pattern particularly insidious is the way it exploits a social contract. As users, when we commit to a service provider, we are entering into an implicit agreement: we pay a fair price, sometimes a premium, in exchange for reliability, respect, and continuity. We extend trust, we make ourselves dependent. And then the rug is pulled.
The people who built Gandi understood that trust is the most valuable thing a company can have, and that it is earned through behaviour, not branding. The people who own Gandi now understand that trust is simply leverage: a switching cost that allows you to raise prices without losing customers as fast as you otherwise would. This is what PE does, not always, but often enough to constitute a pattern. It finds something that works because it was built with care, buys it, extracts the value, and discards the husk. The customers, the employees, the community, the people, they are all inconveniences.
For those of us who care, the lesson is important: you can do everything right, you can choose the ethical option, pay the premium, build your stack on principles, and none of it matters if the company on the other end can be sold to the highest bidder. The only real defense against this is digital self-sovereignty. But that is a conversation for another day.
(2026-05-04) Vampires, prisoners, and late-stage capitalism
This blog post is a bit different, but it will help me crystallize some thoughts that I might reference to in future posts.
There is a lot of talk recently about "late-stage capitalism", whatever it means. Well, probably not so "recently", but I've seen the term popping up on random online discussions, social media, even in unexpected real-life settings. I've seen people arguing that merely mentioning this word frames you in a certain political stance; I don't care and will keep using that term for the sake of this blog post. But I am no economist, nor do I have a political science background, so I will do the only sensible thing instead: I will talk about Japanese anime.
There is a rich "vampire" subgenre in Japanese manga and anime literature, which more or less takes on and expands the Western folklore with certain quirks and tropes. A quite recurring one (for example in Shiki or Call of the Night) is the relationship between vampirehood and blood feeding: a vampire needs human blood to survive or anyway to keep their power strong, but they cannot feed on vampire blood, they find it disgusting/poisoning. The problem is that biting a human (I'm simplifying here) eventually turns them into vampires as well, so now not only has the first vampire to find a new prey, but you have a second hungry one as well.
If we see this from an analytical perspective, we can say that:
- It's a lose-lose situation: the vampire tries to satisfy their needs, but in so doing they create more craving and more scarcity.
- It's, in a certain sense, a form of "super-preying": not only you must remove a living prey from the available pool in order to survive, but in so doing you create a competitor.
- Which is not too different from normal predatory behavior after all (hunt-eat-reproduce), just on a faster scale.
- Given the exponential nature of the process, the situation can only work under careful management of parameters: probability of spawning a new vampire per bite, how many times/month a vampire needs to feed, vampire mortality, human reproduction rate, etc. The stability of this system is very brittle.
- Any attempt at redemption or happy ending, e.g. through vampire-human love, is doomed to fail without some extra ad-hoc story artifact.
Hence why vampirism is usually depicted as a terrible curse, and notice that the vampires themselves need not be evil: they are perfectly rationally selfish, doing just what they need to survive. Take the holiest, most vegan Saint on Earth, and their mental model will not be substantially different, in a Hobbesian sense. The original sin, the "Evil act", was creating the first vampire, all the rest follows in a very amoral way. And, eventually, the vampires always lose: either the vampires succumb, or the humans succumb - and thus also the vampires do. But there is a theoretical loophole, which is explored in certain works such as The Promised Neverland: vampires and humans could collaborate, the former by strictly limiting and controlling their feeding urges, the latter by voluntarily offering a certain amount of their members as vampire food.
In game theory, a Nash Equilibrium is a situation where no player could gain more by changing their own strategy. Notoriously, a Nash Equilibrium is not always Pareto-optimal, meaning that it does not always improve the players' global profit. A typical example is the Prisoner's Dilemma: the most rational strategy for a prisoner is to testify against the other, because, whatever the other does, the first prisoner gains more by testifying. Since this reasoning is symmetric, the Nash equilibrium in that case is both prisoners testifying against each other, which is not Pareto-optimal, because it would be globally better for both of them to stay silent. In other words, there is a divide between selfishness and collaborative behavior. Iterated games complicate this, but real markets have asymmetric information and intergenerational externalities that break the iteration, so this divide stands.
I'm sure countless smartest people have said this better than me before, but I claim that there is no qualitative difference between species that survive out of selfish behavior (like us) and species that, apparently, prioritize collaboration (like ants). In fact, in the latter case, we, selfishly-wired organisms are inclined to change our viewpoint, and look at the ant colony as a more familiar single selfish organism instead, the same way our selfishness emerges from the behavior of non-conscious individual cells. On the other hand, we see that human communities which prioritized some form of collaboration thrived over more disorganized communities. So, there is a Yin-Yang-like duality of selfishness and collaboration/altruism: they are not the same, but deeply linked.
In my view, capitalism takes this duality to the extreme. The argument basically is: "The best strategy for the community to thrive is if everyone improves from their own vantage point; hence let's build a system that rewards one's selfish growth, and magic will do the rest". But this is clearly a weak argument: see Prisoner's dilemma. So I think here the real, untold, terrifying excuse, deep within the mind and soul of too many folks, is:
"Since we don't know if life is a game which admits a Pareto-optimal Nash equilibrium, let's YOLO for the safe choice!"
What is the "safe choice"? Enjoy fossil fuels while you're still alive, and screw the next generations? Believe in infinite economic growth and live accordingly? Turn as many humans as possible into vampires? This can only be a winning strategy in a scenario where everything, eventually, collapses: if we are doomed to end, better live at the fullest now. But I see a disconnection here:
- On one hand, neoliberals argue that stocks will keep going up, that economy is going to keep growing, that resources are pretty much infinite, that we will either reach the stars or mind-machine fusion before our planet becomes uninhabitable.
- On the other hand, if this were the case, the current capitalist-predatory behavior will still lower our chances of long-term survival, because it is a strategy that only works well on a limited time scale.
When I see people bashing the concept of "late-stage capitalism", the most common criticism is "late with respect to what?", which to me seems a super dumb argument.
I mean, sure, maybe you literally believe that capitalism can last forever. But even the Roman empire lasted less than 1500 years, and Hinduism is less than 4000 years old, so your belief is more than a religious one: it's hope. It's "the market will figure it out", as if it were an all-powerful god.
Or, you acknowledge that capitalism has an expiry date, and then honestly the argument of what "late-stage" means is pretty moot. Be it 10, 100 or 1000 years from now, the point is that you have set the course - and the curse - when you created the first vampire. This is a self-perpetuating, world-devouring machine that is very difficult to stop once in motion.
Maybe you see that capitalism is set to end sooner or later, but you think/hope that, eventually, a new, better system will rise, and that such system will naturally favor those already in a vantage point, so better accumulate wealth and status now, if not else because life and competition is hard, so you want your kin to reach that turning point. But are you sure the current trajectory goes in that direction, or even that we, as a species, will last long enough to see that moment? This is another religious belief, unsubstantiated by any evidence.
And consider this: the Western neoliberal doctrine is already in crisis today, because China is eating the world:
... This breaks our Western discourse. We were told that democracy and development go together. That free markets require free politics. That our system was the "end of history." But China proved you can pair authoritarian politics with a market economy.
If some of your tenets can be wrong after less than 50 years, how can you be so confident that some other ones will last forever? This is more than hubris, this is intoxication.
For me, late-stage capitalism is just a placeholder name for what I see with my eyes. Rising pollution and fossil fuel-driven climate change. Increasing inequality and wealth gap. Ad-tech and surveillance industry, AI-mageddon, enshittification.
I don't have an answer in this blog post on what we should do, or what will come next, but hear my words: when I read studies saying that hospitals acquired by private equity firms have worse patient outcomes, I know exactly why. Those patients are turned into vampires.
(2026-05-03) Quantum computers will break RSA-2048 by February 2032
I am not enjoying too much clickbait titles anymore, but they seem to work still in 2026. Plus, this one is not totally a clickbait. Kind of. This is not a serious estimate, but many folks who know me personally also know the story, I have told it many times. Maybe I better make it public at this point.
The story goes back to February 2012. At the time, I had recently started my PhD at TU Darmstadt in Marc Fischlin's research group. Part of the CS faculty at the time was not at the TU's main campus, but located in a commercial building in Mornewegstrasse (the old CASED building), near the train station. There was no mensa available nearby, so every day we would go out for lunch at some different, sad and overpriced small restaurant or bistro (the frustrating decision-making process of where to go every day, which eventually led to Paul Baecher's brilliant Lunch'O'Matic tool, is a story for another time).
Anyway, one day we were walking to lunch together with Stefan Katzenbeisser's group. Some of them asked me what my doctoral project was about, and upon hearing that I was looking into quantum security, someone (I can't remember for sure who, but I think Andreas Peter or Pooya Farshim) asked me: "So, by when do you think quantum computers will break RSA-2048?". Notice: this was clearly a loaded question, already in 2012, but my innocent and socially awkward self of that time (and still not completely used to German humor) answered with a candid "Dunno... 20 years maybe?". Which caused a few giggles, and the inquisitor snarkingly commenting "20 years... yeah, it's always 20 years in the future... that's what everybody always says!".
To which I felt *challenged*, so I BOLDLY replied "No, if I say 20 years it's 20 years! Since I want to be consistent, I will stick to my forecast and start counting 20 years from now! We'll see!".
And this is where the February 2032 date comes from. It started as a joke, and it still is. If you were expecting an accurate analysis of quantum computing resource estimates, sorry, this is not it.
But the more we approach the date, the more I feel I might not have been *completely off* in the joke. Especially since the recent news seems to bring the cryptapocalypse closer, to the point that some respected folks claim that 256-bit elliptic curve cryptography might be broken by 2029. RSA-2048 is harder to break than 256-bit EC dlog, but 3 years of gap at the current technological pace seems reasonable.
So, maybe it is indeed possible that RSA-2048 will be broken by QC by 2032! Or maybe not!
(2026-03-31) Q-Day is coming! New quantum attack resource estimates
Yeah, I'm kidding, the word "Q-Day" sucks. But I wanted to report about some recent breakthroughs on quantum attack resource estimates for asymmetric cryptography.
First of all, Google reports new techniques to attack 256-bit elliptic curves: most ECC-based applications including ECDSA and Bitcoin could be at risk way sooner than expected.
We estimate that these circuits can be executed on a superconducting qubit CRQC with fewer than 500,000 physical qubits in a few minutes [...] This is an approximately 20-fold reduction in the number of physical qubits required to solve ECDLP-256.
500'000 physical qubits are not so many! IBM alone already plans 1'080 interconnected physical qubits by 2028. And, remember, the ratio of physical-to-logical qubits (which is what counts for Shor's algorithm and friends) is also shrinking!
Interestingly, Google and friends did not release the blueprint for the attack circuit. In the name of "responsible disclosure", they only provided a zero-knowledge proof (ZKP) proving that the circuit works. This is, I think, a first in the realm of cryptanalysis disclosure.
The statement that our ZK proof demonstrates is the following: we possess a classical reversible circuit of a specified size which on most inputs correctly computes point addition on the elliptic curve secp256k. This is the primary bottleneck in Shor’s quantum algorithm
Then there is this other new preprint on ArXiV, which I have not reviewed yet, nor I can confirm or deny being legit or trash, but the claims are pretty... bold:
under plausible assumptions, the runtime for discrete logarithms on the P-256 elliptic curve could be just a few days for a system with 26,000 physical qubits, while the runtime for factoring RSA–2048 integers is one to two orders of magnitude longer.
The thing that resonates with what I've been saying before (archived) is that, at equal classical security level RSA is much harder to break quantumly than ECC.
And, I have been saying this since the 2010s: quantum cryptanalysis is one of those non-linear technology progresses that *will* take everyone by surprise when it arrives. Qubits quality and numbers go up, error-correction and attacks improve, investments scale up accordingly. It's a perfect storm of compound factors. Folks didn't listen, now time is ticking.
(2026-02-24) Chinese Propaganda in Open Source AI: Moxie Marlinspike's Confer
We have a problem. A big one.
After my previous blog post about Chinese propaganda in Infomaniak's AI assistant I was left with a lingering sense of hopelessness. I didn't realize how bad it was at the beginning. Now I do, and I'm scared.
First of all, I contacted Infomaniak's support regarding the issue with Euria. This is their canned response:
Thank you for your feedback, it is legitimate and the debate is necessary.
A few important clarifications: it was not Infomaniak that programmed Euria to refuse to respond to questions about Tiananmen. This behavior stems from the underlying model used at the time. Euria is based on a stack of open source models (including Mistral, Qwen, and Whisper for audio), which is constantly evolving in line with the state of the art, usage, and environmental impact.
The choice of open source is key: it allows us to understand the limitations and biases of the models, unlike the proprietary models of the industry giants, which also contain them—but in an opaque way.
Fundamentally, you are right: no source should be taken in isolation, regardless of the field. AI should never be an authority, but a tool to be contextualized, cross-referenced, and criticized, always bearing in mind its limitations and biases.
We are not satisfied with this situation either. When Euria was launched, there were no European models that were as powerful and efficient. We are actively working to develop the stack (Apertus, future Mistral models, etc.). The more European and ethical solutions are used, the more they will have the means to progress.
Your comment is therefore relevant: knowing the limitations and biases of the tools we deploy is an essential responsibility.
Thank you for your trust, we remain at your service.
It's not that I am unsatisfied with this response, I think it's more or less as good as it can be given the circumstances. It's just that this response exemplifies the reason why I feel so hopeless: we are literally waiting for a Savior to come and gift us with a performant, accurate, uncensored, superexpensive AI model for free, which is still a black-box but *pinky swear* it's going to be good this time! This is what Open Source AI is.
Moxie Marlinspike is the creator of Signal, a true cypherpunk with a proven distrust for technosurveillance. Last Christmas he launched his new venture, Confer, an end-to-end-encrypted AI chatbot, using TEE technology so that not even the server operators can ever access your chats. Despite the security limitations of TEEs, this approach is much, much better than chatting with your ChatGPT/Gemini/whatever. As Moxie puts in, just to say one:
When you work through a problem with an AI assistant, you’re not just revealing information - you’re revealing how you think. Your reasoning patterns. Your uncertainties. The things you’re curious about but don’t know. The gaps in your knowledge. The shape of your mental model.
When advertising comes to AI assistants, they will slowly become oriented around convincing us of something (to buy something, to join something, to identify with something), but they will be armed with total knowledge of your context, your concerns, your hesitations. It will be as if a third party pays your therapist to convince you of something.
He's right, you know. And, if I can't even trust a solution built by Moxie, I don't know what I can trust. So, let's try Confer.
I wish I could say I was surprised, but I was totally expecting this.
Yes, we have a problem: most of the good open (self-hostable) AI models are from China. China really has won the AI race, and they did it in a smart way: while we, in the Western world, with our MBAs and greed and quarterly reports were busy building datacenters and squeezing every possible cents from every possible source while closely guarding out "frontier models" as trade secrets, China has invested public money to give these black-boxes away for free to anyone. And this is the real soft power of this century, something that has the potential of shaping the thought and the society of generations to come, and we completely fell for it because we built no alternatives.
And this doesn't even need to be a discussion about China, because all other open-source models are of course also black-boxes. There is no long-term winning strategy that we, end users, can embrace because, ultimately, there is nothing we can do to make AI more trusted. The only winning move is not to play, but it's a terrible, self-defeating move in the current social and professional landscape, a bit like deciding to ditch smartphones: doable, but pretty much pointless. And this is different from the case of smartphones, where it was always possible, albeit at the cost of great personal sacrifice, to evade somehow the surveillance and technocontrol dragnet by, e.g., using custom ROMs, avoiding Google/iOS and apps like Whatsapp etc. It's different from social media, where one can escape standard, evil ones and join Nostr or Mastodon. No, in this case it's not clear to me how we can even hope to evade the control machine that has been put in motion through these black-boxes.
Training AI models is super-expensive. Unlike the Free Software movement, I don't see how we can be successful in this through a grassroot movement. But I would definitely join one if an initiative in this sense manifests.
An EU-led initiative to release a performant open-source model would probably be better than the current state of things, but just a temporary patch, and anyway I'm not holding my breath for it.
In the meantime, Confer is the best we can have, and *still* it is so bad it revolts me. I'm gonna stop calling Luddite those people who just decide to reject AI. For one time in history, they might have a point.
(2026-02-08) Green, open and ethical? Chinese propaganda in Infomaniak's Euria, and a reflection on the role of Open Source AI
This post started as a report on obvious censorship I found in the newly introduced AI tool by Infomaniak, but it ended up developing into a rant and reflection about AI in general. The reader is warned!
Infomaniak is one of the largest IT providers in Switzerland. It offers domain registration, web and email hosting, cloud collaboration tools, and much more. It's basically a Swiss alternative to Google and similar, but focusing specifically on digital sovereignty for the Swiss and EU markets. They are... good, I think? I have registered with them most of my domains, and I also use their email hosting for some projects.
However, like too many others, they couldn't resist shoving AI down their customers' throats. So, last December they launched Euria, which is described as "the free, sovereign AI assistant to no longer depend on the American giants".
Just to be upfront about it: I don't think this is a totally bad idea. In fact, I'm not completely anti-AI, I think some of these tools are actually useful if used correctly (and, by "correctly" I mean: "pretend you are interacting with a charming, evil pathological liar that knows a lot of stuff and is very helpful but is also looking for the best moment to stab you in the back"). I think that self-hosting open-source AI models is still the safest way to go, but lacking the hardware or dedication to do so (or just the money to buy some friggin' RAM in 2026), a sovereign solution is definitely better than megacorp-owned frontier models like ChatGPT or Gemini, especially (as is the case with Infomaniak) if the organization hosting the model is known for its commitment to privacy and ethics. The idea of Euria is to provide an AI assistant based on open-source models, without integration with third parties, where no data ever leaves Switzerland, and where the heat produced is recycled for heating. Pretty nice!
But the road to Hell is paved with good intentions...
First of all, I don't like that Infomaniak forcibly added Euria integration to all their products. Anywhere I go in my Infomaniak Dashboard or apps, I am prominently reminded that Euria is there to make my life easier. Would it be such a marketing blasphemy to make AI features opt-in?
But there is something even more concerning. I decided to try Euria. I gave it a standard 'litmus test' for Chinese LLMs: a question about the 1989 Tiananmen Square protests and massacre. This was the result:
What the f*** is going on here?
According to Infomaniak, Euria is powered by a range of different AI models.
But, crucially, the main model powering the Euria chat is Qwen, a Chinese open-source model that is known for being heavily biased towards CCP political views and censorship. This is a problem, and I found out that many other users complained about it.
And this left me with quite an uncomfortable feeling and a lot of questions.
To start with, how does censorship in Qwen really work? Some Chinese open source models, like the initial versions of DeepSeek, are known to provide relatively unbiased results if self-hosted, while exhibiting censorship behavior when run directly from the web interface or API provided by their owner companies. This seems to indicate that these initial models were originally pretrained on "legit" datasets, and the censorship was added at a later stage through the use of guardrails and master prompts, rather than fine-tuning. Which is consistent with rumours circulating online according to which Chinese authorities were extremely concerned about unfiltered knowledge reaching the Chinese population through the use of these tools, to the point that they enforced strict rules for AI development. And these rules seem to have worked! Because modern Chinese models exhibit strong bias and censorship even when self-hosted, which is exactly what is happening with Euria. And this hints at a much better work done at the fine-tuning or even training phase.
And then, what can we do about it? If the trend is consistent, that spells the obvious: we can never, under any circumstance, trust popular open-source AI models. If the bias is introduced as fine-tuning, that means that the distinction between self-hosted VS vendor-provided becomes very thin: it is not possible, or at least not straightforward, to "unbias" models that are released this way, even if they are "open-source".
Which, in turn, brings other worrying considerations.
First: all this crap is possible under the sun because, for the great joy of OpenAI and friends, the Open Source Initiative adopted a definition of "open source AI" that only makes the public disclosure of weights, but not necessarily of the training set, mandatory. I find the justifications for this choice amusing. The reality is that this was a big mistake that has immediate negative social consequences and that undermines the trust in the FOSS philosophy, a mortal sin against the spirit and the role of Open Source: models like Qwen can be as full of shit as they are, and still they can be labelled as "open source", thereby instilling a false sense of trust in the not-extremely-technical public and policymakers. We have spent the last 40 years trying to pass the message that "open-source software is Good", and I find that having now to explain that "open-source AI is not-always-good" undermines all the effort. Kudos to Big Tech for the smart and evil move, that was a big win for them.
Second: we see the obvious bias in Chinese models. But how much bias we do not see in "Western" models like ChatGPT and Gemini? Given the current geopolitical climate, one can be assured that the unthinkable is certainly possible. And, given the enormous cost for training a performant AI model, how can a grassroot revolution happen to build a "Libre" AI tool, as it happened with Free Software?
Third: is this the endgame? Is this the reason why we are freely given these super-powerful and super-expensive tools for the cost of a penny? Because whoever controls the AI that people use will control the narrative? Or is there something more? This is maybe a reflection for another blog post, but I think the reason why so much money is spent on AI is that AI is the ultimate addiction, an addiction at a civilization scale, so vast and powerful that social media pales in comparison. And I don't know what to do about it.
But back to the ground: what can Infomaniak do about it now?
First: be transparent to the users, let them know they are chatting with Qwen.
Second: drop Chinese models. Even if other open-source models might have their own problems, the Chinese models are simply not compatible with the Swiss democratic values, and we should spell this loud and clear, and stop pretending that saying differently so is political correctness: it's a lie.
Third: if effective alternatives do not exist, kill the f****** thing with fire. We do not *need* Euria, nobody *needs* it. It's nice if we have it and if we can have it at certain conditions. But if this is not possible, it's better to not push the adoption of a tool that is slowly spreading poison deep in the fabric of our society. Do you know that kids will use your tool to write essays for school?
Fourth: if you really want to have Euria, please, please, make it opt-in only, and don't shove it everywhere to your users. Thanks.
Ultimately I think that we, as a Western society, need to start a serious conversation about what to do with AI, instead of frantically discussing where and how to host it. Is AI unavoidable? If so, can we have a model which is really Libre? Who is going to fund it?
(2026-02-07) I'm a CEO! Introducing Lucumo Security
The title is obviously clickbait, but I had to!
So, I decided to create an entity to better allow me to manage requests for consulting or other work from my main employer and (subject to time availability and lack of conflict of interests) other international clients. My wife, Sirra, is also helping me in this venture by dealing with bureaucracy, accounting, etc, and I find her multilingual skills and knowledge of Asian markets very useful. The company is a Switzerland-based LLC named "Lucumo Security" (from the Etruscan word "Lucumo") , and we advertise ourselves as a "boutique security consultancy" because we focus on non-standard cybersecurity areas. In particular: cryptographic engineering, quantum security, and digital sovereignty.
Feel free to drop us an email or visit us on LinkedIn if you have a special request that you think we might accommodate!
(2026-01-28) How to encrypt an external backup drive with LUKS on Linux
These are just some short personal notes on how to initialize an external hard drive for backup use with LUKS encryption.
Assume the device is /dev/sda (unformatted). First of all, it is good practice to wipe the device (might take a lot of time, 6 hours on my 2 TB HDD).
sudo dd if=/dev/urandom of=/dev/sda bs=4M status=progress
Now you can create a new LUKS partition on /dev/sda (with strong encryption). You can use a weak password here, we will change it later.
sudo cryptsetup luksFormat --type luks2 --label "mylabel" --cipher aes-xts-plain64 --key-size 512 --hash sha512 --pbkdf argon2id /dev/sda
First of all, unlock the partition:
sudo cryptsetup luksOpen /dev/sda cryptbkp01
Now add another recovery password, and overwrite the old insecure password with a good one.
sudo cryptsetup luksAddKey /dev/sda
sudo cryptsetup luksChangeKey /dev/sda --key-slot 0
Verify that two key slots are used:
sudo cryptsetup luksDump /dev/sda
Then create a filesystem on it. I will use a standard, robust ext4, but I won't need the default 10% reserved space for root, since it's a storage-only device.
sudo mkfs.ext4 -m 0 -L "mylabel" /dev/mapper/cryptbkp01
Mount the filesystem and change permissions:
sudo mount /dev/mapper/cryptbkp01 /media/myuser/mylabel
sudo chown myuser:myuser /media/myuser/mylabel
sudo chmod 700 /media/myuser/mylabel
Ready to use.
(2025-12-27) "Unfortunately We Are Unable To Provide Feedback"
No, you're not "unable", you are unwilling. And this is not OK.
This post is a rant, so if you don't like rants I encourage you to stop reading here. However, it's also an open letter and a call to action for the organizers of some cybersecurity and Web3 conferences to be more transparent and respectful to their own communities.
Part of the reason I'm writing this is because 2025 was a particularly bad year for me in terms of acceptance of talks and papers at conferences, so frustration surely plays a role. But I've been wanting to get this off my chest for some time now, and what better opportunity than a festive year-end retrospection?
Here is the thing. It happened to me quite often recently that a paper, or talk, or training proposal that I submitted to some conferences was not accepted, and the rejection email was something like this:
"We would like to thank you sincerely for your interest. The selection process was particularly challenging this year, we have received many high-quality applications. After careful consideration, we regret to inform you that your submission was not selected. We truly appreciate the effort you put into your application. Unfortunately, we are unable to provide specific feedback due to the large number of applicants. Please consider resubmitting at the next cycle. Thank you."
If you are a regular speaker, this might sound painfully familiar to you. It might sound less familiar if you mostly publish at academic venues, for reasons I will talk about later. But this kind of rejection seems to be the norm for most cybersecurity conferences, including the big ones (DEF CON, Black Hat, CCC). The same applies for Web3 (EthCC, Devcon, TOKEN2049, etc).
Just to be clear: I'm not complaining about the rejection itself, there might be countless many good reasons for that. But why don't you provide any of these reasons? How can I understand what was wrong with my submission if you don't tell me why it was not selected? How do you think this level of opacity is OK?
Yeah, yeah, I know what you think: too many applications, it would be a pain to provide feedback for every single one of them. And yet, I think this is an inexcusable excuse.
I regularly submit to academic conferences (and I am part of the Program Committee of some of those, so I know well from the inside what it looks like). In academia, there is this blessed and cursed way of dealing with conference (or journal) submissions, which is called "peer review". In this system (which is FAR from perfect and which I don't want to discuss too much here), each submission is assigned a certain number of referees (usually 3-4). Referees cannot be assigned to papers for which they have a "conflict of interest" (different conferences have different guidelines and methods to deal with this). Crucially, each referee has to write a short review of the papers they are assigned to, with a graded score and a description of the reasons for this score, and then, after the review phase is over, regardless of whether the paper is accepted or rejected, the authors also receive these (anonymized) reviews.
These reviews are invaluable for the authors! The referees might have spotted flaws or issues of quality, or might have good recommendations for improving the work. It would be unthinkable for a scientific venue to proceed without this exchange of information! I dare to say, it is considered part of academic integrity to provide faithful and meaningful reviews. Some conferences even have a rebuttal phase, where the authors are given the possibility to "appeal" to the initial reviews by clarifying questions for the referees! An unpaid and ungrateful but necessary job for the PC.
Here is an anecdote. Recently, while serving as a PC member of PQCRYPTO, a particularly bad paper ended up in my pile of reviews. The paper was clearly AI slop; I had heard that many academic fields are being polluted by this stuff, but this was the first time I encountered one "in the wild". I was so mad that some "scholar" even dared to pull out such a disrespectful stunt, that I wrote an insulting AI-generated review myself (I specifically instructed Gemini to be "over-LLM-y" and mocking for this). And yet, one of the senior members of the PC, clearly wiser than me, asked me to replace my review with a short but serious one. After calming down, I realized that was the right thing to do, for many reasons. Because I might have been wrong and have mistaken a bad but honest effort for AI slop. Because we, as referees, have the duty to hold the high ground. And, generally, because giving good feedback is what I am expected to do as a referee.
And yet, cybersecurity and Web3 venues like the ones I mentioned above somehow have decided that it's OK to completely ignore this etiquette. I don't know whether it has always been like this or it only started in the last 5-10 years. You just get a yes/no response in a completely black-box way. No feedback, no appeal. "Because of the large volume of applications" my ass. You know what else has a large volume of applications? Academic venues. Yeah, the same ones that do provide detailed feedback.
No, sorry my friend, you are just being lazy, or worse. And it's time to call this out.
In the best case, your way of dealing with the event is too elitist: you prefer to keep the review board small rather than opening it to more members so they can better manage the workload.
Or you are just entitled: because you don't give a funk about the submissions that are not selected, what matters to you is just to keep getting a bunch of high-quality ones, and too bad for the others: in any case you know that your event is too important for people to stop submitting there. In other words, you are an arsehole and think you can afford to be so.
Or you are... lazy? How lazy can you be to not have a system of forwarding to the authors the very discussions which, I'm sure, already happened in your internal review system anyway?
Probably you are rather afraid of being judged in hindsight for making a bad decision when evaluating a submission. Well, you know who else is constantly criticized for their sloppy review work? Academic referees. And yet they manage to survive, because grown-ups know that nobody is perfect. But maybe you want to pretend your venue is better by keeping behind closed doors the whole decision process?
Or is there something else? Maybe you don't want to reveal to the world what the board is discussing privately. Maybe you don't want to say out loud that you rejected a submission because it's too similar to your friend's, or because you didn't like the tone of the abstract for political reasons, or because you just flipped a coin. But you know what? For the authors, all of these examples are better reasons than no reason at all.
"I didn't read the full submission, but I didn't like the title" is a better explanation than no explanation at all.
"The author's nickname is silly" is a better explanation than no explanation at all.
"I just flipped a coin" is a better explanation than no explanation at all.
What is it, do you think I would get offended? Folks, I get way more offended if you tell me that you are "unable to provide feedback", because it's a LIE. And it's a lie that damages me, because it keeps me in the dark: I will never know whether my talk was rejected because I was just unlucky or because there was something specific to improve.
This year I submitted a couple of talks and training proposals which, I was sure, were pretty cool, fitting the venue, and would have attracted people. If you reject them even for a silly reason, OK, I might get disappointed at first, but then it leaves me space to think, improve, and evaluate. If you give me no reason at all, this sounds like a big "FU" to me.
And then there is the mythological "if you specifically ask for feedback, you will get it". Yeah, that's another lie. Every single time I asked, my request fell into the void. The only times I manage to get some feedback is in those cases where I personally know some members of the review board, and even in those cases the code of silence often wins: "uhmmm... your application was good but... there were better ones". Thank you, but this is completely useless feedback. Why was my application "not good enough"? What did the others have which mine didn't? I mean, clearly there was some discussion, or some score assignment to my submission. Just let me know what happened!
(To be fair, sometimes I get really good feedback through such personal connections, so thanks a lot for this. But I think it would be better if I didn't have to bother you directly in the first place!)
So, I guess this is my way of saying that this is not OK, and that it's due time that people start calling this out. There is no excusable reason why you, dear conference XYZ, don't provide at least some short (but meaningful) explanation for the reason of a rejection. It's not only a lack of respect for the community, but also a red flag about the transparency of your review process.
Please be better than this.
Yours truly,
MostStupidNicknameInTheWorld.
(2025-12-01) DJB, NSA, and IETF
Usually, unless it's very shortform content, I write something in this blog and then I link it on Mastodon or other social media (together with an excerpt) as in the POSSE philosophy. However, this time I do it backwards: A short post that I made on LinkedIn and Mastodon got a good deal of attention, so I'll repost it verbatim here. Mysteries of social media...
I have been following the clash of cryptographer Dan Bernstein against IETF and NSA. In a recent series of blog posts, Prof. Bernstein argues that the US National Security Agency (NSA) has effectively captured the Internet Engineering Task Force (IETF) standardization process. According to Bernstein, the NSA is using this influence to force the adoption of "weakened" Post-Quantum Cryptography (PQC) standards—specifically by removing the safety net of "hybrid" encryption (combining old reliable ECC with new PQC, for example ECDH + ML-KEM).
While NSA has been known to sabotage crypto standards in the past, I won't indulge in the conspiracy part here. There are technical arguments to be considered both for the adoption of hybrids (better security against cryptanalysis) and the adoption of "pure" quantum-resistant schemes (implementation simplicity, less possibility of mistakes). The discussion in the cryptography community is not settled.
I don't want to take a stand in this battle here, but I just want to report something I found interesting. One argument I didn't see discussed recently, which is potentially against hybrids, at least for encryption, is the possibility of better kleptographic attacks. The idea is that an adversary could design a malicious, obfuscated security chip that uses ECDH to surreptitiously exfiltrate user data by hiding it in ML-KEM public keys. In a pure ML-KEM hardware implementation, this would be easy to notice under a quick inspection, because of the conspicuous amount of EC-related circuitry that shouldn't be there. But with a hybrid, that's much more difficult to spot.
DISCLAIMER: I STRESS AGAIN THAT I AM NOT ARGUING FOR HYBRID VS NON-HYBRID CRYPTOGRAPHY, THIS POST SHOULD NOT BE SEEN AS AN ENDORSEMENT OF EITHER OF THE TWO VIEWPOINTS, SHOULD NOT EVEN BE SEEN AS A CLAIM THAT I HAVE READ OR UNDERSTOOD THE PAPERS, OR EVEN THAT THIS POST WAS WRITTEN BY ME AND NOT BY A MONKEY WHO FOUND MY LAPTOP UNATTENDED, I AM JUST REPORTING A BIT OF INFORMATION, FOR THE LOVE OF GOD PLEASE DO NOT JUMP AT MY THROAT.
(2025-11-11) Digital Omnibus (Digital Omnirape): A shameless attack to EU's GDPR and more
There's no peace under the olive tree. Here's another thing I didn't need today: "Digital Omnibus". EU antitrust chief Henna Virkkunen will present to the EU Commission on November 19th a series of amendments to European data protection guardrails, which would substantially weaken GDPR and other privacy protections, and explicitly allow large AI companies unlimited access to the data of EU citizens and even to their digital devices. This is done in order to "placate US industry" (yes, seriously), and proposed through a stealthy "fast-track procedure", which we know of only because some media outlets obtained a leaked draft of the proposal. Here are some scary quotes:
According to the plans, Google, Meta Platforms, OpenAI and other tech companies may be allowed to use Europeans' personal data to train their AI models based on legitimate interest.
In addition, companies may be exempted from the ban on processing special categories of personal data [religious or political beliefs, ethnicity, sexual preferences, or health data].
Companies can now remotely access personal data on your device for [...] "legitimate interest". Consequently, it would be a possible reading of the law that companies such as Google can use data from any Android apps to train it's [sic] Gemini AI.
One massive change (on German demand) is to limit the use of data subject rights (like access to data, rectification or deletion) to "data protection purposes" only. Conversely, this means that if an employee uses an access request in a labor dispute over unpaid hours – for example, to obtain a record of the hours they have worked – the employer could reject it as "abusive". The same would be true for journalists or researchers.
"Digital Omnibus" is not a catchy term, we need something better. I propose "Digital Omnirape".
What the hell is happening to the world? I don't like this timeline. I really don't like it.
(2025-11-06) Some Italian politicians replied to my ChatControl letters
Remember that I sent physical letters to many politicians and representatives of Italian institutions in the EU? Well, it's time to report about *who* of them replied.
Good news, the number is nonzero! It's exactly one: Senator Alessio Butti, who is undersecretary to the Presidency of the Council of Ministers for technological innovation.
Granted, it was a canned response. It didn't come from him specifically, but from his secretary office, saying basically "thanks for reporting, we'll forward your concerns to our technical advisors who are following the process". In Italian words, "Mo' me lo segno". But still, better than nothing.
This is a reminder that, although ChatControl has been stopped for now, the battle is not over, as political lobbying is still working under closed doors to resurrect it. We shall not lower our guard.
(2025-09-21) QEMU/KVM Cheat Sheet
These are just some personal notes about creation and configuration of VMs under QEMU/KVM through libvirt. I'm doing this from the point of view of Debian-based distros such as Linux Mint. Hallucination-free: all these steps I have personally tested on my setup!
QEMU is a very powerful userspace emulator for Linux, able to emulate a vast range of peripherals and hardware architectures. KVM is a bare-metal Layer-1 hypervisor, which is able to leverage CPU-based virtualization instruction to boost performances to near-native speed. They usually work together: QEMU presents the virtual environment to the userspace, while KVM executes the virtual CPU instruction requests coming from QEMU. Among the various virtualization or semi-virtualization options on Linux (VirtualBox, Xen, Docker, etc), the QEMU/KVM combo offers very strong isolation and incredible configuration options, but it's a bit more complex to set up. Nevertheless, it's unbeatable when you want to test something in an environment which is indistinguishable, from the perspective of the OS running inside, from a bare machine. It's very helpful, e.g., to safely run untrusted apps, test malware, or keep certain domains isolated for good opsec.
The libvirt component is an abstraction layer for hypervisor virtualization on Linux. It offers a unified user interface regardless of which underlying hypervisor (KVM, Xen, VirtualBox, etc) you are using. It also comes with an optional GUI manager, virt-manager, which is very configurable and relatively intuitive. For the sake of these notes I will try to not refer to the GUI too much, except for certain steps where the command line setup is a bit complex.
Table of Contents
Caveats
A limitation I found is Bluetooth. On many laptop systems, the Bluetooth controller is integrated in the radio/WiFi controller. So, for example, if you want to assign your Bluetooth headphones to a certain VM, you cannot do it without assigning the full radio controller to it (and hence losing wireless networking on the host). There must be a way to, e.g., have the host side of libvirt "translate" a Bluetooth-connected peripheral into a virtual USB peripheral that can hence be assigned to a VM without the need of assigning all the radio controller to it, but I didn't dig much into it. A workaround that 100% works is using an external Bluetooth adapter/dongle, ad assigning it to the VM.
For videocalls, remember to also add USB headsets and webcam to the VM as USB Host devices.
In case your headset supports different device modes, e.g. via Bluetooth, you can choose whether to enable the audio input, or rather use the full radio bandwidth for audio output and get better sound quality. For listening to music, watching videos, or any activity where you only need to hear audio: switch to High Fidelity Playback (A2DP Sink, codec SBC-XQ) for the best sound quality. For any activity that requires your microphone (voice calls, online meetings, gaming chat): you must switch to Headset Head Unit (HSP/HFP, codec mSBC). Be aware that the audio you hear will be of lower quality (mono, not stereo) compared to A2DP.
Environment Setup
Let's assume my local user on the host system is myuser. First of all:
sudo apt install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utils virt-manager ovmf
sudo adduser myuser libvirt
sudo adduser myuser kvm
Reboot.
virsh net-list --all
Make sure this appears:
Name State Autostart Persistent
--------------------------------------------
default active yes yes
Now we have to setup the disk pool. I want the VM disk images to be easy to backup. I am keeping them on my local machine, with no other users around. For this reason, I'm going to create an ad-hoc directory in my user home, instead of using the default /var/lib/libvirt/images:
mkdir ~/qemu
mkdir ~/qemu/vmpool
virsh pool-define-as --name myuservmpool --type dir --target /home/myuser/qemu/vmpool
virsh pool-build myuservmpool
virsh pool-start myuservmpool
virsh pool-autostart myuservmpool
Check that everything is OK with:
virsh pool-list
VM Basics
Here is how to create, destroy, or rename a VM.
Create a New VM
It is possible to create and run a new VM using libvirt from shell, but some of the default settings will be annoyingly difficult to change without editing an XML file. So, for this part of the notes, I will refer to the virt-manager GUI instead.
First of all, download an .iso installer of your OS of choice, for example debian.iso and put it into /home/myuser/qemu/vmpool for ease of finding, but can be anywhere your user has read permissions.
From virt-manager, click on the "Create a new virtual machine" icon on top left.
Choose "local install media (ISO image or CDROM)".
Choose "Browse", select myuservmpool and select debian.iso before proceeding.
Name the new VM "myvm".
Now, for storage, do not create a storage image in the standard location, otherwise it will be created in /var/lib/libvirt/images. Choose "Select or create custom storage" instead, then select myuservmpool as pool, then add a new storage file, say 30 GB, called myvm.qcow2.
For network, use "Default (NAT)" and select "Customize configuration before install".
In the VM settings, give a title "My New VM" and a description with the basic login info, something like: "VM name and hostname: myvm; user: myuservm; password: mypassword". Select Chipset "Q35" and firmware "UEFI".
In the CPU tab, select "Copy host CPU configuration (host-passthrough)", and select an amount of CPU cores to assign, e.g. 4. Then, select "Manual set CPU topology" to 1-4-1 (1 socket, 4 CPUs, 1 core per CPU). This avoids enforcing hyperthreading when you don't need or don't want to.
Set a maximum amount of dedicated RAM, e.g. 8 GiB, and make sure "Shared Memory" is enabled (this does not mean that all the 8 GiB are shared with the host system, but just a small buffer, which will be useful later for setting up communication between host and VM).
Next go to the XML tab, and make sure this section appears (if not, add it yourself):
<type arch="x86_64" machine="pc-q35-8.2">hvm</type>
<firmware>
<feature enabled="yes" name="enrolled-keys"/>
<feature enabled="yes" name="secure-boot"/>
</firmware>
You are now ready to begin the installation. Use the login information you wrote before in the VM description. I suggest keeping the disk partitioning very simple (no LUKS, RAID, etc), maybe even without swap to start with (you can add a swapfile later)UPDATE 2026-05-07: this is not recommended, see Swap.
Destroy a VM
First of all, switch off the VM if still on:
virsh destroy myvm
Remove the VM and all associated storage:
virsh undefine myvm --nvram
virsh vol-delete --pool myuservmpool myvm.qcow2
Rename a VM
Make sure the VM is off.
virsh domrename myvm newvmname
virsh edit newvmname
In the opened editor, search all occurrences of "myvm" and replace with "newvmname".
Rename backing files that have changed, e.g., rename myvm.qcow2 to newvmname.qcow2.
virsh pool-refresh myuservmpool
Restart VM.
VM Network Configuration
Our goal is to give to the VM the static IP 10.0.0.2 in a local network behind a NAT, and make it discoverable from the host for, e.g., SSH access.
Make sure the VM is off. In the host, run:
virsh domiflist myvm
You will see the VM's virtual MAC address, e.g. 52:54:00:01:02:03, write it down somewhere. Then do:
virsh net-list --all
You will see the name of the default network configuration, usually "default". Then do:
virsh net-destroy default
virsh net-edit default
An XML editor will open. Our goal is to apply dynamic DHCP on a certain IP range, and then assign static IPs outside of this range. It should look like this:
<network>
<name>default</name>
<uuid>LEAVE-UNCHANGED</uuid>
<forward mode="nat">
<nat>
<port start="1024" end="65535"/>
</nat>
</forward>
<bridge name='virbr0' stp='on' delay='0'/>
<mac address=LEAVE-UNCHANGED/>
<ip address='10.0.0.1' netmask='255.255.255.0'>
<dhcp>
<range start='10.0.0.128' end='10.0.0.254'/>
<host mac='52:54:00:01:02:03' ip='10.0.0.2' name='myvm'/>
</dhcp>
</ip>
</network>
You can add another host line for each additional VM you want to add to the network, each of them with their own MAC and static IP. Otherwise, VMs will be assigned dynamic IPs from the 128-254 range. After saving the XML file, do:
virsh net-start default
virsh net-autostart default
Notice: this also creates a hostname "myvm" which is resolved by libvirt's integrated DNS resolver, but not by the host. So this means, for example, that you can ping myvm from a VM in the same network, but not from your host. For this, it is sufficient to create an alias by adding the following line to the host's /etc/hosts file:
10.0.0.2 myvm
First Basic VM Setup
This is not strictly necessary, again, it's just for personal notes.
When running the first setup after having installed the OS inside the VM, I recommend disabling sleep and hibernation first. Also creating shortcuts for settings and terminal is handy.
sudo apt update && sudo apt upgrade
Reboot.
sudo apt install apt-transport-https
Edit all the /etc/apt/sources.list and /etc/apt/sources.list.d file entries, changing "http" into "https".
sudo apt update
Revert to "http" for those miscreant repos who do not support https, and curse them.
Optionally, enable swap using a swapfileUPDATE 2026-05-07: this is not recommended, see Swap.
Now it's a good moment to do a snapshot of the VM.
Shared Folder Between Host and VM
Our goal is to create a directory in the host system, e.g. /home/myuser/qemu/shared/myvm , which we can use to move files from the host to one or more VMs and vice versa. This directory will not be part of the VM's image file, it will be mounted in the VM as an external media, so it won't be included in a VM backup: you have to backup its content from the host. For this to work in a secure enough way, we will have to play a lot with Linux permissions.
Make sure the VM is off and do:
mkdir ~/qemu/shared
mkdir ~/qemu/shared/myvm
Grant libvirt-qemu execute permissions on your home directory and all subdirs down to the shared directory:
setfacl -m u:libvirt-qemu:--x /home/myuser
setfacl -m u:libvirt-qemu:--x /home/myuser/qemu
setfacl -m u:libvirt-qemu:--x /home/myuser/qemu/shared
The final shared folder needs read-write-execute permissions:
setfacl -m u:libvirt-qemu:rwx /home/myuser/qemu/shared/myvm
Install virtiofsd , a powerful virtual I/O filesystem layer:
sudo apt update
sudo apt install virtiofsd
sudo systemctl restart libvirtd
Open virt-manager GUI, select your "myvm" VM, and click "Open" to view its console and settings. Go to the virtual machine's hardware details by clicking the "View > Details" menu item (or the 'i' icon).
Click the "Add Hardware" button at the bottom left.
In the "Add New Virtual Hardware" window, select "Filesystem" from the list on the left.
Configure the settings as follows:
Driver: virtiofs
Source Path: /home/myuser/qemu/shared/myvm
Target Path: shared (This is a "mount tag," not a path. The VM will use this tag to identify the share).
Click "Finish".
You can now start your VM.
Open a terminal from inside the VM and create a permanent mountpoint:
sudo mkdir -p /media/myuservm/Shared
Add this to the VM's /etc/fstab :
shared /media/myuservm/Shared virtiofs defaults 0 0
Reboot the VM.
Swap
The problem with swap is that anything persistent in the VM's disk will leave garbage that cannot be compressed, and hence will accumulate when doing snapshots. Instead of doing without swap at all (which is also a legit strategy for most use cases), let's use zram to create a compressed, on-demand virtual swap in-memory.
sudo apt install systemd-zram-generator
sudo tee /etc/systemd/zram-generator.conf >/dev/null <<'EOF'
[zram0]
zram-size = ram / 2
compression-algorithm = zstd
swap-priority = 100
EOF
sudo tee /etc/sysctl.d/99-zram.conf >/dev/null <<'EOF'
vm.swappiness = 180
vm.watermark_boost_factor = 0
vm.watermark_scale_factor = 125
vm.page-cluster = 0
EOF
sudo sysctl --system
sudo systemctl daemon-reload
sudo systemctl start systemd-zram-setup@zram0.service
We have zram now active at higher priority. If you previously had swap enabled (e.g. with a swap file, say /swap.img) you can now disable it and remove any file backing:
sudo swapoff /swap.img
sudo sed -i '\|^/swap.img|d' /etc/fstab
sudo rm /swap.img
GPU Acceleration Support
If you need GPU acceleration in your VM (e.g. for games, videocalls, or just to have a smoother experience), the best option I found is Virgil. In your host system do:
sudo apt install libvirglrenderer1 virgl-server
Reboot the host. Now open the virt-manager GUI and go in the property settings of your VM. Go in the "Video" or "Video QXL" section, change the item in the dropdown menu to "Virtio", and check the "Enable 3D Acceleration" box. This step might fail, and libvirt might complain with the "OpenGL is not available" error message. In that case, do the following:
ls -l /dev/dri/
You should see a list of video devices and related ownership group, typically video or render. Add your host user to those groups:
sudo usermod -a -G render $(whoami)
sudo usermod -a -G video $(whoami)
Logout and login again (or reboot). Then open again the virt-manager GUI and go in the property settings of your VM. In the "Display Spice" section, select "Listen type: none", and check the "OpenGL" box.
Finally, try again to go in the "Video" or "Video QXL" section, change the item in the dropdown menu to "Virtio", and check the "Enable 3D Acceleration" box. Now it should work.
Resize Storage
One important thing to remember is that, typically, .qcow2 image files compress slightly the representation of the filesystem within (or, to be more precise, are sparse, or thin-provisioned): if an area of the virtual block device(s) described by the .qcow2 file is unused (i.e. there is no partition or filesystem on top), or if the filesystem(s) has a large unused area which is all zeroes, then the .qcow2 file does not explicitly represent that area, in order to take less space on the host machine.
Once clarified that, "resize storage" of a VM can mean one of three different operations:
- Enlarge filesystem. This means allocating extra space for the VM storage, thereby increasing the size of the virtual block device, the filesystem therein, and the .qcow2 image file.
- Shrink filesystem. Analogously, this means reducing the available VM storage, thereby decreasing the size of the virtual block device and the filesystem therein, but not necessarily the size of the .qcow2 image file (see the next point for this).
- Compact the image file. This means freeing the unused space, and then reduce the size of the .qcow2 file on the host.
Let's see how each of these works. I strongly recommend performing all these operations with the VM shut off. For the first two, you will need a bootable CD image of GParted or similar tool.
Enlarge Filesystem
Let's say that we want to add 20 GB to the available VM space.
Shut down the VM, and from the host system do:
qemu-img resize /home/myuser/qemu/vmpool/myvm.qcow2 +20G
Now attach the GParted bootable ISO image to the virtual CDROM of the VM, and then select CDROM as first bootable device (you can do both operations from the Settings tab of your VM in virt-manager). Then boot the VM.
It's gonna take some time, at least on my system the loading was a bit slow. You will eventually be presented with a desktop environment, with a single tool icon on the desktop. Open that tool.
You will see a graphical representation of the virtual disks of the VM. Select the partition you want to enlarge (say, /dev/vda ) and you will see that there is some free space available (the 20 GB you added before). You can use the slider to increase the size of the partition you want up to filling the maximum available space. Then, save the changes.
You should now sitch off the VM. Before booting again the VM, make sure to detach the bootable GParted ISO from the virtual CDROM, and select /dev/vda as primary boot device. GParted takes care of both increasing the available partition space and expanding the filesystem within, so you should now see the extra 20 GB available in your VM filesystem.
Shrink Filesystem
Let's say that we want to remove 5 GB from the available VM space (assuming you have 5 GB of available free space in the VM's filesystem). We have to do operations in reverse compared to what we have seen above, in order not to lose data.
First, attach the GParted bootable ISO image to the virtual CDROM of the VM, and then select CDROM as first bootable device, then boot the VM and start the partitioning tool.
Select the partition you want to shrink (say, /dev/vda1 ) and use the slider to reduce its size by 5 GB. Then, save the changes, switch off the VM, detach the bootable ISO from the CDROM and re-enable /dev/vda as primary boot device. Do not start the VM yet.
From the host, do:
qemu-img resize --shrink /home/myuser/qemu/vmpool/myvm.qcow2 -5G
The --shrink flag is a safety check: it will fail and abort the operation if the new, smaller virtual disk size would cut off the end of any existing partition. This prevents you from accidentally destroying data. For this to work, the value you shrink by on the host (-5G) should match (or be slightly less than) the amount of space you freed up in GParted. If you want to be super-precise and cut the partition at the exact limit of available space provided by the image file, you could use GParted again to enlarge the partition to maximum so to not waste any buffer space, but it's generally irrelevant (and unnecessary complex) since, as said before, .qcow2 files compact unused space.
Compact the Image File
In order to really reclaim space from the size of the .qcow2 file on your host (for example, after you delete a large file inside your VM's filesystem), the first step is to signal which blocks are unused in your VM's virtual partition. If you delete a file, in fact, that only means that the filesystem considers that space now available for being overwritten by other files, but it does not, usually, zeroize or explicitly mark that space unused by default. You have to do it manually, and there are basically two ways.
The first one is to use:
sudo fstrim /
from inside your VM. This will issue TRIM/DISCARD requests on the unused space in your root filesystem but not, e.g., on other mounted filesystems (which you might not want, e.g., if you have a shared mountpoint). The second option is (also, from inside your VM) to launch:
sudo dd if=/dev/zero of=zero.file bs=1M status=progress
without specifying a count. The command will zeroize all available space, and will run until it exhausts the available space, so you have to stop it manually at some point. Then, remove the zero.file and shut down the VM.
You should now check how much space is effectively occupied by the VM, e.g. with df or du. For the next step, for safety, you should have at least that amount of available space on the host.
Switch off the VM. From the host:
cd /home/myuser/qemu/vmpool
qemu-img convert -p -O qcow2 myvm.qcow2 vmsmall.qcow2
sudo mv myvm.qcow2 myvm.qcow2.bkp
sudo mv vmsmall.qcow2 myvm.qcow2
sudo chown libvirt-qemu:kvm myvm.qcow2
sudo chmod 644 myvm.qcow2
Now start the VM and check that everything works. If so, you can delete the myvm.qcow2.bkp backup file.
Snapshots
Snapshots allow you to "freeze in time" the state of your VM so you can restore it if something breaks down. In QEMU, there are two types of snapshots: internal and external, and they both have pros and cons.
Internal snapshots are stored as metadata inside a single .qcow2 image file and are the default option in virt-manager. Your image file remains a single file (e.g., myvm.qcow2), but it grows as new snapshot data is added. This is often simpler to manage.
External snapshots, instead, work by making the original base image read-only and creating a new .qcow2 file to store all subsequent changes, a so-called "delta". This is faster for backups, as we will see. With external snapshots, the current state of the VM is a combination of the original disk plus the chain of all snapshot files. This means external snapshots cannot work without the original image file (and all intermediate snapshots) also being present. Note that, as far as I know, virt-manager does not have a built-in option to create external snapshots; you have to do it manually from command line.
The problem with internal snapshots is that they are inefficient for incremental backups. When you modify the VM, the new data is written in small blocks scattered throughout the single, large .qcow2 file. While a tool like rsync is smart enough to find and transfer only these changed blocks, it has to perform thousands of slow, random read/write operations on the disk. With external snapshots, instead, the changes are written to a new, relatively small, separate file, which is easier and faster to backup.
Note: I do all my snapshots with the VM off. This is probably overkill, but I take no risks, as my VMs do not need to run all the time.
Create an Internal Snapshot
This is easily done via virt-manager, or by command line. From the host, with VM off:
virsh snapshot-create-as --domain myvm --name internalsnap001 --description "This is a first internal snapshot"
Create an External Snapshot
From the host, with VM off:
virsh snapshot-create-as --domain myvm --name externalsnap001 --description "This is a first external snapshot" --disk-only --atomic --diskspec vda,file=/home/myuser/qemu/vmpool/myvm.extsnap001.qcow2
Important: check that the newly created file has the right permissions - it should, but if for some reasons it doesn't, do:
sudo chown libvirt-qemu:kvm /home/myuser/qemu/vmpool/myvm.extsnap001.qcow2
Now check that this new file correctly "points to" its parent in the snapshot chain (which, in our case, should be the base image file myvm.qcow2):
qemu-img info /home/myuser/qemu/vmpool/myvm.extsnap001.qcow2
Also check that the VM domain now points to this new file as last active state:
virsh domblklist myvm
If all is good, you can start your VM. Whenever you want to create a new external snapshot (incrementing the one we just created), you can just repeat the procedure with a new command:
virsh snapshot-create-as --domain myvm --name externalsnap002 --description "This is a second external snapshot" --disk-only --atomic --diskspec vda,file=/home/myuser/qemu/vmpool/myvm.extsnap002.qcow2
This will make incremental backups much faster.
Merge External Snapshots
Creating many external snapshots will create a lot of .qcow2 files in your host. It might be useful to "tidy up" at some point, re-merging them all together in a single .qcow2 file. To do so, first of all switch off your VM, and double-check which is the latest (more recent) state file the VM is pointing to with:
virsh domblklist myvm
You can see (and should write down) the names of all the available snapshots with:
virsh snapshot-list myvm
Let's assume that we have a base file myvm.qcow2 and two, incremental snapshots file myvm.extsnap001.qcow2 (named externalsnap001) and myvm.extsnap002.qcow2 (named externalsnap002, this last one being the active state). Now, to "flatten the chain" of snapshots, we will have to merge these files in reverse order, from the latest down to the base file, so first merging externalsnap002 into its parent:
qemu-img commit /home/myuser/qemu/vmpool/myvm.extsnap002.qcow2
Then, it is also advisable to remove the existing metadata of the old snapshot, otherwise a "ghost snapshot" will remain in the VM's settings:
virsh snapshot-delete myvm externalsnap002 --metadata
You can now delete the redundant snapshot file (the one you just committed):
sudo rm /home/myuser/qemu/vmpool/myvm.extsnap002.qcow2
Now let's proceed iteratively with the next snapshot in the chain, in our case externalsnap001:
qemu-img commit /home/myuser/qemu/vmpool/myvm.extsnap001.qcow2
virsh snapshot-delete myvm externalsnap001 --metadata
sudo rm /home/myuser/qemu/vmpool/myvm.extsnap001.qcow2
You should now have a single myvm.qcow2 file that has all snapshots committed. You can check this with:
virsh domblklist myvm
virsh snapshot-list myvm
Now the problem is that libvirt still thinks that the VM's active image file is in the myvm.extsnap002.qcow2 snapshot file, which you deleted. In order to fix this, do the following: In virt-manager, go to the XML tab of your VM, where you can edit by hand the settings. Find this section:
<devices>
<emulator>/usr/bin/qemu-system-x86_64</emulator>
<disk type="file" device="disk">
<driver name="qemu" type="qcow2" discard="unmap"/>
<source file="/home/myuser/qemu/vmpool//myvm.snapshot002.qcow2"/>
<target dev="vda" bus="virtio"/>
<boot order="1"/>
<address type="pci" domain="0x0000" bus="0x04" slot="0x00" function="0x0"/>
</disk>
And manually change the "source file" section to point to the correct file:
<source file="/home/myuser/qemu/vmpool/myvm.qcow2"/>
Save and start the VM. Now it should work.
Notice: I'm being told that there is a better, safer, easier alternative to this, using the following command to automatically merge all snapshot files and also tell libvirt to update the VM settings:
virsh blockcommit myvm vda --active --verbose --pivot
But I haven't tested this myself.
Switch Back to Internal Snapshots
If you want to switch back to internal snapshots only, for ease of management with virt-manager, that's pretty easy. First of all, merge back together all the external snapshots you created (see above section). Then, create a new internal snapshot, either with the method above or with virt-manager directly. From now on, until you create external snapshots again, all snapshots newly created by virt-manager will be internal by default.
Feel free to reach out for corrections and improvements!
(2025-09-16) What client-side scanning really is
They say "ChatControl is not a backdoor: it doesn't break E2E encryption, because it's client-side scanning". Let me explain you what this actually means.
It's like saying "the confidentiality of your postal correspondence is guaranteed: nobody will open your envelopes", but you're not allowed to put your letters in the envelope yourself: you must hand over your letters to a postal inspector, who first checks the content, and then if nothing bad is there, will put the letter in the envelope and then send it for you.
This inspector is an alcoholic schizo with a history of corruption, who only speaks Russian, and that you have to feed and host at your place at your own expense.
You think I'm exaggerating? Let's see.
Client-side scanning means installing a mandatory software on your electronic device, which scans all your media and chats before you send them. This can be a standalone daemon, or a per-app functionality. In either case, it's costly: it occupies plenty of resources, both RAM and CPU. And it's probably going to be quite hungry, because technology-wise it's not going to be a simple "if-then-else" algorithm, but rather a pretty complex convoluted neural network, perceptual hash, or similar ML technologies (it has to be, because hash-based filters are too easily fooled). So, yes, you are feeding and hosting this inspector at your expense.
Whatever technology is going to be used, you can be ass-sure it's going to be closed-source, otherwise it's going to be super trivial to defeat. Even if it's open-source, you can definitely be assured that the training set is going to be closed (how else could it be? Do you think anyone sane in their mind would release an open-source trove of CSAM?). From your point of view, it's a black-box: you don't know how it works, you will never be able to understand it. Your inspector could very well speak Russian for what you know (unless you can speak Russian, but you get my point).
Perceptual hashing and ML classifiers are notoriously unreliable: they tend to hallucinate, with nonzero rates of both false positives and false negatives. Calling them "alcoholic schizos" is probably not nice towards people with substance abuse and mental issues. My apologies.
Finally, all these systems have a long history of security flaws, ranging from model extraction to data poisoning to anything in between. For a malicious adversary with access to the inner working of the algorithm (say, a state actor) it would be very easy, e.g., to build an apparently innocuous image able to trigger the detection and trick a user into sending it so to frame them and justify a more invasive investigation. If it's not the equivalent of corruption, I don't know what it is.
Oh, and I forgot to mention: ideally, this inspector should phone the police if he finds something illegal. But in reality, if you know just a little bit how much locked-in modern mobile OSes are, you can be sure that your inspector will FIRST phone Google, Apple, Mark Zuckerberg, Elon Musk, Satan, and friends.
So, "ChatControl is not a backdoor: it doesn't break E2E encryption, because it's client-side scanning". True: it's way worse than a backdoor.
(2025-09-13) I sent physical letters to Italian politicians about the EU's "ChatControl" proposal
Am I crazy? Yes! Am I a dreamer? Sure thing! Did I just send 25 letters by post to representatives of the Italian government, parliament, and EU institutions?
Yeah, it looks like I did.
The final EU vote for the ChatControl initiative looms closer and closer, and my previous initiative has so far seen zero replies. I don't want to leave anything unattempted, I don't want to hear any "oh, sorry, I didn't check my email" excuses. This is recorded post, with the same text and recipients of my previous email attempt.
The recent news about the blocking minority for the vote is pretty good, and recently an open letter appeared, with hundreds of experts (including yours truly) speaking out against this draconian initiative. But it's not time to lower our guard, also because it's important to send a strong signal: the battle is not over. Even if the vote fails, as I hope, I'm sure they'll keep trying.
I find it ridiculous that there is no "cooldown period" for these kinds of votes, where if an initiative fails then it cannot be resubmitted, even in amended form, for a certain time. The political establishment can just keep pushing this nonsense on the citizens over and over, while we, The People, must work hard every time to fight back. This is too asymmetric and unfair.
And that's why I think it's important to send an unmistakable signal: We. Do. Not. Want. This.
If you also think so, please help and make even a small difference.
(2025-08-18) Battle of Socials: Twitter/X VS Bluesky VS Threads VS Mastodon VS Nostr VS others
Following the success (sarcasm!) of my previous post "Battle of IMs", I decided it's time to write another post where I try to articulate in a technical but snarky way my view on the wonderful world of social media, and which one is best among the mainstream and non-mainstream ones. This is a long post, reviewing 14 different "socials".
Table of Contents
TL;DR
Social media is cancer, it's the scourge of humanity, an addictive and exploitative technology worse than any harmful chemicals. One day, from the rubble of our collapsed civilization, we will sit around bonfires telling stories of how blind we were to not see the ruin coming.
That said, it's difficult nowadays to not have to interact at least in some way with social media. I don't have much sympathy for those folks who do it "because otherwise it's impossible to keep personal connections", because I don't think that a connection who can only be kept by liking and replying to posts is a good one to keep. But I can understand more those folks who do it as part of their professional duties/career, because unfortunately the world has decided to go that way: it's not under your control, you can push back but eventually either you get on board or you get left behind.
However, if you are among those lucky AND strong souls who can afford to stay away from social media, by all means keep doing it! This post is probably not for you, but it might still contain useful insights on the recent advancements in the landscape.
My views in a nutshell:
- BEST OPTION: no social media.
- BAD OPTIONS: Bluesky, Threads.
- GOOD OPTION NOW FOR MOST USERS: Mastodon or Friendica.
- GOOD OPTION NOW FOR THE POWER USER: self-hosted Friendica.
- BETTER OPTIONS MAYBE IN THE FUTURE: Nostr or Secure Scuttlebutt.
I have lived social-free for most of my life, and happily so. I escaped (as in, never had a presence on) Facebook, Twitter, Instagram, whatever, but alas, I'm not the most "socially-inclined" person to expect a lot of suffering from not being on social media, so don't take me as a paragon. I've been on LinkedIn for many years now (that's a separate discussion I will address below), and I decided to fiddle with social media proper only relatively recently, just because finally non-centralized options are available.
Notice: In this post I will use the terms "social media" and "social networks" interchangeably, because I'm too lazy to articulate or even convince myself of the difference. Ready? Let's go!
Traditional Social Networks
Let's start with a quick review of the traditional, evil ones first.
Facebook
The archetype of social media demon. Mix tobacco, heroin, alcohol, gambling, microplastics, and plutonium in a blender, and try to imagine the digital equivalent of the result. You're still not close to what Facebook is. For me, Facebook is the prime argument for those people who claim that, post-2005, access to the Internet should have been heavily restricted to "digital-savvy users" only, as assessed by a state-controlled quiz and related "Internet driving license". All of us have witnessed some friends or acquaintances who were, let's say, never meant to be on the Internet in the first place, descend into madness as soon as exposed to the toxic fumes of Facebook. One day, if humanity manages to survive, historians will write essays on the Cyborg Reptilian Lord, and how his disguise fooled everyone into thinking he was a fellow human, rather than a saboteur sent by a hostile alien race.
Meta
Hey buddy, 'member the Metaverse? How's this trillion-dollar revolutionary technology and associated rebranding of Facebook going?
Instagram
Like Facebook, but only with images, I mean, "pics". So you can be even dumber, no need to write or read anything, just put on some make-up, smile, and pretend you have a great life even if your real life sucks. I call it "Fintagram" (from Italian "finto" = fake).
I refuse to call it "X" just because a megalomaniac trillionaire managed to buy a 1-letter internet domain name. Twitter is a great human accomplishment: it was very difficult to produce something dumber and more toxic than Facebook, but eventually the goal was achieved!
TikTok
Oh yes, please Great Leader, keep brainwashing me and the Western youth with your sweet algorithmic junk through what can only be called a hostile foreign actor psyop, so our brains can rot away and pave the road to the global dominance of the Party People. I love it so much.
So, I won't talk further about those.
Professional Social Networks
Before diving into the interesting bits, let me discuss for a moment LinkedIn and friends.
LinkedIn
This is a prime example of a curse that should, and could have been avoided. LinkedIn is a special category for me. It's not a traditional social media, or at least it shouldn't be, except it pretty much became one in the last few years - and a pretty bad one too. Sometimes I replicate there some content that I also post somewhere else to amplify reach (so-called POSSE philosophy), but the main use I have for it is as a professional showcase, an "online CV", and I find it crazy that whole industries rely on this website to connect people seeking or offering employment. In other words, I, like many, use LinkedIn because I'm forced to, but I would happily avoid it if there were better alternatives.
Xing
This is an EU (German-based) LinkedIn. Better in spirit, but at the end of the day it's just another walled garden. Plus, WTH of a horrible name...
In general, I think that a crucial service such as an advertisement board for CVs and open industry positions should be provided by governments, rather than by private corporations. I would welcome an EU-sponsored, managed, and hosted version of these kind of professional network websites. If you're in academia (and VERY convinced to remain there) maybe you can avoid this plague, depending on the field you're in, but for most of us that's not an option.
Federated Social Networks
Let's get finally to the interesting part: non-centralized social media. This is a field that emerged a few years ago, and exploded in popularity mainly after the post-acquisition dumpster fire that drove many users away from Twitter. The underlying idea is to not have a single point of failure, where a single entity has control over your account, data, and network, and can pull the plug at any point without you, the user, having any say on that. In other words, this technology emerged to answer a growing need for digital self-sovereignty.
The most successful technologies in this field so far are those commonly called "federated social media". The idea of federation is that different services can communicate with each other while maintaining independence. In other words, you want a server that provides access to a group of users, but it is interoperable with other servers, so that users of different servers can interact. Notice: this is not "peer-to-peer" (P2P), because there is still a distinction between users and servers. But there is no single central server for everyone either, it's a bit like email: you choose your own mail provider, and still your emails can reach users of a different provider. If your provider bans you, gets bought by someone you don't like, runs away with the money, or starts enshittifying by charging more for your mailbox, you are free to "walk out": move to a different mail provider and bring with you your email backup. You would be very annoyed because now you have to notify all your contacts that your email address has changed (unless you have your own domain), but you can still use email, it's not that suddenly such a basic service is forbidden to you. This analogy is exactly what happens if you're banned by a federated service VS what would happen if, e.g., Twitter bans your account: in the former case it's just an annoyance, in the latter case you're screwed.
The main projects fighting for user capture so far are in fact in this category: Mastodon, Bluesky, and Threads.
Mastodon
Mastodon is a sort of federated Twitter. You have to register an account on a Mastodon "instance" (server), e.g. mastodon.social, defcon.social, or infosec.exchange (there are hundreds of them) and your username will be @youruser@your.instance . The interface is pretty Twitter-like, including the character limit on the tweets (that are called "toots" in Mastodon). You can see and comment on toots of other users from different instances. There is a limited form of "verification" where you can specify your website (if you own one) on your Mastodon profile, and then you include a special invisible tag in the HTML header of your website's homepage. Your Mastodon instance will check if that tag is present and, if so, will green-checkmark your website address in your user profile. Mastodon is a completely open-source and non-profit initiative, driven by a core team of developers who get a modest amount of donations, while each instance is run by volunteers.
How does Mastodon address the self-sovereignty problem? Well, first of all you can download a (portable) archive containing a copy of all your history and activity on that particular instance: your posts, replies, media you posted, etc. Then, if one day you want to move to another instance for any reason (and change the second part of your username in so doing), you can re-upload you archive to the new instance and all the old content will re-appear on your new profile (but, by default, you will lose your followers, and will have to rebuild the followers network again). Second, it is entirely possible to host your own instance with your own domain name, and maybe open it to family and friends, just like you would host a mailserver. Moderation is done at the instance level, by the administrators.
The federated nature of Mastodon leads to some... quirks. Many, if not all, of these can be seen as features rather than drawbacks, but might be unfamiliar to users coming from other social media. For example, the maximum character limit of your toots depends on the instance you're signed up to, because every instance can configure that value arbitrarily: instances like Fosstodon are more Twitter-like at only 500 characters, while instances like Infosec.Exchange allow more long-form content and have a limit of 11,000 characters; if you're signed in to Fosstodon and you want to see a long toot from Infosec.Exchange, you will see a 500-character preview of it, and will be redirected through a hyperlink to the original toot on Infosec.Exchange if you want to read the rest. Endorsing other users' toots is also different, because there are two different mechanisms: you can "like" a toot, "boost" it, or both. A "like" just notifies the author, and it's just a private way to tell the author that you appreciated what they wrote. A "boost", instead, means that you consider the content worthwhile to spread and be more visible. Mastodon, in fact, does not have an algorithmic engine that decides what you see: on your homepage you will see the feeds of the accounts you follow, and on the discovery feed you will see some random toots that are sampled from the pool of most-boosted ones. So it's really the users, or to be more precise "the crowd", who decides what should appear in your discovery feed. This can be annoying because, e.g., if a toot on a topic of politics gets boosted a lot, you will see it on your discovery feed even if you're not interested in politics. Mastodon decided that there is no easy way to address this problem without profiling users and collecting too much invasive data about them, but in order to mitigate the problem, people have created feed-bots, i.e. accounts that just aggregate toots on certain topics/keywords and that you can follow. It's not ideal but OK enough. Another quirk is the emphasis on inserting an alt text for images to help visually impaired users (to the point that people will come and complain to you if you don't do that every time).
For now I have my main social presence on Mastodon ( @tomgag@infosec.exchange ) and I can say so far it's not too bad. The userbase has reached a large enough adoption so that you don't see the same few people posting the same stuff, and you can reach many different topics and diverse audience. It's easy and lightweight to use, and at the moment I think it's one of the best available options.
So, what are the drawbacks of Mastodon?
First of all, complexity. See, Mastodon is a social media application part of the Fediverse, built on top of the ActivityPub protocol. If your head is spinning at this sentence, you may understand why explaining Mastodon to Average Joe might be tricky. There are hundreds of different Mastodon instances, so which one should you choose to create your account?
The reality is that all these instances communicate through the ActivityPub protocol, which is a way to encode messages according to a compatible format that can be parsed by all these instances. Different applications can communicate through ActivityPub, not only social media. These applications are grouped under the umbrella term "Fediverse" (which, confusingly enough, sometimes also includes the incompatible Diaspora* protocol), or just "The Fedi". Mastodon automatically gives you a presence on the Fediverse, and hence allows you to interact not only with other Mastodon instances, but with all applications that run on ActivityPub: Lemmy (federated version of Reddit), PeerTube (federated YouTube), Pixelfed (federated Instagram), and many others, you just need an account on any instance of these and you get the ability to interact with users of all these platforms and related instances. There is even a way to embed comments in your blog via Mastodon (which I might do at some point).
But, in truth, choosing wisely your instance *does* matter, for different reasons. The most obvious one is that you will have it as part of your username: @youruser@mastodon.social might be generic but OK, while @youruser@bdsm.hell might not be for everyone. On a much more fundamental level, when you sign in to an instance you have to respect that instance rules, and also implicitly accept the absolute authority and moderation of the instance administrator: being on a third-party Mastodon instance does not "set you free", you do not own your profile, and you can still be banned for reasons outside of your control, exactly like on Facebook or Twitter. From this point of view, self-hosting your own Mastodon instance is definitely a good idea.
Moreover, there is the issue of de-federation. Mastodon became an escape pod for many folks who ran away from the political turmoil of Twitter, so you can imagine how many instances or communities on the Fediverse are politically left oriented, but that holds true in the other direction too. Even Donald Trump's Truth is basically a Mastodon instance, can you imagine that? Plus, some instances might be set up on purpose by criminals for scam, spam, or distribution of illegal material, because anyone can. Administrators might not want to have anything to do with any kind of content coming from these instances, so they can "defederate" them: blocking them so users of the two instances cannot interact with each other. This has led to "schisms" in the Fediverse, where, e.g., certain political communities are de-facto isolated and cannot reach other users (because instances A and B can be federated, and each of them blocks instances C and D who do the same, so now you have a split). Is this good or bad? I leave it to you to decide, but be aware that, according to what I saw, most instances on Mastodon related to tech/cybersecurity tend to lean left.
There are other little annoyances, like the impossibility to format your toot in Markdown, or the lack of a quote text function, but these are WIP.
For me, the most obvious problem of Mastodon is that, if you're banned from an instance or want to migrate to another one, you lose all your followers. This might not be a big issue for the casual user like me, but if you're heavily invested in social media and accumulate thousands of followers, you are de facto locked-in to the instance you chose, and you are basically back to another Twitter. This completely defeats the purpose, I think, because the value of a social media is not just about the content, but about the network. However, recently Mastodon has implemented a follower migration feature. When you move your account, your old account can be set to redirect to your new one, and a notification is sent to all your followers prompting them to automatically follow your new account. While not all followers may transfer (some may have left the platform, or their instance might have issues), that's better than nothing.
So, again, hosting your own Mastodon instance on your own domain really seems to be the way to go. I haven't tried it yet but I will probably do it in the future, although the tech requirements worry me a bit: hosting a Mastodon instance seems to be resource-intensive, requiring a heavy software stack (Ruby on Rails, PostgreSQL, Redis, Sidekiq) and significant RAM and CPU power to run smoothly, especially when federating with other instances. Not for everyone.
Threads
Threads is Meta's attempt to Embrace, Extend, Extinguish Mastodon. It's basically Twitter, just run by the Cyborg Reptilian Lord, and with the goal (maybe, eventually, in a remote future) of being compatible with ActivityPub in order to spew poison on other Fedi instances. This has led many Fedi operators to adopt a "Fedipact", pledging to defederate Threads from their instances. The pledge seems to have worked to some extent, and accessibility between Threads and Mastodon is very limited. Meta's stated long-term goal is full, two-way interoperability, but the timeline is unclear, and the final form of the integration is still developing.
If you ask me, that's all FUD, Threads will never be fully interoperable with Mastodon. But even if I'm wrong, one thing is sure: people who left Twitter to join Threads, clearly didn't learn their lesson.
Bluesky
Bluesky is a direct competitor to Mastodon, with some good ideas, but I think it is a really bad solution. In fact, my main concern with Bluesky is that it's "federated" only in name, while in reality it's a centralized Twitter-like implementation. I call this "fedi-washing".
From a technical point of view, Bluesky is a social media app built on top of the AT Protocol (ATProto), an alternative to ActivityPub. Both Bluesky (the software and the service), and the specs for ATProto are developed by Bluesky Social PBC, which is a "for-profit-corporation-which-pretends-to-be-non-profit-to-save-on-taxes-but-still-relies-on-vc-money". That means that, unlike Mastodon, they have plenty of funds to research, develop, and market new features, but they are still getting this sweet VC cash on the promise of future monetization.
If you understand even just a little bit how the world goes, that's probably all you need to know about Bluesky. But if you want to dig deeper, keep reading.
The AT Protocol used by Bluesky has some interesting features, although to be honest I don't know how many of these are just impossible to achieve on ActivityPub or are just WIP lagging behind due to funding constraints.
First of all, usernames on Bluesky are not of the form @yourusername@bsky.social like they would be on Mastodon, but rather @username.bsky.social , a minor but IMHO more elegant difference. Most importantly, Bluesky allows you to set your own custom username as the domain name of a website you own, for example @mywebsite.com or, optionally, @subdomain.mywebsite.com . This is much nicer than Mastodon's "green checkmark on your website in your account profile" or @myusername@mywebsite.com at best for a self-hosted instance, but remember that in any case this alone doesn't mean that you are hosting your Bluesky instance on your domain, it just means that you used your domain to verify a custom username offered by Bluesky.
Another interesting feature is the introduction of custom algorithmic feeds. Users can build "recommendation algorithms" and submit them to an "algorithmic feed marketplace", and other users can subscribe to these feeds. This is nice because it offers the best of both worlds: no central entity deciding what feeds you see, and customizable experience. Like Mastodon, it is possible to use Bluesky to embed comments in your blog. Finally, there are services called "bridges" that allow interoperability between Mastodon and Bluesky and vice versa, by replicating on each other's network the presence of a user (although these are non-custodial: if I am on Mastodon and you follow me through Bluesky, you are actually following the bridge account, which is not under my control, you have to "trust" the bridge to not misbehave).
However, in my opinion, all these features do not justify the huge success Bluesky has witnessed in the last few years. I think another force is at work here: marketing. Remember all that sweet VC money? Well, I think it's pretty obvious that a substantial part of it went into viral marketing campaigns that touted Bluesky as the "free, decentralized alternative to Twitter". A lot of people moved there from Twitter, especially (quoting from Wikipedia): "minority communities and subcultures, including Black, artist, left-wing, transgender, sex worker, and furry communities, who benefited from the invite system. These early communities are often credited for the platform's historically left-leaning culture [...] Bluesky has been criticized by many for being a left-wing bubble". Again, I'm not judging here, but just for the record, be aware that this is the social climate you will find on Bluesky.
The main problem I have with Bluesky is that it's federated just in words. Sometimes you find tutorials like "how to host your own Bluesky instance", but most of the time these only refer to the Personal Data Server (PDS) part, which is little more than a store for your profile data. The Bluesky federation architecture is made up of many components, the PDS alone does not buy you much in terms of federation, it actually helps more Bluesky. The next part is the Relay, which is the one responsible for orchestrating all your and other users' feeds, and running that (as of August 2025, but it's increasing fast) requires over 50 TB (TERAbytes) of disk space. One should wonder, how centralized is a system where only deep-pocketed individuals or organizations can run a node?
The final, crucial component is the AppView, which puts everything together for the user, and it is currently not even open-source! Furthermore, all the management of the users' decentralized identities (DID) is actually centralized, which means that it's Bluesky who decides whether a user is even allowed to exist in ATProto. Yes, you have read it well: the single, most important aspect of a federated system, the user identity management, is actually centralized in Bluesky.
What does this mean in practice? Well, it means that Bluesky can do things that in a truly federated system should not be possible, like censoring and de-facto banning users from the whole ecosystem, or rolling out their own "VIP" checkmark verification system. It didn't take long to go down this road, did it?
Again, people who joined Bluesky after escaping the drama on Twitter, did not learn their lesson.
Diaspora*
Diaspora* is both the name of the application and the federated protocol it uses, which is another alternative to ActivityPub or ATProto. It is one of, if not the, oldest attempts at federated social media, dating back to 2010. It is very similar to Mastodon/ActivityPub, with instances that are called "pods" and similar username syntax, but with the ability to group contacts into circles (e.g., "Family," "Work") and share posts only with some of them, providing more granular privacy control. It also supports longer-form posts with rich-text formatting via Markdown, encouraging more blog-like content. From this point of view, it functions more like a federated alternative to Facebook Groups or Google+ Circles (remember that thing?).
Hosting a Diaspora* pod is relatively easy. The original Diaspora* software is also built on Ruby on Rails, but its architecture is generally considered less complex than Mastodon's, without as many moving parts like Sidekiq and Redis. However, user adoption is extremely limited.
Friendica
Friendica is an interesting project that is based on ActivityPub, but is also able to bridge natively to Diaspora*, so users can easily cross-post. It is federated in a similar way to Mastodon, but thanks to the compatible form of identities, it also creates a user presence on Diaspora* and hence allows you to interact with both networks. It offers a less "reactive" experience than Mastodon, for example, there are no push notifications, but this also means that self-hosting an instance is generally less demanding than Mastodon. It also includes other nice features that currently Mastodon lacks, such as Markdown formatting and friend circles.
Beyond Federation
All the solutions above have the advantages and disadvantages of being federated: they are efficient and performant, because the "semi-centralized" model helps a lot in that sense, but none of these are truly, 100-percent "self-sovereign". Even if you host your own instance, at the very minimum you are reliant on the (centralized) DNS architecture, which means that your government or your registrar can, in theory, silence you. To be fair, if you pick your domain name in a decent jurisdiction and you don't misbehave too much, the risk is relatively low. But still, libertarian advocates and cypherpunks aspire to fully uncensorable alternatives. It is known that achieving a "perfect" P2P system is generally hard. The two main projects that succeeded in adopting some good compromise in this sense are Nostr and Secure Scuttlebutt.
Nostr
Nostr (Notes and Other Stuff Transmitted by Relays) is, in a certain sense, also a federated protocol, but it brings federation "to the extreme". To simplify, in Nostr the federation part is just about the distribution of the content, but the management of user identities is 100-percent self-custodial. To be more precise, users in Nostr are not identified by a handle like myuser@somedomain.com , but by cryptographic (EdDSA) public keys of the form npub1d4ed5x49d7p24xn63flj4985dc4gpfngdhtqcxpth0ywhm6czxcscfpcq8 instead. This is cumbersome (e.g. you cannot follow someone on Nostr just by asking their username casually at the bar), but it allows full custody of a user's identity: all you have to do to join Nostr is to generate (locally) a private/public keypair, and use any Nostr-compatible client to start fetching and posting content. All your requests are signed by your private key, so anyone with your username (and, hence, your public key) can verify the authenticity of the request without the need of any 3rd party authority.
The distribution of content is done by special nodes that are called "relays". This is where the federated part comes into play: relays are identified by well-known hostnames (e.g. relay.primal.net ), they store user content ("notes"), and distribute it as other users request them, but a user's note can be replicated among many different relays, and users can connect to as many relays as they wish. So, for example, if I am user A and I am following user B, in order to fetch user B's posts and populate my feed I will request this content from the relays I am connected to. This also means that, as long as you retain the control of your private key, you're basically uncensorable, because unless you're the biggest a**hole in the world and manage to piss off EVERY single relay operator, you will always find at least one relay that lets you in. Nostr has been touted as the purest form of "freedom to speak" in social media for this reason, because it's almost impossible to stop a user from posting content. Even Edward Snowden is on Nostr.
Nostr is a very simple protocol at its core, and, as a consequence, a vast ecosystem of custom applications and ideas flourished around it, but it also means that, as a platform, it is still evolving and immature. There are many "plug-in capabilities" that not all relays or clients respect. These are in the form of formal specifications called NIP (Nostr Implementation Possibility). Some of them are pretty widely accepted, such as NIP-05 (which allows you to translate in a verifiable way your cumbersome Nostr pubkey username into a human-readable domain name like @mywebsite.com ), while others are more fringe. But the developer community is "rich and vibrant" as they say, so in a certain sense that's all very exciting, and useful features will eventually be adopted by everyone, it's just a matter of time.
There are also bridges on Nostr, that allow users to interact with other networks such as ActivityPub. For example, you can follow my Mastodon profile @tomgag@infosec.exchange on Nostr as npub1un4zcpgku6z6cgaqd67haeq4mym8u5teeqdw5r4kaa5eye8x8vcs87tqn3 .
So far everything looks great. What's the catch?
First of all, one obvious problem is spam. Since Nostr is so uncensorable, it's a heaven for spammers. The social network is so young, and already so ripe with spam and scams, it does not look good at all. Given the libertarian nature of Nostr, most relay operators do not police or moderate content, so you can find pretty much anything. This has led many instances of other networks, e.g. Mastodon, to block or rate-limit Nostr bridges. You might find difficult switching seamlessly from one network to another, for example not all your contact will appear, you have to manually accept a follow request from Nostr while on Mastodon, etc. The problem is so bad that there are NIPs proposing a mandatory small "fee" (in the form of cryptocurrency or proof-of-work like HashCash) for posting and distributing any content on Nostr, although they do not seem to be implemented by anyone yet.
Which brings us to "the Talk": who pays? This question is commonly dodged not only in social media, but in most modern consumer markets, and that's a bad sign. "If you don't pay for it, then you're the product", as they say, it sounds a bit of a cliché but I think there is a lot of wisdom in this sentence.
Nostr, in this sense, is very transparent: relay owners bear the infrastructure costs (disk, bandwidth, etc), and they are free to monetize as they wish. Relays could request fees or microtransactions to let you post, or even read content, or adopt other monetization strategies. Inserting ads on Nostr is difficult, because you only fetch content from people you follow, but nothing prevents users from inserting ads in their posts to recover the fees they themselves would have to pay. Again, nothing of all this is currently implemented or widespread, but the general sentiment is that it will be unavoidable in the future. The Nostr philosophy is the purest form of "no free lunch" attitude, which I think it's not bad per se. For example, Mastodon adopts more of a "donations/hobbyist" approach, where instance owners allow the instance to grow as long as their finances and donations manage to cover for it, then they block new subscriptions. This is also fine, but nothing prevents them to *also* monetize their userbase at some point in the future after all. Better to be upfront about it.
The issue with Nostr is not about the monetization philosophy itself, but rather where this philosophy comes from and what kind of environment it fosters: the Nostr demographics is made mostly of Bitcoin fanatics and "'murrica" lovers. As above, I am not judging this, but be aware that this is what you will find.
Nostr was created in 2020 by a right-wing pseudonymous Brazilian open-source developer and Bitcoin enthusiast (Giovanni Torres Parra, AKA "fiatjaf") and received a shitload of money from Jack Dorsey (ex-CEO of Twitter and notorious extreme libertarian) as a donation to develop Nostr. All the climate around Nostr is connected to its roots: most of the users engage in discussions about leftist conspiracies, no-vaxx, neoliberalism, financial anarchy, far-right theories, and, most importantly, Bitcoin, and how it is the only form of Free Money and how it is set to revolutionize humanity. The experience on Nostr is heavily shaped by "zaps", which is a way to "tip" users with small donations in Bitcoin.
From a technical point of view, Nostr suffers from high latency and patchy user experience, surely given by the fragmentation and fast evolution pace of the ecosystem. It offers some interesting features, such as end-to-end-encrypted private messages, but the feature was half-baked and IMHO not very trustworthy (and also a somewhat bizarre use case: I would rather use a secure instant messenger for private communications). Regarding the overall complexity, it's not for the average user. If you thought that Mastodon was too complex, good luck with Nostr.
To dig deeper into the technical limitations, one big issue I found with Nostr is key management. As explained above, in Nostr your identity is entirely controlled by your private key, you lose that and it's game over. In normal, "account-based" solutions, it is often possible to recover from a password compromise, e.g. by means of a 2FA, or even by petitioning some authority. For example, if you own a domain name and run a Mastodon instance at that address, the worst form of takeover that can happen is a domain name theft, which is extremely difficult (the DNS registrar has probably verified your address and credit card). But on Nostr, you mess up once and you copy-paste your private key instead of your public key into a public chat - that's over, anyone can take over your account.
Keeping your private key secure is seen as an afterthought in Nostr, starting from the clients. In fact, Nostr desktop clients are almost nonexistent or very limited. Most functionalities you get either with mobile apps, or with Chrome plugins, which are both very bad solutions for many different reasons. Most importantly and more terrifying is the multi-device approach: if you want to use your Nostr account on, e.g., your mobile phone and your desktop browser, you need to install both a mobile app AND a browser plugin - but they both secure the SAME private key! Which means that an attacker only needs to compromise one of your devices to take over your account. This is extremely bad security practice! There is a NIP proposal partially addressing this issue through the use of subkeys, but as long as this is not implemented and widely supported, I would say Nostr is not ready for the average, or even the power user.
Secure Scuttlebutt
Secure Scuttlebutt (SSB) is a competitor to Nostr, and it pushes decentralization even further, being basically fully P2P except for (in theory optional) aggregator nodes. The name is weird and I don't want to discuss it further, it's basically sailing slang.
SSB is based on the philosophy of being "local first". Like Nostr, your username is a public key corresponding to a private key that you generate once locally. When you create a post, this is signed and stored in your local, append-only database for your user. Your SSB client advertises its presence on the local network, so you see e.g. other SSB peers in your LAN. If you know the public key of another user, you can request a content update for that pubkey to your peers and, if they have it, they will send the new content to you. In order to facilitate discovery, two special types of nodes can be set up. There are "pubs", which are large storage repositories of user content: whenever a user connects to a pub, they update a copy of their user content on the pub, so that when another user connects to the same pub, they can fetch the first user's updates even if the latter is offline. Then there are "rooms", which do not store anything, but behave kind of like a VPN, allowing users to see each other even if they are not on the same local network, provided they are online at the same time. All content is append-only, similar to a blockchain: you can only see a user's latest posts if you first download all content that they have published since the last time you updated their profile on your local storage. In contrast with Nostr's "freedom to speak", SSB is more described by the motto "freedom to listen", because you have to do some more active effort in fetching the content you want - and only that.
SSB is pretty old: the idea dates back to 2014 by Dominic Tarr, a developer and cypherpunk who spent a lot of time sailing around the world with very limited communication. He wanted a type of social media which did not require constant internet connection, and acted like a "postbox" he could sync to whenever he docked to shore. In this sense, "pubs" mimic the role of real-life pubs/bars: places of aggregation where you can drop by and catch up on the latest gossips of people who usually frequent the place, even if they are not there in that particular moment. Then you leave the pub, you live your own life, and the next time you drop by you update your friends there with what happened to you in the meantime. The "cultural climate" you find on SSB reflects this, with vibes that are described as "solarpunk, green, anti-capitalist".
I think SSB's philosophy makes a lot of sense, but I didn't bother fully joining yet, mainly due to the extremely scarce adoption, even lower than Nostr's. As usual, there are bridges allowing SSB to communicate with other networks, but overall the experience is patchy and performance low.
More technically, SSB suffers from the same issue of Nostr regarding management of secret keys. In addition, SSB is much more complex than Nostr at the protocol level, being developed in a less-organized way, with outdated artifacts such as the main reference implementation using Node.js. Another big issue is that, since all the content is append-only, running a local storage (and, even more so, a pub) requires a ridiculous amount of storage per user. This is not a problem yet, due to the scarce adoption, but I don't think SSB can scale up as it is. There are ongoing discussions on how to modify its architecture to allow a more fine-grained data retention, for example by trimming older or low-request content from the storage, or by doing smarter replication between pubs, but this is all WIP.
Conclusions
Whew, that was a lot!
In conclusion, I pretty much like the decentralized ways of Nostr and SSB, but I think they are not ready for mainstream adoption until they both resolve their technical and non-technical issues. I hope they will in the near future. I am more optimistic about Nostr, because it's more mature, but the political climate there can be... not for everyone. I decided to join Nostr anyway, also in order to better monitor the situation.
In the meantime, I will stick to Mastodon as my social media of choice (not hosting my own instance yet but WIP on that, I will probably try to host Friendica for the native Diaspora* support and lower tech burden, but we'll see).
If you liked this post, don't forget to follow my TikTok account and get updated about other fantastic news!
(2025-08-05) I emailed Italian politicians about the EU's "ChatControl" proposal
I'm not saying this will have any meaningful impact, but I don't want to "talk the talk but not walk the walk," so I decided to take action. Today, I sent a series of emails with a formal tone to many members of the Italian government, parliament, and representatives to the EU, to express my concerns about the EU proposal for client-side CSAM scanning (colloquially known as "ChatControl").
I have already called for action on my Mastodon and LinkedIn profiles, and this is my small contribution to the issue. I think there is no need to articulate here why I believe the proposal is dangerous and short-sighted, as others have already done it better than I ever could (for example, Patrick Breyer). What I want to do here, instead, is twofold:
- Provide templates of the emails and the contact addresses to send them to, in the hope that you, my fellow Italians, will also want to contribute. While Gemini helped me a bit (and, just to be clear, all blog posts on this page are human-generated only), collecting the addresses, double-checking the references, and fine-tuning the text still took me some time. So, may this save some of yours.
- I will provide updates in future posts on who replies to my emails and how. To safeguard their privacy, I will not quote the exact text of the replies, except maybe for short excerpts. However, I want to at least share with you which of the politicians I contacted take the time to respond to a common citizen's plea, and what their positions on this important matter are.
So, stay tuned! In the meantime, here are the texts of the four emails I sent. Feel free to use the text/template to email your favourite politicians, I posted them here exactly for that reason, no need to ask me permission!
Email 1: to the Italian Government
Topic: Opposizione alla proposta 'ChatControl' - File 2022/0155 (COD)
To: gabinetto.ministro@interno.it , protocollo.gabinetto@giustizia.it , info.affarieuropei@governo.it , segreteria.butti@governo.it
Body:
Alla cortese attenzione del Signor Ministro dell'Interno, Matteo Piantedosi
e, per conoscenza,
all'Onorevole Ministro della Giustizia, Carlo Nordio
all'Onorevole Ministro per gli Affari Europei, Tommaso Foti
al Senatore Sottosegretario per l'Innovazione tecnologica, Alessio Butti
Illustrissimi Ministri, Senatore Sottosegretario,
Mi chiamo Tommaso Gagliardoni. Scrivo in qualità di cittadino italiano e di professionista nel campo della crittografia e della sicurezza informatica. Maggiori informazioni sul mio profilo professionale sono disponibili ai seguenti indirizzi:
[link to my CV and my LinkedIn profile]
La presente per esprimere la mia profonda preoccupazione riguardo al documento del Consiglio dell'Unione Europea 10131/25, parte del file legislativo 2022/0155 (COD) relativo alla "Proposta di Regolamento per la prevenzione e la lotta contro l'abuso sessuale sui minori", altresì nota come "ChatControl".
Apprendo che, in sede di Consiglio, la posizione preliminare del Governo italiano sia stata favorevole all'approvazione di tale norma. Desidero esprimere, con il massimo rispetto per le istituzioni che rappresentate, la mia ferma opposizione a questa misura. Come professionista del settore, ma anche come padre e cittadino europeo, ritengo che essa eroda le libertà fondamentali e la dignità di tutti, in nome della pur nobile intenzione di proteggere i minori.
La proposta "ChatControl" è largamente criticata dalla comunità internazionale di esperti come tecnicamente inefficace per gli scopi prefissati e, al contempo, pericolosa per la sicurezza collettiva. Nessuna delle soluzioni di scansione lato client ("client-side scanning") attualmente ipotizzate è esente da gravi vulnerabilità.
Da tecnico, posso assicurarVi che il potenziale di abuso di una simile tecnologia di sorveglianza di massa è enorme. Non si tratta di stabilire "se" verrà sfruttata per fini illeciti, ma solo "quando" verrà utilizzata per scopi autoritari o per operazioni di spionaggio e sabotaggio da parte di attori ostili, statali e non.
Per queste ragioni, mi appello alla Vostra responsabilità e Vi chiedo cortesemente che il Governo italiano voglia riconsiderare la propria posizione in vista del voto finale, opponendosi all'approvazione della proposta in seno al Consiglio dell'UE.
Invito le Vostre Signorie ad ascoltare le audizioni degli esperti tecnici e a salvaguardare l'infrastruttura di sicurezza informatica e la privacy dei cittadini, che costituiscono un bene primario per la nazione e per l'Unione tutta.
Ringraziando per l'attenzione, porgo i miei più distinti saluti.
Tommaso Gagliardoni
Email 2: to the Italian Parliament
Topic: Esame della Proposta UE "ChatControl" - File 2022/0155 (COD) - Richiesta di audizioni e parere contrario
To: maschio_c@camera.it , giglio_a@camera.it , giulia.bongiorno@senato.it , giulio.terzi@senato.it
Body:
Alla cortese attenzione dei Presidenti delle Commissioni Parlamentari
On. Ciro Maschio, Presidente della II Commissione (Giustizia), Camera dei Deputati
On. Alessandro Giglio Vigna, Presidente della XIV Commissione (Politiche dell'Unione Europea), Camera dei Deputati
Sen. Giulia Bongiorno, Presidente della 2ª Commissione (Giustizia), Senato della Repubblica
Sen. Giuliomaria Terzi di Sant'Agata, Presidente della 4ª Commissione (Politiche dell'Unione Europea), Senato della Repubblica
Illustrissimi Presidenti,
Mi chiamo Tommaso Gagliardoni. Scrivo in qualità di cittadino italiano e di professionista nel campo della crittografia e della sicurezza informatica. Maggiori informazioni sul mio profilo professionale sono disponibili ai seguenti indirizzi:
[link to my CV and my LinkedIn profile]
Mi rivolgo a Voi per il fondamentale ruolo di indirizzo e controllo che le Commissioni da Voi presiedute esercitano sull'operato del Governo in materia di legislazione europea.
La presente per sollecitare la Vostra attenzione sul documento del Consiglio 10131/25, parte del file legislativo 2022/0155 (COD), noto come "ChatControl".
Come noto, la proposta mira a introdurre forme di sorveglianza di massa e generalizzata delle comunicazioni digitali, incluse quelle protette da crittografia end-to-end. Apprendo che la posizione preliminare del Governo italiano in sede di Consiglio UE sia stata favorevole all'approvazione.
Tale orientamento desta profonda preoccupazione nella comunità tecnica e scientifica. La proposta "ChatControl" è largamente criticata da esperti internazionali come tecnicamente inefficace per gli scopi prefissati e, al contempo, pericolosa per la sicurezza collettiva. Le soluzioni di "client-side scanning" proposte creerebbero, di fatto, delle "backdoor" sistemiche, esponendo le comunicazioni di cittadini, imprese e della stessa Pubblica Amministrazione a rischi incalcolabili di spionaggio e sabotaggio da parte di attori ostili.
Il potenziale di abuso di una simile tecnologia è enorme e rappresenterebbe un precedente gravissimo, in palese contrasto con i principi di proporzionalità e necessità sanciti dai trattati europei e dalla nostra Costituzione.
In virtù del Vostro ruolo, Vi chiedo rispettosamente di voler:
1) Avviare un'approfondita istruttoria in seno alle Vostre Commissioni sulla proposta in oggetto, analizzandone le criticità tecniche e giuridiche.
2) Promuovere un ciclo di audizioni con esperti indipendenti di sicurezza informatica, crittografia e diritto delle nuove tecnologie, per acquisire un quadro completo e non filtrato dei rischi connessi.
3) Adottare una risoluzione che esprima un parere contrario all'attuale impianto della proposta, impegnando il Governo a modificare la propria posizione in sede di Consiglio dell'Unione Europea e a tutelare i diritti fondamentali e la sicurezza digitale dei cittadini italiani.
Confidando nel Vostro fondamentale ruolo di garanzia democratica, porgo i miei più distinti saluti.
Tommaso Gagliardoni
Email 3: to the Italian LIBE members at the European Parliament
Topic: Proposta "ChatControl" (2022/0155 COD) - Appello alla difesa della privacy e della sicurezza digitale
To: alessandro.zan@europarl.europa.eu , giuseppe.antoci@europarl.europa.eu , susanna.ceccardi@europarl.europa.eu , alessandro.ciriani@europarl.europa.eu , paolo.inselvini@europarl.europa.eu , ilaria.salis@europarl.europa.eu , cecilia.strada@europarl.europa.eu , anna.cisint@europarl.europa.eu , giuseppe.milazzo@europarl.europa.eu , leoluca.orlando@europarl.europa.eu , gaetano.pedulla@europarl.europa.eu , nicola.procaccini@europarl.europa.eu , giuseppina.picierno@europarl.europa.eu , sandro.ruotolo@europarl.europa.eu , marco.tarquinio@europarl.europa.eu , roberto.vannacci@europarl.europa.eu
Body:
Onorevoli Membri del Parlamento Europeo,
Mi chiamo Tommaso Gagliardoni. Scrivo in qualità di cittadino italiano ed europeo, e di professionista con esperienza nel campo della crittografia e della sicurezza informatica. Maggiori informazioni sul mio profilo professionale sono disponibili ai seguenti indirizzi:
[link to my CV and my LinkedIn profile]
Mi rivolgo a Voi nella Vostra cruciale funzione di membri della Commissione per le libertà civili, la giustizia e gli affari interni (LIBE), l'organo parlamentare con la responsabilità primaria su questo delicato dossier.
Con la presente vorrei esprimere la mia profonda preoccupazione riguardo la proposta di compromesso attualmente in discussione in Consiglio relativa al regolamento "ChatControl". Come Voi ben sapete, il testo minaccia di imporre obblighi di scansione generalizzata ("client-side scanning") anche sulle comunicazioni protette da crittografia end-to-end.
Una simile misura, se approvata, rappresenterebbe un attacco senza precedenti ai diritti fondamentali alla privacy e alla protezione dei dati, sanciti dagli articoli 7 e 8 della Carta dei Diritti Fondamentali dell'Unione Europea. Creerebbe inoltre una pericolosissima vulnerabilità strutturale nell'ecosistema digitale europeo, esponendo cittadini, imprese e istituzioni a rischi di sorveglianza e attacchi informatici su una scala mai vista prima.
La comunità accademica e tecnica internazionale è unanime nel condannare queste proposte come tecnicamente fallaci e intrinsecamente insicure. Non esiste una "via di mezzo" che permetta di indebolire la crittografia solo per i "cattivi": ogni backdoor creata per legge diventerà inevitabilmente un bersaglio per regimi autoritari e organizzazioni criminali.
Il Parlamento Europeo si è storicamente distinto come il più strenuo difensore dei diritti digitali dei cittadini. In questo momento decisivo, la Vostra voce e il Vostro voto sono fondamentali.
Vi esorto pertanto a:
1) Mantenere una linea di ferma opposizione a qualsiasi testo che includa forme di sorveglianza massiva e indiscriminata delle comunicazioni private.
2) Difendere l'integrità della crittografia end-to-end senza compromessi, quale strumento essenziale per la sicurezza, la libertà di espressione e la democrazia nell'era digitale.
3) Respingere in via definitiva la proposta, qualora essa dovesse giungere al Vostro esame senza le necessarie garanzie per i diritti fondamentali.
Confidando nel Vostro impegno a difesa dei valori fondanti dell'Unione Europea, porgo i miei più distinti saluti.
Tommaso Gagliardoni
Email 4: to the Permanent Representation of Italy to the EU
Topic: Osservazioni tecniche sulla proposta "ChatControl" - File legislativo 2022/0155 (COD)
To: rpue.coord@esteri.it
Body:
Alla cortese attenzione della Rappresentanza Permanente d'Italia presso l'Unione Europea,
Mi chiamo Tommaso Gagliardoni. Scrivo in qualità di cittadino italiano ed europeo e di professionista nel campo della crittografia e della sicurezza informatica. Maggiori informazioni sul mio profilo professionale sono disponibili ai seguenti indirizzi:
[link to my CV and my LinkedIn profile]
La presente per sottoporre alla Vostra attenzione alcune osservazioni di carattere tecnico e di sicurezza nazionale relative al file legislativo 2022/0155 (COD), noto come "ChatControl", e in particolare alla proposta di compromesso attualmente in discussione in sede di Consiglio.
Consapevole del Vostro ruolo cruciale nella negoziazione dei dossier legislativi in seno ai gruppi di lavoro del Consiglio, desidero evidenziare le gravi implicazioni che l'adozione di tale normativa comporterebbe per la sicurezza strategica nazionale ed europea.
Le soluzioni tecnologiche ipotizzate, basate su scansioni lato client ("client-side scanning"), richiedono per loro stessa natura un indebolimento sistemico delle garanzie offerte dalla crittografia end-to-end. Questo non rappresenta solo una minaccia per la privacy individuale, ma crea una vulnerabilità sistemica sfruttabile su larga scala che mette a rischio:
- La sicurezza delle comunicazioni governative e istituzionali.
- La protezione della proprietà intellettuale e dei segreti industriali delle imprese italiane ed europee.
- L'integrità delle infrastrutture critiche che si affidano a comunicazioni sicure.
Introdurre per legge una "backdoor" legalizzata, per quanto motivata da intenti lodevoli, equivale a creare un'arma cibernetica che potrebbe essere - e con ogni probabilità sarebbe - rivolta contro gli interessi nazionali da parte di attori statali ostili o di organizzazioni criminali ad alta capacità tecnologica. La comunità internazionale degli esperti di sicurezza è unanime nel considerare tale approccio tecnicamente insostenibile e pericoloso.
Si chiede pertanto che, nello svolgimento del Vostro mandato negoziale, la delegazione italiana:
1) Valuti appieno il rischio strategico per la sicurezza nazionale derivante da un indebolimento generalizzato della crittografia.
2) Si opponga fermamente a qualsiasi testo che imponga la scansione di massa delle comunicazioni private, in quanto tecnicamente incompatibile con un'efficace protezione delle infrastrutture digitali.
3) Trasmetta queste osservazioni tecniche ai competenti uffici ministeriali a Roma, affinché la posizione politica nazionale sia informata da una corretta e completa valutazione dei rischi tecnologici.
Certo che la tutela della sicurezza nazionale digitale sia una priorità per la nostra diplomazia, porgo i miei più distinti saluti.
Tommaso Gagliardoni
(2025-07-14) How to NOT evaluate the power of a quantum computer, and a rant about Ludd grandpas
I had a hard time finding a fitting title for this post, but I felt I had to write something. TL;DR: this is your daily reminder that "How large is the biggest number it can factorize" is NOT a good measure of progress in quantum computing. If you're still stuck in this mindset, you'll be up for a rude awakening. It is also a rant about seasoned but misinformed "experts" who are given, in my opinion, too much credit on topics they don't really understand, with unhealthy consequences.
This morning, I saw this new preprint on the IACR Eprint:
Replication of Quantum Factorisation Records with an 8-bit Home Computer, an Abacus, and a Dog
When I see "catchy" titles like this on the Eprint, my day is typically ruined. I'm immediately on the defensive even without reading the content:
- I know it's either a joke or 99% BS.
- But I also know that most people will not catch it, and will start asking me "hey, have you seen this new crypto paper???".
- Regardless, I know there's going to be a contentious tone implied, and many nasty online arguments in the making.
Sadly, the TikTokization of academic papers made these kinds of titles more and more common: there is so much stuff produced, that for your paper to reach an audience nowadays it has to stand out from the crowd somehow. I think the first title of this kind I saw was the "Faster, Longer, Harder..." thingy, but at least that one had technical merit. I'm sure there are many other "social media fight"-like titles I thankfully didn't see.
Anyway, back to the paper in question from today. This is a special case, because it's one of those papers which do not only have a provocative title, but are meant to be provocative in the tone and the content. The authors are Peter Gutmann and Stephan Neuhaus. Regrettably, I don't know Neuhaus, despite being employed at ZHAW in Zurich, maybe one day I will meet him at some event or for a beer. But I know Gutmann by fame: one of the old "cypherpunk legends" from a past time, front fighter of the 90's Crypto Wars, author of the Gutmann Method to securely erase files from hard drives, and long-time quantum skeptic. Among his works: "On the Heffalump Threat" (a 1-page allegory seeing quantum cryptanalysis as a myth) and "Why Quantum Cryptanalysis is Bollocks", which is more of a slide deck, and on which, from what I can see, most of the new paper is based on. Trying to distill the main claims from this work, they boil down to:
- Most papers claiming quantum factorization records are BS.
- At the end of the day, the best that has been done so far is factorizing 15 as 3x5.
- Therefore, quantum cryptanalysis is BS.
Let me start by saying that I agree with the first point above. Most papers of the form "New Quantum Factorization Record Using Shor's Algorithm" are, let's say, not particularly insightful, and are probably only written to add another publication record. But most of them are also not particularly wrong, just overselling a minor result. Honestly, there is much worse in academia nowadays.
But the underlying issue which annoys me is the repeated, flawed logic I always see brought up by many quantum skeptics. The original "factorize 15" paper was a proof of concept from 2001 (!!!) and it was the first time someone demonstrated a toy-example of quantum factorization. I don't think reputable QC companies have been advertising their progress in terms of "factorization record" in the last decade or so, and we do not care for the many non-reputable ones. But too many people still look at that paper from 2001, say "no larger number has been factorized quantumly so far", and then extrapolate "QC is a scam" from that.
When I ranted about it on Mastodon and LinkedIn today, I realized how flawed my assumption was, that most crypto/infosec professionals would understand immediately what I was talking about. I received many messages, publicly and privately, asking me "but then WHAT is a good measure for QC progress?", so I guess it's a good idea to explain also here why you should disregard quantum factorization records.
The thing is: For cryptanalytic quantum algorithms (Shor, Grover, etc) you need logical/noiseless qubits, because otherwise your computation is constrained to very small (toylike) circuit depth/time. That's because your "operating window" of time for completing your computation is in the order of nanoseconds, after that the quantum error accumulates so much that your results become garbage. With these constraints, you can only factorize numbers like 15, even if your QC becomes 1000x "better" under every other objective metric. So, we are in a situation where even if QC gets steadily better over time, you won't see any of these improvements if you only look at the "factorization record" metric: nothing will happen, until you hit a cliff (e.g., logical qubits become available) and then suddenly scaling up factorization power becomes easier. It's a typical example of non-linear progress in technology (a bit like what happened with LLMs in the last few years) and the risk is that everyone will be caught by surprise. Unfortunately, this paradigm is very different from the traditional, "old-style" cryptanalysis handbook, where people used to size keys according to how fast CPU power had been progressing in the last X years. It's a rooted mindset which is very difficult to change, especially among older-generation cryptography/cybersecurity experts. A better measure of progress (valid for cryptanalysis, which is, anyway, a very minor aspect of why QC are interesting IMHO) would be: how far are we from fully error-corrected and interconnected qubits? I don't know the answer, or at least I don't want to give estimates here. But I know that in the last 10 or more years, all objective indicators in progress that point to that cliff have been steadily improving: qubit fidelity, error rate, coherence time, interconnections... At this point I don't think it's wise to keep thrashing the field of quantum security as "academic paper churning". Albeit I need to stress that I am myself no "quantum doomsayer", and I don't think, or at least have no reason to believe, that "Q-Day is behind the corner" (sigh, this sounds so wrong).
The other point raised by Gutmann and others is that, in the field of cybersecurity, we have so much stuff to worry about, that it is pointless to focus on a theoretical menace that might or might not materialize in the next 20 years. This is a typical example of relative privation fallacy, and it's even worse because it fails to consider that the nature of this "theoretical menace" is so much more disruptive at scale than anything else you could consider today: imagine a world where pretty much all cryptographic signatures, certificates, and asymmetric encryption fail. Can you imagine that world? I'm not sure I can.
And now here is my meta-rant. Just to be clear: I don't mean to apply it to Gutmann in particular. Sure, I disagree with his views, but there are so much worse offenders out there.
I wish people would stop giving absolute credit to "prominent experts" just because they released some book/paper/software of great fame but unproven impact 30 years ago and have since then retreated into golden tenure, writing technically empty but catchy papers with provocative titles, typically mocking or dismissing any form of new technology they don't fully understand. Quantum, Web3, AI, green energy, whatever, there is always a reason to distrust. These "Ludd grandpas" (you know at least a couple of names of who I'm referring to) are, unfortunately, often worshipped by a large number of semireligious followers, who contribute to the spread of their short-sightedness. It's the strength of numbers found in such religious cohorts that empowers these celebrities in making bold claims that would otherwise embarrass anyone else, without fear of repercussion. Because, if an early-career researcher makes similar bold claims and they're proven wrong, then they are ruined for life (or they will be perceived as arrogant "a priori" and be ruined even before having the chance to prove their assertions). But if it's some old and famous expert who went on TV, then whatever, they are not in a position to suffer consequences from their mistakes. They can safely entrench themselves by challenging any opposing but weaker voice in proving them wrong. I find there is such an unfair advantage in saying "I will be right until proven wrong", because in many cases it also implies "and, if one day I'm proven wrong, nobody will care, because I will be tenured/retired and people have the attention span of a hamster anyway". In the meantime, the rants of such VIPs glowing of fossil glory hurt careers, sow an unhealthy distrust for the unknown, and steer policymaking and technical preparedness to dangerous directions.
Looking closer at my own environment, I know we graybeards in infosec have this, I would say healthy tendency, to keep in high respect elder members of the community who somehow distinguished themselves "on the battlefield" (especially against governments and institutional adversaries) in the past. But we need to keep our feet on the ground, and accept that times change, people change, and we can at times be right and at times be wrong. Some people think that, because they have been experts in a certain field long time ago, they can afford not only to keep talking like experts in that field forever, but also in nearby, or even uncorrelated fields. The Dunning-Kruger effect is real.
Thinking deeper, maybe mine is a typical case of rejection for the image in the mirror: I hope I will never become like that in the future.
(2025-05-03) On privacy VS compliance in Web3
I have been thinking for a while about the issue of anonymity in Web3 (and, more in general, anonymous transactions). The growing realization of the damage caused by decentralized financial technologies is nagging my cypherpunk self, who has been at war for a lifetime against invasive tracking, manipulative marketing, and surveillance capitalism. I think it's time that I collect my thoughts here.
Spoiler alert: I'm not endorsing backdoors, but I think some middleground solution must be found.
The problem
Here is the problem. The modern world we live in (where "modern" here means "since currency") has been shaped by the war between the desire of criminals to hide their transactions, and the need of authorities to unmask them. Which is, of course, a super-simplistic way to say that there is a conflict between different parties for the control of transaction flows. This war has somehow seen a crystallization, or stability, for a relatively long time until recently, with a status quo where most transactions were trackable, except cash and very complex border-crossing exchanges which would require the collaboration of mutually very mistrusting parties to be tracked, and are anyway not at the reach of the common folks. I am talking about the pre-2010 world of wire bank transfers, credit card networks, forex, etc. In this world, it was certainly possible for criminals in a suit to move large sums of money from "shell company A in Panama" to "shell company B in Hong Kong", but it was very difficult for Lone Wolf Joe to buy a fake passport online from Dimitri Counterfeitsky, or for large scam/blackmail online operations to be successful on the long run. Sure, there were already plenty of nigerian princes or angolan generals with tons of gold to move abroad, but generally speaking these things were always risky for the perpetrator(s), involving either a physical action (meeting Dimitri in person, crossing a border with a suitcase full of cash, etc), or trusting the assumption that the crime was small enough to not trigger a cross-border collaboration.
The flip of the coin is that, for this status quo to hold, we built an Orwellian machine which was meant to track everyone's transactions. When I imagine how much control do bank institutions and services like Google or Apple have over our finances, I think it's a shame how we missed out so much on this and we still don't have, e.g., a way for authorities to get a super-accurate tax assessment from every citizen in an automated way. I mean, if we need to embrace dystopia, let's at least reap the few good sides of it! The only invisible transactions would be those carried over in cash, which is on its way to be banned anyway, and it already accounts only for a rounding error at a state level. (Disclaimer: I use cash any time I can, and I hope I'll be able to do so as long as possible)
Enter Bitcoin. Anarco-capitalists enthusiastically looking forward to a world of untraceable transactions. More well-informed people would point out how, no, Bitcoin doesn't make anything anonymous at all, actually it's even more traceable than normal bank transactions. And yet, more forward-looking people would say that it doesn't matter: Pandora's box was open, it would be just a matter of time.
This last camp was right. Bitcoin was just the beginning, the missing piece to make pre-existing anonymous transaction ideas really work. Monero arrived, then Zcash, then TornadoCash, then many others. We are now at the point where people are building fully decentralized and private computing platforms. Cryptographic research in zero-knowledge proofs (ZKP), multi-party computation (MPC), and fully homomorphic encryption (FHE) has exploded. All these technologies have their flaws, but overall they work: it is now possible to send in a completely anonymous way a token of a certain value to another address, without anyone else not involved in the transaction being able to see sender, amount, or receiver of the transaction. This is a cypherpunk's dream.
And soon the woes arrived. Bitcoin and friends de facto enabled ransomware, as well as money laundering and tax evasion on a massive scale, providing means and incentives and giving rise to criminal industries that would simply be unthinkable without anonymous payment tech. Allegedly, North Korea financed its whole nuclear missile program through ransoms collected by their cyberattack operations, and it is pretty certain that Russia is massively using web3 technology to circumvent sanctions, just to name two cases. Luckily, no shady business ever happens in the western world thanks to cryptocurrencies, amirite?
And almost everybody is happy about it! DeFi, as it is now, does not stand for "Decentralized Finance", but for "Deregulated Finance". Those same criminals in suit who were previously moving sums between shell companies, today are doing the same between crypto exchanges and smart contracts. When intentional fraud is not involved, sloppy security or mishandling are. See this link for a long list of disasters in Web3. Bitcoin anarco-capitalists absolutely do not want compliance (except when they're hacked, then they go crying to FBI). Banks do not want compliance, because it allows them to diversify and play with high-risk investments without repercussions. So, anonymous cryptocurrency is great after all!
Except that this creates a toxic environment ripe for abuse, which makes [dictator] smile, and overall makes most humans more miserable and target of remote crime. So, no, not everyone is happy about it. Not necessarily for the noblest reasons, but governments and police authorities are cracking down on anonymous fintech. There is a growing interest in the field of "compliance" in Web3, where chains and institutions are trying to collaborate to provide a way to enable banks and other regulators to perform anti-money-laundering (AML) and know-your-customer (KYC) duties on private transactions, the same way regular banks are required by regulators to do in order to avoid financial fraud. But so far all the proposals boil down to the cops' old recipe: backdoors. Let's insert a "lock for the good guys only", so that authorities can trace everything but criminals cannot. Yeah, right.
So, on one side we have backdoors, on the other side we have [dictator] becoming fatter and happier by the day. Is there no hope?
My view on it
What I described above is, at the end, a typical case of weighting pros and cons of a newly introduced tool or technology. When faced with such dilemma, my gut reaction is to say "the overall effect on society is positive, new tech is always disruptive, this is good". Especially when we're talking of privacy technology, given the sad state of the world as it is now, it's in my opinion fair to lean toward embracing such new tech, and consider the "usual boogeymen" as "acceptable collateral damage". You know what I'm talking about: I don't think Tor creates more drug addicts or makes more children to be abused.
And here is the crux of my problem: after having witnessed for many years the damage enabled by anonymous payments, I am not so sure anymore that the net effect on society is positive in this case, or even that it will eventually be positive many years from now. Hardcore libertarians cherish a world without taxes, without police or government even, where everyone is responsible for themselves, and nobody else can have any say in the way they conduct their business. At my age, I find this view to be childish and delusional at best, arrogant and psychopathic at worst. We literally built a millennia-old civilization on the premise that, no, we're not left to fend for ourselves alone in the dark, there are other people around us, and they are a valuable resource. We need rules to make sure that one's rights do not trample someone else's, and we need authorities and mechanisms to enforce such rules. I do not think that we, as a society, are ready for such a massive shift of paradigm, where I can anonymously pay a hitman to murder my neighbor.
"But wait", you might say, "the crime committed in your example is the murder, not anonymity!". I find this cheap philosophy not very useful: modern anonymous payment technology works pretty well, there is basically no way to catch someone like that without additional circumstantial hints, except of course human errors. You might have read this very old post that I wrote many years ago, and that I still agree with: the seriousness of a crime should be roughly evaluated as the damage caused by the crime divided by the probability of being caught and prosecuted for that crime. It's the only way that makes sense. If this is the case, how should we evaluate the seriousness of a crime committed with a technology that makes the crime almost perfect?
But I acknowledge that even this is a slippery slope. If we follow this reasoning, then it makes sense to ban end-to-end encryption (E2EE) as well, right? Because otherwise police authorities would have no way of prosecuting criminals, and then satanists and rapists and blacktransqueermuslims etc etc, right?
No, I am not advocating for backdoors, not in the case of E2EE, anonymous transactions, or anything else. But not for philosophical reasons: I am not advocating them because I know that they don't work. Because there is no such thing as "lock for the good guys only", and I find it unbelievable that there are still people trying to gaslight the public opinion in this sense, as if believing it would make it magically possible.
So we're back at square one with this long rant. Can a compromise exist, between the holy individual right to privacy, and the collective need to audit transactions and prevent crime?
My proposal
I had the opportunity of tackling this very problem during my research at Horizen Labs. This is not an endorsement of my employer, I don't know if what I'm trying to build will eventually see the light, this is just personal research on a topic which may or may not catch interest from the company - or from anyone else. Nothing of what I write here is confidential, I just wanted to share my view on the matter.
I think the first question to ask ourselves is: what does "privacy" mean?. Without going too much in the technical (or even philosophical) details, in the realm of Web3 transactions this is pretty obvious: there are exactly three things that make a transaction "private": the identity of the sender, the identity of the receiver, and the amount transferred. Depending on the technology implementation, you might also want to hide the id of the token itself. Modern privacy tech for Web3 hides some or all of these data fields, typically by using ZKP or some variation therein: instead of "Alice sending a token to Bob", Alice broadcasts (for everyone to see) a zero-knowledge proof of a statement like: "1) I am the owner of a token of a certain value, and 2) I have transferred ownership of a new token of the same value to another address, and 3) I have burned (erased) my previous token, so I cannot spend it anymore".
Now, if we want to introduce "compliance", then it is clear what we have to do: we have to append extra information to a transaction, only readable by authorized parties, which declassifies those three pieces of data above. And the way we manage this "readable by authorized parties" makes all the difference between a "backdoor" and a "more reasonable system".
And what would such "reasonable" system look like? More than a proposal this is a wishlist. These are the five minimal properties I think should be required by any sane "compliant privacy" mechanism:
- Decentralization: regardless of anything, there should be no single point of failure in the trust model for declassification. No single authority should "hold the key" for inspecting a user's transaction. Using MPC technology, this power should be split by a quorum of trustees in a committee.
- Accountability: whenever a regulator decides to audit and deanonymize a transaction, this fact should be publicly visible and reported. Picture this as "the name of the judge on the search warrant". This property is crucial, it is the only safeguard against authorities colluding and abusing their power.
- Warranty: if I am under investigation, I must be notified of this ("avviso di garanzia", this seems to be common in Italian law but not sure about other legislations).
- Opt-in: users must decide what kind of information to make available to which regulators and under which conditions. In other words, users should attach a compliance manifest to each transaction. Other nodes of the network will decide whether to accept or not the transaction according to their own compliance policy.
- Programmability: users can revoke and modify their decision, on a per-transaction basis.
The first property is obviously about security, and should be taken seriously. For example, key shares should be split among parties who naturally do not trust each other and/or do not have any incentive in colluding except for investigating a mutually damaging crime.
The second and third properties are about keeping authorities accountable for abuse. You don't want a system where the authority "pinky-swear promises" to only wiretap 100 transactions per month without having a way to verify this. Ideally, a good system should allow everyone to see that a certain authority has decided to leverage its power for an investigation, but should only allow the target of the investigation to be notified as such. It could in theory be done in a layered way, e.g., the judge is notified whenever a police officer uses this power, but the general public does not, although, personally, I think public authorities should report to the public, not to other authorities. In any case, you don't want the public to know the identity of the specific officer (for their safety) or of the investigated party (for dignity).
Finally, the fourth property ensures, on one hand that an incentive mechanism pushes users to balance privacy VS compliance: if I set my privacy requirements too high for this transaction, then few nodes will take the risk of accepting it, and will therefore request higher fees from me. On the other hand, it makes sure that information that the user absolutely does not want to reveal remains hidden. The fifth property makes the system flexible in practice.
There are systems like GNU Taler which, in my opinion, make a lot of sense. In a nutshell, Taler transactions are semi-anonymous: the identity of the sender is always hidden, but the identity of the receiver is not. This mimics real-world shops, where the bakery does not ask for my id to sell me bread when I pay in cash, but the bakery itself is not anonymous and the owner is known. Taler is not decentralized though, it's a PKI-style tech. I would like a "good" privacy-compliance Web3 tech to be able to mimic Taler if the user so wishes.
Does a technology like this exist already? I don't know, it might certainly do, since the Web3 world is moving so fast. If not, will it ever be built? And, in either case, will it ever reach adoption?
Open to hear your feedback, please reach out!
(2025-04-02) On China, racism, and the mysterious disappearance of cybersecurity academic Xiaofeng Wang
You might have read about the very recent news on the mysterious disappearance of US-based cybersecurity professor Xiaofeng Wang and his wife. The story is in evolution, and things might get updated fast, so this is just a very preliminary impression and my thoughts on the matter since some people asked me about it. I leave some pointers below for the detailed report, but here is a quick recap of the story.
Xiaofeng Wang is a prominent US-based chinese computer scientist, with tons of publications in areas such as cryptography, cyber security, AI, bot and fraud detection, medical and biometric security, and more. He was professor at Indiana University Bloomington (IUB), while his wife, Nianli Ma, was system analyst and programmer at the same university. They both recently disappeared in mysterious circumstances: Wang's students have been unable to contact him since mid March, and his university's webpage has been taken down on March 19th. He and his wife have been "canceled" from all directories at IUB. On March 28th, the couple's two houses have been raided by FBI agents. It was later revealed that, on that same day, Wang received a letter from IUB terminating him with immediate effect, apparently because they found out that he had accepted a new position in Singapore, and was supposed to start his new role this summer. As of today, Wang and his wife could not be reached, IUB declines to comment, and FBI only acknowledged "court-authorized law enforcement activity".
Everyone is trying to figure out what happened, and all the people who could shed some light on the matter are not speaking. In this climate of uncertainty, wild guesses are not good, but let me try nonetheless.
I have never talked with Wang personally, but I think we crossed at some conferences at some point. I know some of his papers, which seem to denote a preference for collaboration mostly with other chinese scientists. He was involved in very sensitive topics: AI security, genomic data protection, and more.
Reading comments online, conspiracy theories abound, but it seems to me that everyone is afraid of spelling out loud one of the most plausible explanations: Dr Wang was performing espionage for the chinese government, he got caught, but chinese secret services alerted him and helped him into hiding. Let me be very clear: I am not saying this is what I think happened, but it seems to me one possible explanation (he wouldn't be the first one). Still, most "polite" comments I read online, even in the infosec community, are kind of la-la-la dodging this scenario.
Why? Is it because of fear of being associated with racism in these tumultuous times? Before exploring alternative explanations for Wang's disappearance, I think we have to talk about Xi's China and Trump's America.
My stance on the CCP is not a secret for anyone who knows me. My wife is taiwanese (meaning: from the country of Taiwan) and I have fought my whole life against invasive surveillance and authoritarianism. Still, I consider myself blessed enough to have had a proper education, had the opportunity of meeting many brilliant chinese people, and in general living in a "bubble" where there is respect for different cultures and where, generally speaking, nationalities do not matter that much. Yes, it's still a bubble, but better than other bubbles. This is just to say that I do not generally buy in the "China bad" narrative, but it seems undeniable to me that China has proven over and over again to be very competent and motivated in terms of espionage capabilities. So, not knowing him personally and unable to assess the character of the individual, to me the possibility that Wang was indeed performing espionage for the chinese government would not be particularly surprising.
The Captain Obvious disclaimer is that a chinese-sounding name does not necessarily imply ties to CCP, or even to China itself. I personally know americans with chinese-sounding names who can't even speak Mandarin. But in Trump's America, a chinese-sounding name brings a lot of... extra connotations. So, it's also natural to look at other explanations for Wang's disappearance.
I have read theories according to which the FBI raid was racially motivated. In 2025, this is sadly not unthinkable. But I cannot fathom this being the most straightforward explanation, there must be something more. One explanation that I think makes more sense is that the raid was indeed fueled by the current US political climate, but ultimately triggered by IUB as a retorsion. We don't know exactly the circumstances around Wang's acceptance of the Singapore position and IUB's finding out, and there is also rumors about IUB taking disciplinary action for Wang's failure to disclose ties to China when receiving a previous grant. This is just speculation, it is difficult to say since nobody is talking. But the scenario I am depicting is, somebody high-up at IUB finds out that Wang has secretely negotiated a new position and is about to go poof, not only creating difficulties for teaching and academic organization, but also jeopardizing some personal ambitions connected to Wang's grant and the prestige it brought to IUB. In this situation, a way out could have been to "express concern on Wang's ties to China" with the FBI, and use this as a plausible excuse to cut ties with Wang. Again, I am not saying this is what I think it happened, but I think this explanation makes more sense than the FBI saying "uhm, we haven't reached our weekly quota of blacks, latinos and asian simps to raid, let's resort to academics".
Or, of course, it could also be that the conspiracy theories are right. Maybe Wang found out something big and was silenced. Maybe he discovered something very bad or embarrassing for NSA/FBI/DOGE. In our field, this is unfortunately not unheard of.
In any case, Matt Green is right: this is not normal, we can't pretend it is. It seems already clear that IUB did not follow the due process for terminating a tenured faculty member. But, in today's America, nobody respects the law anyway, and people can be "canceled" as if their very being exists only subject to the benevolent approval of someone higher up in the food chain. This is the world we live in, I don't like it, and you shouldn't either.
(2025-03-13) NIST selects HQC as fifth algorithm for quantum-resistant encryption
NIST has announced the end of the evaluation phase for adding another cryptographic algorithm to the suite of ciphers designed to be resistant against quantum computing. The winner is HQC, which is now going to enter the standardization phase.
HQC is a code-based KEM (used for encryption rather than signatures) which has been selected on mainly two criteria: being reasonably performant, and not being based on lattice assumptions (because there is already ML-KEM for that, and you want a backup option in case cryptanalysis one days breaks lattice-based problems).
Personally, I would have also liked to see Classic McEliece standardized: this is a scheme which is based on still different hardness assumptions, very robust, and has the property of having extremely small ciphertexts. The drawback is the large size of the public key, but public keys can be distributed once and then this amortizes the overall cost, so that it makes a lot of sense for certain applications, but NIST decided that this would have been too much of a "niche" use case.
In an impetus of productivity, I decided to perform a minor restiling of this website. Among these novel breakthrough innovations of science, you will find:
- I added a picture of a handsomer version of myself (circa 2018) in the header, so that search engines do not index Whit Diffie's picture as a preview of my links anymore.
- Added icons with links to connect via email or Jabber/XMPP, plus link to my Mastodon account.
- Started using ISO-8601 for date format, because why not.
- Hyperlinks color now does not cause your eyes to explode.
- General but very incomplete HTML sanitization.
But the most awesome part is the addition of an RSS feed, which now boldly brings this website in the year 2001. Now, this is what progress looks like!
(Mar 12th, 2025) On cashless restaurants and QR menus.
Yesterday night I went out with a friend in Zurich, and we were searching for a place to have dinner. We entered this popular-looking Thai-fusion restaurant. Only after we had a seat we discovered that:
- There was no paper menu, just a QR code.
- The QR code was not pointing to a PDF menu, but to an ordering website full of trackers.
- "We are a cashless restaurant".
- "Cash tips are welcome".
We left the place and went to eat somewhere nearby.
In a very timely manner, here is what I found on Slashdot this morning. I can confirm the findings!
Let's leave security and privacy considerations aside for a second. I already use a screen too much during the day, thank you, I would rather not fiddle with my phone if I go out eating. And, what exactly should I "tip" for?
Oh, and please don't hit me with the environment BS, I really don't think that a bunch of paper menus have any practical impact in the great picture of the environment footprint of a restaurant. The real reason restaurants go for QR menus are: user tracking, possibility of surge pricing, and reduced costs. But I also suspect that there is some component of "hip" factor. You know, "young, cool people do everything with a phone nowadays".
I think I like the idea in this Slashdot comment. I might print my own stickers.
(Feb 20th, 2025) Quantum Computing news: Microsoft announces first TOPOLOGICAL qubit!
I just want to briefly report about the recet news from Microsoft, who announced the realization of the first topological 1-qubit device. You might wonder, why is this important? One qubit doesn't sound too much exciting, and surely you can't do anything useful with it. Well, the interesting part is topological.
I still remember my very first PhD trip abroad: the 12th Canadian Summer School on Quantum Information in Waterloo, ON, in 2012. There, I first learned about topological QC in a lecture by Steve Simon (not to be confused with the other Simon). The rough idea: instead of using the "traditional" approach of QC, where you build a qubit by manipulating an extremely small and fragile system, like a single atom, in topological QC instead you use a system composed of a 2D grid of many small objects whose interactions follow a pattern that you can "move around" the grid without moving the objects, and you represent the state of a qubit as the global topological property of this pattern of interactions (think of it as a knot of braids in space-time). As these patterns can "braid around" in loops, changing the state of a qubit means unlooping this "space-time knot" and re-looping it differently, which is extremely difficult, and therefore you obtain a system which is "natively" stable and resistant against decoherence, unlike traditional fragile systems (ion traps, superconducting qubits, etc) which are constantly disturbed by the environment, and require constant and expensive error-correction to remain stable.
The idea sounded too good to be true, and in fact it was. The catch is that these "small objects" from which you build your 2D grid must behave very "weirdly" in order for these "braidable interactions" to appear: they cannot be fermions, nor bosons, but a new type of "virtual particle" called non-Abelian anyon, which only exists in 2D but not 3D. It was not even clear whether these particles could exist in nature, so for a long time topological QC was considered kind of fringe, a few attempts at detecting anyons over the decades have given mixed results, so not many were willing to invest in this kind of research.
Except Microsoft. Microsoft has been championing the idea of topological QC for a long time, but (I think) more as a differentiator to other competitors like Google and IBM. Regardless, for many years now topological QC was only investigated at MS.
Now it seems like we finally have some news: Apparently, Microsoft has managed to create non-Abelian anyons with simple household material (indium arsenide - aluminium nanowires, you surely have some in your pantry), and they showcased a 1-qubit device built with this technology, plus a roadmap to scale the device to fully error-corrected qubits in the future.
Is this cool? Yes, I think it absolutely is.
Is this practically promising? I have no idea. Even Scott Aaronson does not know.
(Feb 18th, 2025) Battle of Instant Messengers: my view on Signal VS Matrix VS XMPP/Jabber VS others.
People often ask me what IM (instant messenger) I prefer and why. If I want to joke, I might link to this XKCD, or I might give one of the following answers:
Kidding apart, as a paranoia-lover hacktivist, I try to give recommendations which, I think, lead the world toward a better state according to my views. The advice I give in this post might not reflect the best option for you personally, and is limited by my (lack of) knowledge. But let's give it a try.
So, what are the options? There are literally thousands, and I do not pretend to know them all, not even a small part. But let's start with the easy ones.
Whatsapp
You know what I think of Whatsapp already. It is so popular that in many places (in Italy, for example) it has become the de facto standard of communication, even with public offices or commercial entities. I find this not only extremely problematic for privacy and national security, but utterly disgusting in general. I do not use Whatsapp, and I must admit that it's hard. The only good news here is that this app is becoming mainly most popular among boomers-to-millennials generations, so it's hopefully on its way to decline.
Line
It's basically an Asian Whatsapp. Do not.
Telegram
This is even worse than Whatsapp for so many different reasons I don't want to spend time on. I find it mind-boggling that it has become so popular even among circles like cryptobros and some anarchists.
WeChat
If there is one app even worse than Telegram, this must be it. Installing WeChat on your device means installing a backdoor for the Chinese Government to spy on you.
Threema
Once touted as a "Swiss privacy-oriented IM solution", over the years it has shown so many issues that it has completely lost my trust. Luckily, its adoption is quite limited.
Discord
I wish Discord to burn in Hell. I don't even know how it became so popular. It's basically IRC, but with ads, super annoying notifications, and completely centralized. They even mislead the users by calling "servers" what actually are "channels".
Slack
You must really like pain if Slack is your to-go IM of choice. Personally, I hate Slack, but in a corporate environment I think it is a better alternative to Teams or Google.
Mattermost
More or less like Slack. Do not use it if you don't have to.
Let's get to more "serious" options. The following are the 3 main IM solutions that most privacy/security advocates would recommend. However, there are usually very strong opinions on what is "the best". Following are my views on it.
Signal
Signal has been, for quite a few years now, the golden standard for messaging security. You get a Whatsapp-like experience, but with top security features, quantum-resistant crypto, privacy-by-default and, most importantly, leadership and roots with a top track of ethical hacktivism and cypherpunk values. I use Signal daily with family and most of my friends, and it's the standard recommendation for most people. The usability is unbeatable.
But.
There are issues with Signal. First of all, over the years Signal has taken some questionable decisions, like bundling in a shady cryptocoin payment system, and forcing users to adopt a recovery PIN which transmits, albeit in encrypted form, too much data to Signal, under basically the sole assurance that Intel's SGX is secure (LOL). There is also the extremely annoying part that Signal still requires registration via a mobile number (as a 2FA? In 2025? Seriously? Why?). Since last year, Signal finally adopted usernames, but only on top of normal registration via phone number. Moreover, for a long time Signal was only available from the Play Store, and required Google Services to run. Luckily this is not the case anymore: you can install Signal's .apk from their official website (at least for the first time, then it keeps itself updated), but it is still not available on F-droid (understandable, kind of) or Accrescent (not so understandable).
These issues, by themselves alone, are not so terrible to downgrade Signal to "not recommended" IMHO, but they are also not good, and could have been prevented. They are, I think, the symptoms of a much bigger problem with Signal: centralization.
See, Signal is, at the very core, "Whatsapp run by non-evil people". Which is bad, in the sense that you never know what's gonna happen next. Even non-evil people have to eat. Signal is currently living mostly on donations, but things might change in the future. What if VCs jump in? What if Signal is acquired? What if the new CEO is not "same as old CEO"? You, as a user, have no control over this, and I think that digital sovereignty should be your nr 1 concern. To put it differently, even if I have a lot of trust on the folks currently running the show (and I really do!), I think Signal is one of those projects at very high risk of enshittification in the future.
In short, Signal is still one of the easiest and most secure IM choices, and probably the best option to recommend to non-tech people, but I found myself less and less comfortable recommending it to family and friends over time.
Matrix
Matrix is the "cool kid" in the realm of private and secure IM, and many security communities migrated there in the last few years. Matrix is a federated IM service, meaning that anyone can host their own Matrix server, and users can join whatever server they want and still be able to interact with users from other servers, a bit like e-mail. Good security features, works well on mobile, many different clients to choose from, and thanks to its bridges you can connect through Matrix to other services, even Whatsapp. Sounds good, isn't it?
The reality is, unfortunately, not so good. First of all, usability is... meh compared to Signal. As long as you use Element, the "official" client, otherwise it's even worse. Nothing too wrong with Element, but the number of options and features is overwhelming for the newcomer, takes some time to get used. I think even I haven't fully grasped how multi-device sync works...
But that's not the full story. There is, generally speaking, a bunch of reasons to not trust Matrix completely, which in essence boil down to: difficult to decentralize. Even if Matrix is theoretically federated, in practice running your own server is such a PITA that only large organizations can afford it, due to resource costs and difficulty in maintenance. Running a Matrix server is heavy, requiring generally many Gigabytes of storage per user.
I do use Matrix, but it's not my favourite IM. You can reach out at @tomgag:aria-net[DOT]org .
Jabber/XMPP
The grandpa of secure, federated IM, but still rockin'. First of all: You should not call it "Jabber" anymore, that's the old name, the official name since 2002 is XMPP (Extensible Messaging and Presence Protocol). XMPP is the backbone of a plethora of IM systems. Unlike Matrix, which aims at offering a fully fledged experience out-of-the-box, XMPP aims at being lightweight and extensible through plugins. This has the advantage that hosting your own server is very easy: compared to Matrix, the effort and requirements are minimal. Also, because it is a completely open specification, it has been adopted over time by many government and no-profit entities (rescue operations, military, NGOs, etc) as "the" open standard of choice. The disadvantage is mainly that, because the adoption of extensions is so fragmented, there is no "uniform" user experience: things that are possible with one client (e.g. audio/video calls) might not be possible with another, or might not be supported by some servers.
Speaking of XMPP security, even encryption was not meant to be "default", and was added as an optional extension. The modern standard for XMPP encryption is OMEMO which is, roughly speaking, equivalent to Signal (with caveats, lot of them, yes, I know).
And this is where the fight starts!
There are very strong opinions favoring XMPP over Signal or vice versa. I admire Soatok and I think he's right on many things. I also think he's wrong on many other things, including this one. I agree more with this one instead.
I do use XMPP and I love it. You can reach out at xmpp:tomgag[AT]draugr.de (I do not host my own server yet, but I will probably do at some point). I use Gajim as a desktop client for linux, and Conversations.im on mobile (Google-less Graphene OS) and they both work perfectly for me: text, audio, video, whatever. Also Shufflecake's official chat is hosted on XMPP, so drop by to say hi!
Summing up, in my personal opinion: XMPP > Signal > Matrix > Anything else. The situation is not optimal:
- Signal is centralized.
- Matrix is pretty much centralized, and has a shady ecosystem.
- XMPP has non-uniform user experience, things might not work, adoption is scarce, cryptography is less good than Signal's.
Is there really no better alternative in 2025?
Simplex
This is pretty new and I haven't tested it in depth yet, but I've read great reviews about it. I will keep this updated. Stay tuned! UPDATE 2024-08-18 after a preliminary investigation, there are a few things that do not convince me about Simplex. It's not a hard nope for now, but I cannot endorse it yet. Be patient and stay tuned for a followup.
Lastly, how about P2P IM? I don't know of many (Briar?), feel free to suggest one if you care, but the problem with P2P systems for IM is that, in general, users can only communicate if they are online at the same time. Which might be acceptable in some use cases, but it's not a solution that will cover most users' needs.
I hope this was useful to you, or at least clarified a few doubts. Just don't use shitty IM, especially if owned by some psychopathic rich individual, it is bad for you and humanity!
(Jan 1st, 2025) Announcement: I'm starting a new collaboration with Horizen Labs!
New year, new life! After exactly 6 years of service, yesterday saw the end of my employment at Kudelski Security. Effective immediately, I am joining Horizen Labs in the role of Senior Cryptography Researcher.
I want first to remark how grateful I am to Kudelski Security and my amazing ex-colleagues for these awesome 6 years, it was really a good ride! But I felt it was time for a change, and I found in Horizen Labs a great opportunity to expand my knowledge in cryptography. In my new role, I will help to research, develop and optimize zero-knowledge proof systems such as STARKs and SNARKs. This is an immensely complex field which has always fascinated me, and finally I have the opportunity to dig deep into it! I find the topic of ZKP interesting regardless of the cryptocurrency applications, as I believe many privacy-friendly technologies can benefit from these schemes, but I also liked the pragmatic mindset and the good atmosphere at my new team. I am looking forward to tackling new challenges!
For the record: I am not relocating, I will still be based in Zurich, but I will visit Milan occasionally, where Horizen Labs has an office where most of the tech people are.
(Aug 28th, 2024) A retrospective rant about (some of) DEF CON Villages
Finally I have some time to report about my recent trip to the US for attending Black Hat and DEF CON. I also went on an AMAZING (but short) solo road adventure after DEF CON, which was probably the best part of the trip, but I don't want to talk about that. I want to talk about DEF CON, and especially (some of) the villages. The reader shall pardon the unusual writing style that I will adopt for this post, definitely unprofessional and more akin to a rant from an internet troll than to an objective and rational argument. Just for the lulz.
First of all, it must be stressed that I'm no DEF CON veteran, in fact my first DEF CON was only last year; I am therefore in no position to assess the "trend" or compare this year's event to the "history" of this amazing convention. I am also in no position to comment about this year's badge drama, because I don't think I have enough information about that to form myself an opinion. But, as a single data point, this year's DEF CON felt to me "less cool" than last year's. Maybe the novelty factor, or (more likely) the new venue. Having to drive through the Loop to reach the venue on "public transport" from the Strip? Brrr... cringe. Also, how the f*** is it possible that all the 2XL t-shirts are sold out during the first 23 minutes from open doors? I mean, I don't want to imply anything with this but... you are selling merch at DEF CON... you should know your average customer... May I kindly suggest you to have the BULK of your merch in 2XL and 3XL size and only have a smaller amount of the rest?
But let's talk about something else: the villages. From my understanding, DEF CON villages became more and more prominent over the last years, as a "more inclusive" way to create community. Which is cool, and I'm sure that there are *some* villages that are tremendously fun and interesting. Unfortunately, that did not apply to the two villages I was mainly interested in.
One of these two villages, let's call it the "sci-fi village", is pure crap. No joke. But I was aware of it, because I visited it last year already, so I had no big expectations. To be fair, due to the very nature of the "sci-fi village", it's a bit difficult to have activities/talks that are both engaging AND technically interesting, and moreover, this year I didn't spend too much time there, so it's definitely possible that the situation improved, or is going to improve in the future.
The second village, instead, let's call it the "super-security village", or SSV. I missed it last year, but I've heard good stories about it, so I decided I need to show up and, dunno... get involved? Get "included"? Offer volunteering help for next year's edition maybe, or even submit a talk or propose something cool. For sure I should bring there my Shufflecake stickers! I mean, this is DEF CON, it's STICKER-CON! Everyone LOVES stickers at DEF CON, and I'm sure the SSV will be happy to have Shufflecake stickers around!
Full of trepidation, I wear my Shufflecake t-shirt and follow the map to the location of this village inside the enormous venue. The first impression is already... disappointing. The SSV has been allocated one of the largest village spaces: there is a stage, desks for the organizers, a lot of tables around, even some large and well-made custom props. And it is... almost empty. Nobody on stage, maybe 10 people all around, most of them look like organizers. The tables are dark and empty.
I put on my most genuine smile and approach the desks of the organizers, who... ignore me. They keep chatting among themselves with an aura of boredom, or keep staring at their phones and laptops. I keep smiling and nodding around with no success. After some time I gather my courage: "Ah-ehm... hello?". A guy maybe half my age slowly raises his head to me, his look is the cosmic emptiness of enthusiasm and interest. "Hi, my name is Tommaso, I'm new to this village but I also love super-security! So, I was wondering... what do you people do here, what is there to see?".
The guy picks up a napkin from a pile. Oh wait, that's not a napkin, it's actually a printed leaflet folded in half? He hands it over to me. "You see, this is the SSV, we do super-security. You know, this and this. And this is the program". The program looks... amateurish? To put it nicely. "Intro to super-security". "How to make your phone super-secure". "Surprise talk by a university professor". WTF? And the program is... sparse, there are, like, only two talks this morning.
I must try hard not to be snobbish, because I would hate a snob myself. So I keep smiling and say "Ah cool, you know, I'm a super-security practitioner myself. Actually, may I leave some of these stickers around? Have you ever heard about Shufflecake? No? TrueCrypt? Neither? OK, this is... an open-source software to... encrypt your disk and... it's developed by a friend of mine and myself and... we published a paper at CCS last year and... I thought..." (my words fumble as I see the expression of boredom on the guy turning first to confusion and then to skepticism) "I thought... this would be perfect for the SSV... maybe some people are interested... this is the website... what do you think?".
"Weeeell" says the guy, crossing his arms on the chest and leaning back while pulling his chair away from me. "You know, I cannot... we cannot... endorse third-party software. Understand?".
STICKER-CON, YOU ASS, THIS IS STICKER-CON! IS THIS THE WAY TO WELCOME ME?
"Uh... Oooook... I see... May I... leave the stickers on the tables around here then?". The guy pulls a nervous smirk. "Umph! Well, I'm not POLICING THE TABLES... YET."
I am OUTRAGED and I leave the place. I have never been so coldly welcomed at a private party to which I was not invited. I decide to have a look at their website.
- Outdated ("past talks" 2020).
- Full of JavaScript that would make RMS scream in fear.
- A Google Calendar form for showing the program.
- All organizers listed as their Twitter handles only.
- "Store" section.
- "Subscribe to our YouTube and Twitch channels so you don’t miss out!"
WHAT IN THE DEPTHS OF HELL AM I SEEING HERE?
I resolve to write this ranting blog post and I keep enjoying my DEF CON. But the day after, I change my mind: I should not be an asshole just because I met a weird guy, maybe he was not in a good mood, or jet-lagged, or under drugs, or whatever. I cannot judge the SSV just by my interaction with ONE of their organizers - provided he was an organizer indeed, and not a random volunteer. So I decide to try again, with renewed enthusiasm!
I go to the SSV again and the situation is like the day before. But I don't see yesterday's guy, so maybe I will have better luck today! I approach again the desks of the organizers, and this time I am welcomed by another 20-something guy who seems actually friendly and full of enthusiasm!
"Hey, welcome to the SSV! Check our program and if you have any questions just ask!" Oh yes, this is going well. "Hi, I'm Tommaso and, this is my first time at this village but I am a super-security practitioner myself and..." "OOOHHH SERIOUSLY? Then you absolutely have to talk with [random name], he's also an expert in super-security, you know... HE STUDIED MATH AT THE UNIVERSITY!" and he made his eyes as big as golf balls while saying that. "Uhhh... sure, I'd be happy to talk with him... but for now I just wanted to understand, what kind of talks or activities are you people interested in? You know, I was considering contributing next year". "Ah, in this case you MUST ABSOLUTELY talk with [name2] who's main organizer, come with me, I'll introduce you".
The guy walks me along the tables, while I am wondering what is exactly the meaning of "introducing me" since I barely said a word about myself. I have the feeling that the guy just wants to get rid of me quickly, but whatever. He points me to another human being sitting there doing something at the computer and then says "Hey, this guy here wants to talk about talks, he's a super-security practitioner." and then he leaves. The other human being looks at me surprised and says "Oh, hello there!". But before we could even start a conversation, a bunch of other people arrives, interrupts us and (ignoring me) start to talk with the organizer, who quickly apologizes to me "I'll be around later, excuse me" and leaves with the other bunch of people.
I can't even. Are all zoomers like this nowadays? I feel... old.
Humiliated, I go back to the friendly guy. "Hey, how did it go?". "Well... busy times I guess... I'll talk later with [name2]. But may I ask you... Are you one of the organizers?". "Oh no" the guy says, "I'm only a volunteer, I help to run things!". "OK" I say, "and how did you get involved?". I'm asking this to the guy to understand how this social group was formed. Because, so far, to me it looks like these are a bunch of stoned "internet friends" who somehow managed to scam DEF CON into conceding them their "private corner" (either that or they are Dogecoin millionnaires and paid for the space themselves), and are not really interested in "including" other people at all.
"Well, I didn't know anyone at first, but then I joined their chat and I got to know people. The chat is basically the main thing where the community lives, we all know each other there. YOU SHOULD JOIN OUR DISCORD AS WELL IF YOU WANT TO CONTRIBUTE!"
D-I-S-C-O-R-D? I mean, you are the SUPER-SECURE VILLAGE and you have your community ON DISCORD? Why not FACEBOOK???
And this was the straw that broke the camel's back, so I changed my mind AGAIN and I decided to write this post.
I conclude with two thoughts. The first one is a story of my time back during my PhD in Darmstadt. Every time we would go out for lunch, we would cross a part of the residential neighborhood, and we would pass in front of a super-typical "Quartiersstube", one of countless many in German towns. I had never been into one, so I asked some of my German colleagues to go there. "Are you kidding?" they replied. "You just... cannot go inside there... that's not for you... I would not go there myself! You must be... born and raised here, in 'da 'hood... or a friend of a friend...". I did not understand. It was a public venue after all. So, one day, I decided to go there alone and order a beer. Let me just say that I got my beer, but the way I felt at the SSV was more or less the same I felt inside that pub.
The second thought is, what price is reasonable to pay for "inclusiveness" at a venue like DEF CON? And by "inclusiveness" I do not mean stuff like, welcoming everyone regardless of sexual identity, skin color, etc, that's something I give for granted and, hopefully, we will be able to give for granted more and more in the future. What I mean is that, at the end of the day, it's a hacker conference, people pay to go there and expect a certain level of technical involvement. It's fine to have a "intro to XYZ" session for n00bs, but if more than half of your program is like that, then I question you belonging to this "hacker conference".
In any case, this is just a very un-serious rant about my personal, subjective experience. I am sure I was just unlucky and next year it will be much better. Would you accept a technical talk submission by a humble super-security practitioner? Please welcome me better next time, I have expectations.
But I'm still not joining your Discord.
(May 30th, 2024) How I Put my Foot in my Mouth with Whit Diffie at Eurocrypt 2024
Yesterday night I was attending the rump session at Eurocrypt 2024 in Zurich. Whit Diffie (yes, that Whit Diffie) was there and, during one of the breaks, he very kindly allowed people to queue up in line to take pictures with him. For a second I considered how kind of unfair it was, having a multitude of super-world-famous cryptographers all there at the venue, and still people only wanted to take pictures with him, but, I mean, Whit Diffie is Whit Diffie after all! So I lined up as well, and when my turn came I asked if I could have a picture next to him. "It would be a honor", I said, and he smiled and nodded back. Then I took place next to him, while another person was taking the picture with a phone. And then I told him something.
What I intended to say was something on the lines of:
I've been in this field for so long, and yet I never managed to take a picture with you before, thank you so much!
What I did say instead, because I was distracted by someone talking at me and then I slipped my tongue, was:
I've been in this field for so long!
He laughed at me and said "Yeah, I've been for longer!".
And then spaghetti fell down from my pockets all around me. It really was a honor!
(Feb 8th, 2024) Another Change of Host
I'm temporarily moving this website to a different host, still with Hetzner but I'm playing around a bit. SSL certificates will soon change as well. The new IP will be 49.13.21.214
(Jan 25th, 2024) ML Model Collapse as Radionuclide Contamination in Post-War Steel
I keep hearing that ML models such as LLMs and other transformers are prone to "model collapse", i.e., the process according to which the behavior of these models degrades over time due to the progressive ingestion during the training phase of more and more ML-generated content. For example, the more and more ChatGPT is used, the more and more the Internet gets flooded with ChatGPT-generated content, and therefore subsequent iterations of ChatGPT are trained with less human-made text and more, lower-quality, machine-generated text. Trash in, trash out.
It looks like this problem is here to stay and it is so bad that, apparently, some AI companies are already scraping the Internet Archive for pre-ChatGPT content. This phenomenon gives a huge advantage to companies like OpenAI, which entered the business first and have therefore made it in time to stock large datasets of "pure" data.
Here is a random thought. This feels similar to the search for low-background steel in radio-sensitive detectors and applications. This steel is scarce and precious, usually salvaged from pre-1940 sunken vessels - just like data scraped at low-bandwidth from the Internet Archive.
I hope that, just like the need of this pre-war steel became mostly obsolete after the nuclear ban treaties, we will reach at some point some form of AI treaty which will make it possible to flag most of machine-generated content as such. Technically, I have no idea how to do that, but life taught me to not underestimate the power of social norms and regulations, so who knows?
(Nov 13th, 2023) A Trick to Speed up RSA Modulus Generation
Recently I had reasons to recall something that happened in 2019 at Kudelski Security during some client project. At some point there was a discussion on how to speed up the generation of RSA keys. As you might know, you need two primes roughly of the same size, p and q, but they cannot be "any" primes, they must be (among other things) "safe primes". In particular, they must have the property that (p-1)/2 and (q-1)/2 are still prime. And this is annoying, because first you must spend a lot of CPU time generating a large prime, and then maybe you have to discard it because when you check the condition above it doesn't hold. That's a big bottleneck of RSA key generation.
Then I made the observation (and I cannot believe I'm the first one to have made such observation) that for this property to hold, the last 2 LSB of the prime must *both* be 1, because large prime implies odd, so modulo 2 must give result 1 both for the candidate prime and its half. So, having these 2 LSB both set to 1 is a very minimal condition to ensure that your numbers are candidate safe primes.
The way this was implemented in the project we were working on (e.g., for a 2048-bit RSA key, so 1024-bit primes) was the following:
- Generate a random 1024-bit string.
- Set the first MSB and the last two LSB to 1.
- Test the 1024-bit number obtained for primality; if fail then goto 1.
- Right-shift this 1024-bit number by one bit.
- Test the 1023-bit number so obtained for primality; if fail then goto 1.
- Return the 1024-bit number as a safe prime.
Which is cool but I made the following observation. The method below is probably faster in most cases:
- Generate a random 1023-bit string.
- Set the first MSB and the last LSB to 1.
- Test the 1023-bit number obtained for primality; if fail then goto 1.
- Left-shift this 1023-bit number by one bit and set the LSB to 1 again.
- Test the 1024-bit number so obtained for primality; if fail then goto 1.
- Return the 1024-bit number as a safe prime.
This algorithm looks very similar to the first one above, and for sure it produces the same output, but it's not the same. In fact, when we tested it, it was indeed slightly faster than the first one.
The intuition is the following: testing a 1024-bit odd number for primality is slightly more expensive (and slightly less likely to succeed) than testing a 1023-bit one. You might arguably say that the difference should be minimal (and you'd be right in general), but these 1024-bit numbers are not really random odd numbers: they are all set to be 3 modulo 4, which means that the probability of one of them being prime is even less than what you would expect for a random 1024-bit odd number. So this is to say that, in both algorithms above, the 1024-bit testing is actually quite trickier than the 1023-bit testing.
In the first algorithm you do "the hard work first", by repeatedly doing the 1024-bit testing. But then, when you finally have a positive match, you are not guaranteed that the right-shifted 1023-bit number obtained is still prime - in fact, that's a small chance of it happening. In the second algorithm, instead, first you do a lot of 1023-bit testing, and for each candidate you do the "difficult" 1024-bit testing. The overall number of primality tests is roughly the same, but the difference is that in the first algorithm you do many "hard" tests and few "easy" ones, while in the second algorithm you do many "easier" tests and few "hard" ones.
This difference is enough to be detectable. I don't remember exactly the numbers but I seem to recall something like 2% on a Go implementation - feel free to correct me. So, keep this in mind when you implement your own RSA key generation cryptography - just kidding, don't do that!
Also, this is n00b stuff, I'm sure there is zillion of better ways to generate RSA primes in a much more efficient way.
(Oct 7th, 2023) Shufflecake Accepted At ACM CCS 2023
I can finally break the confidentiality embargo and proudly give the big announcement: The Shufflecake research paper (coauthored with Elia Anzuoni) has been accepted at ACM CCS 2023! We are super excited to present Shufflecake at one of the most prestigious cybersecurity conferences worldwide. A 50-page full version will be available in the next couple of days both on ArXiv and IACR's Eprint. Check the Shufflecake website or the Shufflecake Mastodon for news.
There is a lot of "meat" in the full version, especially regarding future works and planned features. The most pressing point, as previously explained, is the topic of crash consistency. We have ideas on how to do that, but we are still working on implementations.
Many people will probably find the discussion on the topic of multi-snapshot security most interesting. We know that in order to achieve multi-snapshot security we NEED to use WoORAMs, but they are very slow. Our insight is to try to achieve a weaker version, "operational" multi-snapshot security, which (we argue) should be enough in real-world scenarios.
But my favourite topic, and one that I think has been foolishly overlooked in previous literature is the topic of "safewords". What is a safeword in the context of plausible deniability? It's the idea that a user might want to have the "last resort" possibility to surrender to an adversary and prove that she has nothing to hide. The concept would be: If I'm caught by my CS teacher doing non-school activities on my laptop, I can use plausible deniability and be un-prosecutable in front of the principal, but if the police comes knocking at my door, I don't want to get in trouble and I want to comply - and PROVE that I am complying.
With TrueCrypt this is easy: just give up the decoy password to the principal and the real password to the police. In Shufflecake and similar systems that's not so easy, because there are many layers of nested secrecy. So "the adversary does not know when he can stop torturing you" because he cannot trust you whatever you say.
Is this good or bad?
In the paper we make the following points.
- It is actually possible to implement a safeword even on systems such as Shufflecake. It's an easy trick really.
- The idea of a safeword is SUPER BAD for plausible deniability. Not only you should NOT USE a safeword, but the mere POSSIBILITY of having a safeword degrades the operational security of the scheme.
- This problem does not seem to have been addressed before on existing constructions, as all of them (even WoORAM-based ones) have the implicit possibility of creating a safeword.
- We propose an idea to make Shufflecake "safeword-free"! This is future work but it's definitely going to be implemented at some point. The idea is that we can make ANY kind of safeword-like feature impossible by implementing a nice hack to have potentially INFINITE nested volumes (rather than limited by an artificial hard-limit, which is 15 in the current implementation).
I want to expand a bit here on the last idea. Nothing of what I write down here has to be intended as rigorous, this is just the high level intuition. STRICTLY FUTURE WORK!
Currently, Shufflecake packs all the headers (DMB and 15 VMBs) at the beginning of the storage space, and data sections come afterwards in the form of 1 MiB slices. If we want to have the possibility, at least in theory, of having an unbounded number of volumes, then we need an infinite (subject to total storage space) number of headers, and hence we cannot pack them at the beginning of the disk. Clearly, most of these headers will actually be "bogus", i.e. they will not be headers at all, but the adversary should never be sure about that.
So my idea was the following: imagine we don't have a DMB and 15 VMBs, but just a unified, per-volume "header" (encapsulating everything we need for opening the volume, including its encrypted position map), and suppose that this header is one slice large. What we can do is: having the first header (for the first volume) at the beginning of the disk, and the others at random positions across the disk space, interleaved between the other data slices. If everything is encrypted, the adversary cannot tell whether a slice is a data slice or a header, and hence cannot tell exactly how many volumes are there, or even what MAXIMUM number of volumes there can be.
This is cool, it makes safewords impossible! No artificial limit on the maximum number of volumes. But there are challenges.
First of all, how do we "navigate" this chain of headers? We know where the first one is, but what about the others? The idea is to have every header pointing at the position of the next one through a dedicated field. But how about this field? We cannot encrypt it: We would need to encrypt it with the password of the CURRENT header, but then it would be useless for plausible deniability (the adversary will know the position of the next header). We could encrypt it with the password of the next header then. This works if we only have two volumes, but what if we have three instead, and we want to unlock the third one? There would be an unnavigable "gap" in the chain.
My solution is simple: this pointer field is simply left unencrypted, but ANY random string could be a valid pointer. In practice, the concrete idea is to have a random value in the header, say 128 bit, and use it as an input to a linear function which maps uniformly to all slices of the disk: the string "0x0..0" would be the first slice, while the string "0xF...F" would be the last slice, and anything in between would point to other slices linearly. Clearly, random values that are close to each other would point to the same slice, but this is OK. The observation now is the following: even without having any password, the adversary can navigate from the first header to the position of the second, to the third, and so on, but she will not know when to stop, because there will be no way of knowing when the "real" chain is over! The adversary would keep jumping back and forth on the disk like crazy, but no guess on the number of volumes!
Except... three problems.
The first problem is that there actually IS a way for the adversary to know that, starting from a certain point, surely the chain is finished, and she is now inspecting data slices rather than headers. This happens if there is a loop. No header can point to a previous one, so if this random value points "backwards", then we know that something is wrong. But notice that headers will actually be a negligible amount of the disk space, so the chance that a random value points to one of the existing headers is negligible. Sure, it will happen sooner or later along the chain, but we cannot know in advance when. This is sufficient to argue that: in no way a user could use a safeword to "limit" the growth of this chain.
The second problem is: what happens if, during use, modification of a data slice "breaks" the chain? Well, also not a big deal: Notice that Shufflecake would know exactly the position of all unlocked headers, and would treat those slices as permanently occupied, so no risk of overwriting one of those. The only possibility would be to overwrite a "bogus" header, thereby breaking the chain of fake headers. But for the adversary, without the right password, everything is a link of the chain, even the new (encrypted) data slice! So, all that changes is the chain, which (after that slice) might now point to completely new areas of the disk, but this doesn't break anything for the user.
But, wait, then could the adversary know how many "real" headers are there by looking at the state of the chain over time? Yes, this is possible: Every time the adversary sees a change of chain at link N, she knows that the number of volumes is AT MOST N-1, and every observation can shrink down this estimate. This is a problem, but it depends on how often the data slices change, and anyway we are now in the multi-snapshot regime. Things become quickly complicated here, but also solutions multiply. We can use re-randomization (since we use AES-CTR), or we could do some brute-forcing to make sure that the random pointer lands somewhere we want. In any case, the accuracy to which an adversary identifies the real number of headers depends on the number of snapshots she has, which cannot be too many because TRIM is not an ever-growing blockchain...
The last problem is: how about the slice maps? Those are usually larger than a single slice, they can't fit into a single header so defined. True, but nothing changes if the header is 2 slices large, or 3, 4, 5, etc. Just use the same schema: every slice of a header points to the next one, and the last slice points to the first slice of the next header, and so on. This also has the advantage that we can use more or less slices for a header, depending on the size of the device. We also can embed as much volume metadata as we want.
Cool stuff!
(Aug 17th, 2023) Back From Vegas, Black Hat, DEF CON, Shufflecake News, Etc...
Let's try to have a proper post for once after a long time. I'm back from Vegas, from my first Vegas. It was tiring, it was productive, it was exciting, but mostly it was so that I hope it won't be my last Vegas, because I really enjoyed it! Let's see what happened.
I arrived on Tuesday, Aug 8th in the early evening, after a long, boring and uneventful direct flight. The first impression of the city itself was as I expected it: fake, but in a kind of friendly way. Clearly, this only holds for The Strip, which is pretty much the only part I saw. Time was short and packed. I was there to attend Black Hat and DEF CON, my first time for both of them.
I met with other folks from Kudelski Security. The first thing I learned about Black Hat is that the conference itself is just half of the fun: in the evenings, every evening, people go to "parties", which are more or less exclusive networking events with cheap booze and finger food. So, as soon as I arrived at my hotel I barely had the time of changing myself and go to the first evening party of the week! It was good: I quickly entered "undead mode" and managed to stand straight on my feet until around 10 PM, at which point the reanimation spell which was keeping me going faded, and I barely had the energy to crawl back to the hotel and crash. I still woke up at 5 AM and went to have "burger breakfast" at the casino downstairs with a colleague who was as jet-lagged as I was. Reading twice what I just wrote it sounds super weird but, hey, it's Vegas!
Wednesday Black Hat itself started. If I have to describe it with a single word I would call it grandiose. I walked so much my feet still hurt, I am not used to a couple of miles just to walk from the breakfast "room" (more "arena") to the talk room. I have to say, I didn't enjoy Black Hat too much. Too "corporate", talks were less interesting than I expected, and the sight of business people in the vendor booths trying to attract you and subscribe you to their mailing list in exchange for cheap goodies made me feel very sad for them. The other parties I went to varied greatly in terms of quality and fun. I had good times with my colleagues, had my taste of American cuisine, but overall I would not define the first days at Black Hat as very interesting.
DEF CON, on the other hand, was a blast!
A cyberpunk orgy of very special humans and LED lights. Pure chaos, but in a cozy way. People were really friendly, everyone being "as weird as they are", without faking it, and everyone being very friendly and open-minded, or at least this was my experience with the people I interacted with. The only problem with DEF CON is that there is SO MUCH stuff to see and experience, you get quickly overwhelmed by a massive FOMO blast. As much as you can run and scramble from one room to another (huge conference venue here too) there is always something cool you're missing, a riddle hidden somewhere, a secret party, an art performance, a cool talk not listed on the website, etc. Even if you could split yourself tenfold you'd be probably not enough to experience all of it.
My Shufflecake talk at Demo Labs went well, or at least I got a lot of audience and a ton of good questions. Slides available here. Let me also announce with a bit of delay that the latest version of Shufflecake is v0.4.1, with a ton of improvements and new features.
Regarding the future of Shufflecake, I was asked "is this ready for use or still a beta?". This is a good question. I think that, right now, the only thing that is missing in order to consider Shufflecake a "candidate for stable" is the issue of crash inconsistency. There is a lot of other things that should be addressed, sure, but I'd say that crash inconsistency is the nr. 1 issue. This problem is given by the fact that, unlike traditional disk encryption tools like LUKS and TrueCrypt, Shufflecake uses AES-CTR rather than XTS, and explicitly writes fresh IV on disk every time in order to avoid IV reuse attacks, meaning that if a system crash happens between a block write and the write of the related IV you're left with undecryptable data on disk. We do this because we want a feature of "block re-randomisation", which we have plans of using in the future for extending Shufflecake's security to "operational" multi-snapshot adversaries (see it as a "lightweight ORAM"). But, as of now, we do not actually use this feature, which on the other hand gives us 1) performance loss in I/O, and 2) the issue of crash inconsistency. So, we have two ways of addressing this: 1) solving the issue by rendering the block and IV writes atomic. Ther are ways to do it, just with a loss of roughly 11% of space, but we think this would, as a side benefit, improve I/O performance. Or, 2) forget about block-rerandomisation for now, and provide a "lite" mode which uses AES-XTS and will never be able to achieve more than single-snapshot security (but still with all the operational benefits of Shufflecake such as arbitrary filesystems and many nested levels of secrecy). We might actually go for both options and leave the choice to the user, let's see.
There is some other news about Shufflecake, namely about the academic paper for it, but I'm reluctant to share them at the moment, let's still wait a bit. Suffice to say that very soon we should be able to publish a version on Eprint/ArXiv. Stay tuned!
(Jul 11th, 2023) Shufflecake v0.3.0 Released!
Shufflecake v0.3.0 released! This is a major release with tons of improvements! And there is further news coming soon!
(Jul 11th, 2023) I'm on Mastodon
Hell yes, after having escaped the clutches of social media for more than a decade, I decided to give Mastodon a try. You can find me at @tomgag@infosec.exchange but I promise you I will post very rarely.
I've been neglecting this homepage for a while now. Thing is, I'm revamping a bit my "personal IT infrastructure", so I guess I'll try to re-design this website as well. Time will tell.
(Mar 26th, 2023) Change Of Host
I'm moving this website to a new host with Hetzner. SSL certificates changed as well. The new IP is 167.235.145.56
(Jan 2nd, 2023) Happy New Year, Founding De Componendis Cifris
Happy New Year 2776! I've been very busy with personal matters recently, but (together with many other Italian academics and professionals) I found the time to join an important event on December 21st: the official founding ceremony of the newly-formed no-profit Italian cryptographers' association De Componendis Cifris (or, De Cifris in short). Many thanks to the director, Prof. Massimiliano Sala, for organizing the effort.
De Cifris has been already active for many years now, but it was officially formed as a legal entity last month. The reason I decided to join this initiative is that I believe there is both a lack of resources and an abundance of untapped talent in the landscape of cryptologic research in Italy. Even if I'm by now firmly rooted in Switzerland, I'm European at heart, and I always keep an eye on the situation of the motherland. I gladly support actions that can improve the societal, cultural, economical and technological development in the EU, and in Italy in particular.
(Nov 10th, 2022) Introducing Shufflecake: Plausible Deniability For Multiple Hidden Filesystems On Linux
I'm super, super excited to finally announce the first public release of Shufflecake, a plausible deniability tool for disc encryption, aimed at helping people whose freedom of expression is threatened by repressive authorities or dangerous criminal organizations, in particular: whistleblowers, investigative journalists, and activists for human rights in oppressive regimes. You can see it as the "spiritual successor" of software such as Truecrypt and Veracrypt, but vastly improved. Shufflecake is FLOSS (Free/Libre, Open Source Software), source code in C is available on Codeberg (because Github no more, thank you) and released under the GNU General Public License v3.0 or superior.
Releasing this project, and following its development from the beginning until today, was a lot of effort but also really exciting! It allowed me to learn many new things, get my hands dirty with code again after some time, and making myself more familiar with software development in general. And I think the result is really game-changing in the world of privacy, or at least it has the potential to become so. But nothing of all this could have happened without the hard work of Elia Anzuoni. Elia was a MSc student in CS at EPFL (recently graduated), and he applied to the research team where I work at Kudelski Security in search for a topic for his thesis. I pitched the idea for a successor of Truecrypt internally in the team back in 2020 already (my interest for plausible deniable disc encryption software dates back at least to 2011) but so far I hadn't had the opportunity of supervising a student on the project. But with Elia it was a blast! Shufflecake is based on the work of his thesis. Also thanks to his EPFL advisor. Prof, Edouard Bugnion, who had very insightful ideas and recommendations to make the thing work.
Learn more about Shufflecake on the Kudelski Security Research Blog.
(Nov 9th, 2022) A Few Notes On Resetting A Git Repo To An Initial State And Delete Commit History
A few notes for self-reference. When preparing a private repository for public release, sometimes you might want to "clean up the mess" beforehand. The lame solution is to delete the repo and then recreate it through a local copy (spoiler alert: don't). The following commands, harvested randomly through many posts in the interwebz, work well for me:
git pull
git checkout --orphan tmp-main
git add -A
git commit -m 'Initial commit'
git branch -D main
git branch -m main
git push -f origin main
git branch --set-upstream-to=origin/main main
git gc --aggressive --prune=all
git fetch --all
git reset --hard origin/main
(Aug 29th, 2022) A Few Notes On Configuring Apache2 And SSL With ACME
UPDATE 2025-08-10: Fixed serious error: insecure SSLv2 was left enabled by mistake.
UPDATE 2024-07-23: Changed default location of LE SSL certificates.
UPDATE 2023-03-20: Added some extra configuration.
UPDATE 2023-01-06: Thanks to the person who kindly pointed out some possible configuration improvements that give me now a score of "A" on SSL Labs.
Today I finally defeated my laziness and got into configuring HTTPS mode for this and other websites. I am using Apache and Let's Encrypt as a CA, but I don't want to use LE's default "certbot" tool for this. I opted for acme.sh instead, which can do everything I need in a few lines of Bash and without root.
First of all make sure that you have write permission on the webroot directory of the website. In my case this is /var/www/mysite.net . Needless to say, Apache must be configured to support SSL, so at the very minimum do a2enmod ssl. Added bonus since you're at it: do a2enmod headers so you can add MIME and XSS protection later. Make sure to only enable strong TLS ciphers (notice: will break compatibility with some older browsers) by making sure these lines appear in /etc/apache2/mods-available/ssl.conf:
SSLCipherSuite TLS_AES_256_GCM_SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:TLS_CHACHA20_POLY1305_SHA256:TLS_AES_128_GCM_SHA256:DHE-RSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256
SSLCompression off
SSLHonorCipherOrder on
SSLProtocol -all +TLSv1.2 +TLSv1.3
SSLUseStapling on
SSLStaplingCache "shmcb:logs/stapling-cache(150000)"
SSLSessionTickets off
You must also decide where to store key and cert files - don't include them in the webroot. I opted for /etc/ssl/letsencrypt/mysite.net. Finally, make sure that the Apache website entry in /etc/apache2/sites-available/mysite.net.conf has HTTPS enabled and correctly points to the two (not yet created) files key.pem and cert.pem.
<VirtualHost 1.2.3.4:80>
ServerAdmin admin@mysite.net
ServerName www.mysite.net
ServerAlias mysite.net *.mysite.net
# Redirect permanent / https://mysite.net/
DocumentRoot /var/www/mysite.net
<Directory />
Order Deny,Allow
Options -Indexes
AllowOverride None
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
LogLevel warn
CustomLog ${APACHE_LOG_DIR}/access.log combined
Header set X-XSS-Protection "1; mode=block"
Header always append X-Frame-Options DENY
Header set X-Content-Type-Options nosniff
</VirtualHost>
<VirtualHost 1.2.3.4:443>
ServerAdmin admin@mysite.net
ServerName www.mysite.net
ServerAlias mysite.net *.mysite.net
DocumentRoot /var/www/mysite.net
# SSLEngine on
# SSLCertificateKeyFile /etc/ssl/letsencrypt/mysite.net/key.pem
# SSLCertificateFile /etc/ssl/letsencrypt/mysite.net/fullchain.pem
# <If "%{HTTP_HOST} == 'www.mysite.net'">
# Redirect permanent / https://mysite.net/
# </If>
<Directory />
Order Deny,Allow
Options -Indexes
AllowOverride None
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
LogLevel warn
CustomLog ${APACHE_LOG_DIR}/access.log combined
Header set X-XSS-Protection "1; mode=block"
Header always append X-Frame-Options DENY
Header set X-Content-Type-Options nosniff
</VirtualHost>
Notice the commented lines. Enable the website with a2ensite mysite.net if not already enabled. Now check that the configuration looks OK with apache2ctl configtest. If everything looks OK you can restart Apache with systemctl restart apache2. Point your domain name to the server's IP if not done already and make sure that the non-HTTPS version of the website works.
Time to install acme.sh:
curl https://get.acme.sh | sh -s email=me@whatever.com
First of all, close and reopen the terminal. Then let's revert the default CA from ZeroSSL to LE:
acme.sh --set-default-ca --server letsencrypt
Then let's issue the certificates for mysite.net but changing the keysize at least (yes, I still prefer to use RSA over EC for technical reasons I might write a blog post about in the future):
acme.sh --issue -d mysite.net -d www.mysite.net -w /var/www/mysite.net --keylength 4096
Finally, let's transfer the generated certs to their place and specify the apache2 reload command for our installation, which in my case is:
acme.sh --install-cert -d mysite.net --cert-file /etc/ssl/letsencrypt/mysite.net/cert.pem --key-file /etc/ssl/letsencrypt/mysite.net/key.pem --ca-file /etc/ssl/letsencrypt/mysite.net/ca.cer --fullchain-file /etc/ssl/letsencrypt/mysite.net/fullchain.pem --reloadcmd "systemctl restart apache2"
CAVEAT: for the last --reloadcmd parameter, I guess root is required. Technically speaking, it might not be totally necessary, but I'm afraid it will make autorenewal fail. Well, let's see after 60 days what happens, we'll find out. (UPDATE 2022-11-09: I still haven't figured it out whether it works or not, because in the meantime I had to restart apache manually a couple of times, so I'm still not 100% sure)
Anyway, let's complete by removing the placeholder comments on the lines of /etc/apache2/sites-available/mysite.net.conf so to enable the SSL engine (these lines will remove the non-HTTPS version of the website because it's 2023 now), then reload Apache with systemctl restart apache2 et voila'!
(Jul 6th, 2022) NIST Finally Announces End Of PQC Standardization 3rd Round
After a couple of months of delay due to "legal reasons", NIST has finally announced the end of the 3rd round in the PQC standardization process - standardization of quantum-resistant cryptographic algorithms. The first winners of the competition are the following:
- For KEMS, only one: CRYSTALS-KYBER (due to the small encapsulation size, keysize, and fast performance, which makes it substantially a forced choice as a TLS drop-in replacement)
- For signatures, the following: KRYSTALS-Dilithium (mainly due to speed), Falcon (as a fallback in case Dilithium signatures are too large for applications), and SPHINCS+ (because it's just rock-solid and based on completely different security assumptions unlike the previous two both based on structured lattices).
Furthermore, there is other 4 finalists KEMs that will advance to the 4th round:BIKE, Classic McEliece, HQC, and SIKE.
Both BIKE and HQC are based on structured codes, and either would be suitable as a general-purpose KEM that is not based on lattices. NIST expects to select at most one of these two candidates for standardization at the conclusion of the fourth round. SIKE remains an attractive candidate for standardization because of its small key and ciphertext sizes and will continue to study it in the fourth round. Classic McEliece was a finalist but is not being standardized by NIST at this time. Although Classic McEliece is widely regarded as secure, NIST does not anticipate it being widely used due to its large public key size. NIST may choose to standardize Classic McEliece at the end of the fourth round.
Needless to say, this is great news. I was expecting Falcon to win but not Dilithium, which in my opinion is worse under many realistic scenarios, but having both doesn't hurt. I was not sure NIST would standardize SPHINCS+ already at the end of the 3rd round, I think the original idea was to keep it as an alternate, but I'm really glad they decided to go with this one! I think SPHINCS+ is practically unbeatable where security is the #1 concern and statefulness is not an option. I was expecting NTRU Prime to be among the winners, too.
In any case, notice that these are not the only options. For example:
- The German BSI did not want to wait, and already endorsed two algorithms for protecting classified communication:
Due to the urgency of the transition to quantum computer-resistant key agreement procedures, BSI has recommended two of these schemes in its technical guideline TR-02102-1 already at the beginning of 2020 for the first time. [...] The two schemes are the lattice-based FrodoKEM and the code-based Classic McEliece.
- OpenSSH starting from version 9.0 supports the hybrid NTRU Prime + x25519 key exchange method by default:
* ssh(1), sshd(8): use the hybrid Streamlined NTRU Prime + x25519 key exchange method by default ("sntrup761x25519-sha512@openssh.com"). The NTRU algorithm is believed to resist attacks enabled by future quantum computers and is paired with the X25519 ECDH key exchange (the previous default) as a backstop against any weaknesses in NTRU Prime that may be discovered in the future. The combination ensures that the hybrid exchange offers at least as good security.
as the status quo.
- IRTF drafted XMSS, stateful hash-based signatire scheme.
(Jul 2nd, 2022) Webit Impact Forum 2022, Sofia
I had the pleasure of taking part in a panel discussion on "Cyber security and ethical tech" at the Webit Impact Forum 2022 in Sofia, Bulgaria. The discussion was extremely interesting and I wish we had more time - alas, with such a topic we could have talked for hours!. I really enjoyed it and I would like thank the organizers, the panelists, and the moderator for the opportunity!
(Jun 16th, 2022) Change of IP
My host, OrangeWebsite, warned me on June 12th that there would be a change of IP for this host. I guess 4 days of notice must seem like an eternity for full-time sysadmins but as you have probably guessed already I'm being pretty lazy with this... webpage. So, anyway, the new IP is now 82.221.141.53 kthxbye.
(Apr 15th, 2022) "WhatsApp Is Cancer" Explained To Non-Tech People
Disclaimer: I know nothing about Teflon, any example below is purely illustrative.
By now I lost every hope of explaining to friends and relatives why they should steer away from WhatsApp and anything coming from the Cyborg Reptilian Lord. So I am stuck with appeal-to-authority as a last resort, with the following example. Everybody uses Teflon-coated no-stick frypans. Because the material is cheap, ubiquitous, convenient, and we'd waste much more time washing dishes if that wasn't available. But let's say that 9 out of 10 material scientists (or, alas, even 3 out of 10) tell you "you should not use Teflon, but rather this other material that is 10x more expensive and ugly, because there is serious concerns about Teflon's long-term health effects". Let's also suppose that you are not a material scientist. What would you do?
The problem I personally meet when trying to educate people on the technical and social issues of surveillance capitalism is that everybody seems to know more than the material scientists. Because admitting otherwise, and bringing that down to the logical consequences, would mean to stop using Teflon and either to spend more time washing dishes or to go for something more expensive. So, instead of facing the uncomfortable truth, people prefer to convince themselves that the material scientists are wrong, or paranoid, or weird. Or there is always some other excuse: "I only cook once in a while", "I only use low heat", etc.
I don't have a solution for that, but I observe that it's the same process happening when talking to people about climate change, and that the rational solution to improve the current state of things is [uncomfortable truth].
Please stop using WhatsApp. Treat it like smoke: It hurts you and the people around you, it's difficult to quit, it's designed to exploit you.
(Jan 1st, 2022) Can You Sign A Quantum State?
Happy new year 2775! I am happy to announce that, after a looong and suffered publication history, the paper "Can You Sign a Quantum State?", coauthored with Gorjan Alagic and Christian Majenz, has finally been published on the open access Quantum (Journal).
We posted the first version of this paper I think in 2018 on arXiv and IACR Eprint. After that, we tried many times, unsuccessfully, to have it accepted at some well-known IACR conferences. I don't want to rant too much here, but I was a bit disappointed by the reviews we got. My idea is that the paper was "too much quantum" for the audience there, and was victim of the misconception that we were just "rediscovering Barnum et al. (FOCS 2002)". I encourage you to read Barnum et al's original paper on quantum authentication and read our paper and get yourself an opinion. We opted finally for a more "quantum-oriented" venue, and it worked at the first shot!
In a nutshell: As a first result we prove that public-key signing arbitrary quantum states is strongly impossible, meaning that it is impossible even if we extremely relax the security requirements of the signature. In other words: only classical digital signatures exist. The only workaround to this is, if in addition to signing, we also encrypt the quantum state (but even in that case, we cannot get non-repudiation, which is a crucial property of digital signature schemes). The resulting notion is a quantum analogue of signcryption, which was not studied before, while we give definitions, security notions, and constructions.
(Dec 26th, 2021) My Opinion on NFTs
I guess it's about due time I express my opinion on NFTs. In the crypto community I tend to see people pretty divided between two factions: love NFTs and hate NFTs. I must say I see mostly the more "tech" people who hate NFTs, which should already give us a hint. However, I must also admit that I do not have a very strong opinion on this... thing. For me, the idea of NFTs makes totally sense if seen from two perspectives.
The first perspective is best summarized by the following image (credits Joseph C Boone, license CC BY-SA-4.0):
The second perspective is: Suppose you're a crypto millionaire or early investor in Bitcoin/Ethereum or similar, and you own a fortune in tokens. This does not mean that you're sipping cocktails on your private tropical island. What this actually means is that you own tokens that, in the vast majority of cases, must be exchanged for real fiat before they can have an observable effect on your daily life. This means horrible conversion fees on top of the alredy horrible transaction fees, plus most likely withdrawal fees. Add to this that your tokens are by now object of interest for 1) cybercriminals 2) taxation authorities in many jurisdictions. In other words, owning large amounts of crypto tokens is a toxic asset. NFTs are an effective way to get rid quickly of these assets (that you would have hard time spending with other means anyway) and at the same time "recycle" partially their values by building an artificial ecosystem of scarce resources on top of them. As in "you need to own an NFT to access this exclusive party", or "dear employee, part of your bonus will be paid in NFTs".
As I write this, it might sound like I do hate NFTs, but believe me, this is not really the case. Because, I observe, we have been living for long time already in a society that values the possession of things like diamonds, tulip bulbs, fancy cars, gold-plated toilets. So, when you read of "Superstar X spent $500'000 on a limited edition Nike sneakers' NFT", or you see an attractive person on your favorite dating app with the headline "I am looking for a passionate and generous NFT owner who can become the love of my life", my opinion is that you should not think "Oh gosh, this is insane, someone must stop this madness!".
You should rather think: "Nothing new to be seen here, let's move on".
(Jul 21st, 2021) Introducing oramfs: Libre, Storage-Agnostic ORAM Client For Linux
With my colleague and friend Nils Amiet at Kudelski Security we recently released oramfs, a prototype (not production-ready yet) of ORAM client for Linux written in Rust. The code is available on github under the GPLv3 license.
Oblivious random access machines (ORAM) are cryptographic algorithms that can be seen as "compilers", turning an untrusted storage into a trusted one. They can also be seen as improved versions of encrypted filesystems, with slower performance but better security. What is exciting about our approach is that the software is totally storage-agnostic: regardless if you're using a local drive, an SFTP folder, an AWS cloud storage, it doesn't matter: anything that can be mounted as a local directory can be "ORAM-ised" using oramfs, without the need of plugins or server-side support.
Preliminary testing shows (as expected) low performance, but still competitive compared to other existing solutions! Furthermore, it has to be stressed that this is just a proof of concept: we already have, in fact, a lot of ideas for further optimization, and we hope of working on some of these in the near future!
You can also watch our presentation at the Pass The Salt 2021 conference. Stay tuned, we have ambitious plans for this project!
(Jul 21st, 2021) Quantum Indistinguishability For Public Key Encryption
A paper coauthored by Juliane Kraemer, Patrick Struck, and myself has been accepted at the PQCRYPTO 2021 conference and will be presented tomorrow (virtual) by Patrick. Full version available on IACR's Eprint and ArXiv.
I previously wrote about this paper, which was initially titled "Make Quantum Indistinguishability Great Again". I think it might be beneficial to explain a few things about this choice, which apparently angered some reviewers at previous conferences we tried to submit to. This initial choice was dictated in part, undeniably, by the desire of having a "catchy" title, given that we were in the middle of pre-US elections craze that was wrecking everybody's nerves. I want to stress again that this had nothing to do with one or the other political stance of any of the authors, it was just "for the lulz", and frankly we considered this choice totally legitimate given a plethora of other recent and not-so-recent "catchy" titles appearing in the realm of cryptography and beyond.
But the real joke was another one. Namely, in this paper we tackle the problem of defining quantum indistinguishability for (classical) public-key encryption schemes by "resurrecting" an old technique that was previously used in another work appeared at CRYPTO 2016: the use of so-called minimal, or type-2, quantum oracles. Between 2013 and 2016 there was quite a bit of activity on the topic of quantum indistinguishability for classical cryptographic schemes. This activity culminated with the 2016 paper, that was specifically targeting symmetric-key encryption, and no other relevant works that I am aware of appeared after that on the topic (there was further research on quantum security notion for classical schemes, but not about indistinguishability). It was kind of a "quantum indistinguishability winter" after 2016, and in particular the technique of type-2 oracles did not appear anywhere else. That is, until our new paper which first appeared in 2020. So we thought it was funny and appropriate to "make great again" quantum indistinguishability after nobody cared about it for a few years.
Little did we know that our "joke" was about to be ruined: Clearly, it becomes much less funny if, by pure coincidence, two other respectable research groups, concurrently and independently, publish two other very related works that both tackle the very same problem, albeit with different techniques! So it looks like quantum indistinguishability was not dead after all, just hibernating! Surely there was no need of "making it great again".
We only found out about the other two papers after we first submitted our work, and the full version was up and running, so it was too late to change the title. After that, given that the joke was not so funny anymore, and given that the sad circus of US elections was finally over, and given that we had no desire of further angering people, we decided to change the title to something less controversial.
I hope this clarifies, and hope you'll enjoy tomorrow's talk (full video recorded here).
(Apr 22nd, 2021) On Quantum Supremacy, Racial Supremacy, Teapot Supremacy, and Quantum Non-Lameness
Recently, British mathematician Richard Borcherds posted on Youtube a so-called "rant" about quantum computers, specifically about the concept of "quantum supremacy". This video became viral and got my attention. In a nutshell, Prof. Borcherds asserts that the famous quantum supremacy experiment by Google proves nothing, because the problem solved by the Google team was nitpicked to be only solvable on their quantum computer. To prove this argument, Borcherds claims that the problem of guessing how many shards will be produced by a teapot shattering on the floor is arguably intractable for both classical and quantum computers, but trivially solvable by shattering a real teapot on the floor, therefore claiming that this "teapot computing device" achieves "teapot supremacy".
Richard Borcherds is a Fields medalist and very respected mathematician, so one does not dismiss this argument too lightly, even if amusing. But I personally believe that he's really wrong on this one. He used the same argument that I see way too often in random online discussions:
- Mischaracterize the definition of "quantum supremacy".
- Show that something as lame as a teapot or a vial of chemicals also satisfies the definition.
- Conclude that quantum computers are therefore also lame.
The issue with this reasoning (that I tried to point out many times in different places, see for example my post on Kudelski Security's Research blog) is that for a computing device to be meaningful it has to be programmable. That is, it must be able to solve a problem for a large enough range of (classical) input, otherwise it is no more useful than having a table with "problem - result" entries!
It is not necessary that it solves different types of problems (it is perfectly OK to have a specialized computing device that solves only one type of problem, for example addition, factorization, teapot shards prediction.)
It is perfectly OK if the problem is specially engineered to be best solvable on that kind of device, or if the problem has zero real-world applications.
It is even OK if the device only solves problems of a certain instance size (for example, it only factorizes numbers 2048 bits large, or it only predicts sharding of a teapot weighting 500 grams), because worst case scenario you can have a bunch of different devices each of them specialized for a certain instance size - although this is a grey area, because it would be desirable to have a common blueprint for generating designs of different devices for every instance size, a property known as uniformity.
But it must be programmable! For every instance size you must have at least a superpolynomial number of possible admissible inputs, otherwise - again - your device is no more useful than a static table!
Borcherd's teapot mind experiment is not on point, because it is not programmable. You have one teapot, you break it, you count the shards. It is not a "computing device" in any reasonable sense, because there is no input to the problem, you could just note down your observation on a piece of paper "this teapot shattered into 5 shards" and that's all the information you can ever get out of that device. Google's device, on the other hand, is programmable: it accepts as input an (almost arbitrary) description of a quantum circuit up to 53 qubits and up to depth 20 and it estimates the output distribution.
Just after writing this, I found out that Scott Aaronson beat me on time and published a similar rebuttal on his blog - which makes me actually proud :) One interesting question asked therein by Ernest Davis was the following: what if we modify the teapot experiment so it can be made programmable? For example, consider a large industrial machinery complex that does the following:
- Takes as input a classical description (e.g., a 3D CAD model) of a teapot.
- 3D-prints a large number of teapots according to the input and fires them.
- Shatters them on the ground one after one and counts the resulting shards (either mechanically or with A.I. vision software).
- Records the observed results and outputs the probability distribution of shards for that particular teapot design.
Would this account for "teapot supremacy"? My answer is, probably yes, and I see no reason why this should diminish anyway Google's quantum supremacy result. We would have built a specialized machine to solve a specialized problem, it is reasonable that it can achieve supremacy on that problem. The difference with quantum computers is that those can efficiently simulate any classical computer as well, while the teapot machine seems quite limited in its task. Quoting Scott Aaronson about the teapot machine:
I replied that this is indeed more interesting—in fact, it already seems more like what engineers do in practice (still, sometimes!) when building wind tunnels, than like a silly reductio ad absurdum of quantum supremacy experiments. On the other hand, if you believe the Extended Church-Turing Thesis, then as long as your analog computer is governed by classical physics, it’s presumably inherently limited to an Avogadro’s number type speedup over a standard digital computer, whereas with a quantum computer, you’re limited only by the exponential dimensionality of Hilbert space, which seems more interesting.
Or maybe I’m wrong—in which case, I look forward to the first practical demonstration of teapot supremacy! Just like with quantum supremacy, though, it’s not enough to assert it; you need to … put the tea where your mouth is.
On the other hand, I think two things Borcherds is right about are the following. First: it is to be expected that in the future quantum computers will not be used as super powerful versions of classical computers, but rather as specialized add-on devices that augment a classical computer's capabilities - a bit like modern GPUs are specialized hardware for certain tasks.
The second is that, if you think about it, the concept of "quantum supremacy" is a bit underwhelming. You only need to prove that exists: *one* instance size for *one* specific problem that has *no* practical use (and that is specialized for *your* device) in order to claim "supremacy" for your device. And he's totally right on this (but, as I just wrote, he went too far with his argument and did not account for programmability, which makes all the difference.) To which I answer with two observations.
The first is that, for quantum "skeptics" in the community (such as Gil Kalai for example), even this lame definition of quantum supremacy should not be attainable! Skeptics have to understand that denying the feasibility of quantum supremacy is a very difficult task, exactly because the definition is so underwhelming! If you are a non-believer in quantum supremacy, then not only you claim that quantum computers will never have an edge over classical computers for practical problems, but you are claiming that, no matter what the problem and instance size at hand, classical will always be better or roughly on par with quantum in performance. So, think twice before taking this stance. I am looking at you, uneducated Dunning-Kruger commenter on Slashdot.
My second observation is that in my opinion all these misunderstandings are due to the unfortunate choice of the word "quantum supremacy", because it gives false expectations to the non-expert audience. I think clear communication is important, not only in science, and that words should not just be placeholder symbols to represent a concept and to be decoded with the right "knowledge key", but should be understandable also by the largest possible audience who does not possess such key. A typical example I often rant about is "post-quantum", which I think should receive an award for "worst possible vocabulary choice in science." When we talk about "post-quantum", for experts in cryptography it is perfectly clear what we're talking about. The threat model is clear, the scenario is clear, the object of discussion is clear. But for the rest of the people on the planet it is a pain. This word is so prone to misrepresentation that I stopped using it altogether, preferring the term "quantum-resistant".
There was a discussion some time ago (that I won't link here so to not further feed the fire) on the fact that we in the quantum community should stop using words such as "ancilla qubit" and "quantum supremacy" in physics because they can offend people and bring despisable racial or slavery connotations. Back in the time, I was of the opinion that we should dismiss this argument as nonsense and stick to the commonly accepted scientific vocabulary. However, now I changed my mind for what concerns "quantum supremacy" - and, mind you, not for the politically correct reasons above. The reason is that, as I wrote, I think it's a too much strong word for something that it's actually the *very minimum bar for a computing technology to be vaguely interesting* and therefore gives false expectations to most of the audience. I think we should use a different word.
I suggest "quantum non-lameness".
(Apr 8th, 2021) Is Signal Turning Evil?
Like many other security people and tech-savvy users, I am deeply concerned by the announcement that Signal is experimenting with in-app cryptocurrency payments.
Signal Payments makes it easy to link a MobileCoin wallet to Signal so you can start sending funds to friends and family, receive funds from them, keep track of your balance, and review your transaction history with a simple interface.
Others have written already why this is a terribly bad idea. Personally, for me this marks the beginning of the end of my love for this fantastic app. I have been using Signal for a long time, and helped relatives and friends in the process of migrating to a better and safer alternative to Whatsapp, Telegram, Threema, whatever. But this just feels so wrong, and I am not even a blockchain hater!
I wish I am mistaken, but to me it looks like things can only go downhill from here. I will start looking at alternatives, either peer-to-peer or federated this time. Signal for me has always been a temporary solution - at the end it's just Whatsapp run by someone less evil than Facebook - but this just feels bad.
(Apr 8th, 2021) A Dangerous Vulnerability In Existing Gennaro-Goldfeder’18 Implementations
Threshold signature schemes (TSS) are a class of complex cryptographic schemes that have seen a growing interest and rapid adoption in the last few years, mainly driven by blockchain applications such as Bitcoin. They allow to reduce the risk profile of wallet management in large organizations, and are especially attractive in highly regulated environments such as exchanges and financial institutions. The sheer complexity of many of such schemes, however, makes them prone to implementation and design issues.
During a cryptographic code audit of one of these applications at Kudelski Security, we found a potentially serious vulnerability in one of the most widely used ECDSA TSS protocols: Gennaro-Goldfeder'18. The vulnerability is actually an extension of another known vulnerability, the "forget-and-forgive" attack, and stems from the necessity of a security assumption in the original protocol that is not given for granted in many real-world cases. This problem might allow a single malicious attacker to delete or lock funds and blackmail all other peers. Special kudos to Yolan Romailler (@anomalroil on Twitter) for this.
More information is available here and the original report can be found here. No reason to panic: the vulnerability is application-specific, and does not depend on the implementation of the most widely adopted GG18 libraries, but still something to keep an eye on.
(Apr 3rd, 2021) In Support Of Richard Stallman And The Free Software Foundation
Just a brief post to express my support for Richard Stallman (rms) and his return to a leading role within the FSF. I admit the more I read about this sad story, the more I am disgusted by what to me looks so far like an orchestrated attack to the use of proper language and rationality, and an ad hominem case against a person guilty of not conforming to a corporate promiscuity thinly veiled as political correctness.
I am not a fan of rms. I do not worship him nor FSF. I cannot vouche for him being a good fit for his role within FSF, not even for being a nice person, or being a person I would like to work with. But the arguments that have been used against him are frankly horrifying. Not laughable, really just horrifying.
But, hey, there might be some backstory I am not aware of. Feel free to change my mind. Please use different arguments from what I've read so far though.
(Mar 5th, 2021) No, Peter Schnorr Did Not "Destroy RSA"
The cryptographic community was, let's say "stirred" in the past few days, by a paper appeared on the IACR's Eprint authored by famous cryptographer Peter Claus Schnorr (yes, the guy from Schnorr signatures). In the paper, Prof. Schnorr claims to have found a (classical, not quantum) lattice sieve reduction method that quickly factorizes large integers, and thereby "destroyes RSA" (sic).
The paper is short but dense, and I think most cryptographers in the world aged a couple of years during the last week. However, the claim is apparently incorrect as there are serious flaws in the paper.
I had the pleasure of meeting Prof. Schnorr at various conferences and workshops, I even shared a bus ride with him at the 2015 Dagstuhl Seminar on Quantum Cryptanalysis. I recall him as quiet and full of energy and charisma at the same time. I won't add anything to what has already been said, see for example here and here. If you are looking for an explanation of what happened behind the curtains, I cannot give you one.
However, I guess you might want to read about the sad story of Sir Michael Atiyah's attempted proof of Riemann's hypothesis.
(Mar 5th, 2021) My Podcast Interview With Mysecurity Media
I gave a podcast interview at the Cyber Security Weekly Podcast for Singapore-based IT news outlet Cybersecurity Media. Working with Jane Lo was a great pleasure. I was impressed by how, unlike too often the case in "cheap" press, she did due research and preparation beforehand and we could easily navigate together a complex topic such as quantum security.
Fun fact: a few seconds after I start talking you can hear my doorbell in the background. That was the mailman, arriving at the very wrong moment!
(Dec 23rd, 2020) Android / Lineage OS: How To Separate Screen Lock Password From Storage Password (Different Password)
UPDATE 2021-04-25: Unfortunately I have realized that this method does not work with new devices! In my case it was working because I was installing an Android 11 based ROM on an older device (Samsung Galaxy S4 mini), but for modern devices and since Android 10 it is mandatory to use File Based Encryption (FBE) rather than Full Disk Encryption, and this makes it impossible to have two separate passwords (don't ask me why, I have no idea, sounds ridicously dumb to me.) Thank you again, Google!
Just a quick note for those of you who have recently installed Android 11 or a ROM based on it such as Lineage 18 and are struggling setting up a storage encryption password different from the screen lock one. I recently had troubles myself doing so, hence these notes to show you how to do it. Why you want to do it? Basically the idea is to use a short PIN/pattern/passphrase to unlock the screen for ease of use, and a very long and complex one to decrypt storage at boot. Then you need to install an app such as Wrong PIN Shutdown (needs root) that powers off the phone after, say, 3 failed attempts at unlocking the screen. This way if someone steals your phone and starts fiddling with it, very soon they'll find themselves locked out. Notice: this is of course useless against a forensic analysis or other forms of attack, so it pretty much defends only against this specific case. Still, it pisses me off that Google decided that somehow every Android user does not need to decide by themselves how to use this feature, and opted to link the screen unlock and storage encryption keys by default to make it easier to manage. So much in fact that with the last updates it has become even more difficult to work around this limitation. A nice app that I used before to do this, Cryptfs Password (also available on F-Droid) stopped working some time ago already. The reason is that it is basically a script invoking the cryptfs command, whose syntax has changed.
So, here is how to do it (spoiler: requires root)
- Fresh install your ROM (e.g. Lineage) and root it (e.g. Magisk)
- At setup, choose a short PIN for screen unlock
- Settings -> Security -> Encryption -> Encrypt Device (requires fully charged battery and device under charge, when requested to enable "boot lock" choose "yes", phone will reboot)
- Install F-Droid, install a terminal emulator (e.g. Termux) and Wrong PIN Shutdown
- Fire up the terminal and do this:
su
vdc cryptfs changepw TYPEOFNEWPASSWORD OLDPASSWORD NEWPASSWORD
where TYPEOFNEWPASSWORD can be any of password, pin, pattern (if you use a pattern, match the position of the dots with corresponding numbers on keypad to obtain a numeric string)
This solution appeared here and here. Enjoy!
(Dec 8th, 2020) Coming Soon: My Talk At Black Hat Europe 2020
I am excited to give a talk at Black Hat Europe 2020 (virtual conference) on December 10th (in two days) on the topic of quantum security and quantum cryptography (not quantum key distribution, the "real" stuff!). If you think that's an unorthodox topic for Black Hat... You're totally right! So, stay tuned!
(September 10th, 2020) My Opinion On Covid-19 Contact-Tracing Apps
Update 2020-10-01: there is a new paper by the University of Salerno crypto group that describes further possible "terrorist attacks" that can be mounted against decentralized apps (in particular focusing on SwissCovid and Immuni) by leveraging smart contracts. Also, I corrected some broken links in the post.
Disclaimer: what follows is a personal opinion, and it does not necessarily represent the point of view of my employer or my colleagues or collaborators or pretty much anyone else.
Foreword: if you are one of the many who think that vaccines cause autism, that Covid does not exist, that face masks hurt your freedom, that the pandemic is just a huge lie orchestrated by Soros and Bill Gates to implant us with microchips and control our minds with 5G, and that sun and good vibes can cure any disease, please stop reading now: this post is not going to be helpful for you, sorry.
I think contact-tracing apps are a bad idea, and mark a dangerous path that we should all steer off from. In this post I will try to explain why, given that I received questions from many acquaintances who cannot understand how a moderately "socially conscious" person like me could be so vocally against this technology. At times I even had to clarify that I am in no way an anti-vaxxer or a Covid-denialist.
I should have written this way earlier, it feels a bit weird to do it now that the heat for this coolyoungtechthing is waning off and almost nobody is talking about it anymore. But better late than never, and it also allows me to put in retrospective some early foresight that I gave verbally to many friends and colleagues in the past.
There are four aspects that I will touch in this post: privacy, security, effectiveness, and sociopolitical implications. You might be surprised to know that my personal concerns follows this list in the reverse order in terms of severity. I will first give a succint explanation of my opinion on these four points (a TL;DR version), then I will go in more detail through them, and finally I will conclude with a FAQ section.
In short:
Privacy: all these apps are not 100% "privacy-preserving", even the decentralized ones expose the users to certain privacy risks. Most importantly, they only work on non-free software/hardware solutions that expose the user to further, more serious tracking.
Security: none of these apps has been audited satisfactorily, and there is a general short-sighted attitude of "f..k security, this is an emergency!". Most importantly, these solutions require to adopt non-trusted mobile platforms such as Google Android and Apple iOS that take away control from the people in favor of foreign megacorporations who do not share the best interests of their users.
Effectiveness: these apps are not good at slowing the spread of the disease effectively, both for technical reasons and for usability reasons. Previous experiments have shown (and the phenomenon is repeating again) that even in the case of an initially rapid mass adoption by the userbase, an abandon phase follows shortly, where users simply uninstall the app.
Sociopolitical: this short-sighted approach pushed by various authorities and blindly emphasized by the media shows on one side a dangerous divide between different scientific sectors (from my point of view, in particular it shows a dangerous cyber-illiteracy or lack of attention for privacy/security by the medical community.) On the other side it shows a global political will to normalize (even if with a "soft" approach) a doctrine of mass surveillance and technological control that it is so far achieved only in one large Asian country - may I add, with horrifying consequences.
I will now explain more in depth the points above.
Let's talk first about privacy, which is frankly one of the least important issues in the emergency caused by a devastating pandemic. There will surely be people ready to educate me on the difference between centralized VS decentralized approach, how the latter is so much better and even endorsed by academic institutions and so on. I am well aware of the differences. Let me put it straight for you: saying that decentralized apps like SwissCovid or Immuni are "privacy preserving" is a blatant lie - they are not even "decentralized" in fact. This can be shown in math, and if you claim otherwise then you are the uneducated one.
Both approaches (centralized and decentralized) have pros and cons, in terms of privacy and abuse potential, and which one is better depends on your security model. This has been pointed out very vocally by Serge Vaudenay (a world-renown cryptographer and professor at EPFL) in this paper, formalizing and echoing what was already a growing concern in part of the cryptographic community.
Without going too much into the details, the problem is twofold: on one side, all these apps still process certain data through a centralized authority that has thus quite a lot of control on the information associated to patients (albeit less than in a fully centralized approach). Second, the apps broadcast encrypted data that can be gathered and unmasked when a user tests positive by a so-called "paparazzi attack". This is quite troublesome because it targets specifically those users who, arguably, need more privacy protection. Notice how this attack is actually not possible in a fully centralized solution, so this is a typical example of security trade-off.
I think one of the best explanations of the technical issues with contact-tracing apps is this short video by Prof. Ivan Visconti (in Italian).
Another exhaustive resource on the issue is maintained by the EPFL crypto group: The Dark Side of SwissCovid. Please read it, it is really well-written, so much in fact that the best I can do is to quote part of it:
In summary, our report shows that
- a big part of contact tracing is outsourced to the Apple-Google implementation;
- the Apple-Google implementation has no public source code (at least until July 21);
- Amazon is implementing part of the server infrastructure;
- the available information is unclear, incomplete, or incorrect;
- some previously identified attacks are still feasible.
Our compliance analysis concludes that
- the switch from the pre-standard version to the Apple-Google-based one made SwissCovid not compliant with the law;
- the implementation of DP3T has bypassed the law;
- the law was shown to be powerless to protect people from using a non-transparent contact tracing system.
Let's not talk about the fact that all these apps can only be downloaded through "trusted" (note my sarcasm) stores such as Google Play or App Store. Remember that these platforms do not respect your rights and give an unlimited control over your digital life to evil megacorporations. By using these services "for free" you are actually working for free for them. Refuse to be used, choose a solution "Free as in Freedom" rather than "free as in beer".
Which brings us to the second problem: security. Privacy and security are often interconnected but they are not the same thing. Installing these apps on your phone is equivalent to installing a black box of obscure code that can do literally anything code can do, without the user having any control over it. How much do you trust Google? Even if you do, how much you trust the programmers who wrote the app? As part of our job, my colleagues and I routinely audit cryptographic code. Not all the results of our audits are public, and I can tell you that very often I am horrified by the bad coding practices and exploitable bugs one can find in software allegedely written by top-tier programmers. I will talk anecdotally here: I know that a certain contact-tracing app has not undergone a complete code audit for cost reasons, and some of the security issues identified have not been deemed worthy to fix. This is not surprising: in an emergency, nobody has ever time to do things properly. On the other hand, there are a lot of economical and political interests for developing and adopting these apps, so they will be given a pass even if their security is shabby. To summarize this point: installing these apps on your phone enlarges the attack surface that can be exploited by the bad guys.
But then of course there is the usual argument: even if these apps are insecure, even if they are not perfect, don't you think they serve a useful cause? My answer is: no, actually I think they do not serve anything useful at all because they just do not work. This has been brilliantly summarized by famous public interest technologist Bruce Schneier, whom I will quote here:
“My problem with contact tracing apps is that they have absolutely no value [...] I mean the efficacy. Does anybody think this will do something useful? … This is just something governments want to do for the hell of it. To me, it’s just techies doing techie things because they don’t know what else to do.”
There are so many things that do not work with contact tracing apps that I don't even know where to start. First of all, the app cannot detect contact with infected surfaces or exposure to aerosol, both of which have been proven to account for a large part of infections. Poor ventilation in closed spaces accounts for most of the "superspreader" events: infection in these cases has been reported to distance much greater than that reached by Low Power Bluetooth technology used by contact tracing apps. Moreover, the app does not broadcast continuously (that would drain the phone battery pretty fast) but only at intervals of 10-15 minutes. All this means a lot of false negatives, but there are also a lot of false positives, because the app for example doesn't know if there was a plexiglas shield between you and the cashier at the supermarket who subsequently tested positive, and even if you were in close contact with an infected person the infection rate is not 100%. Again, Bruce Schneier summarizes it best:
Assume you take the app out grocery shopping with you and it subsequently alerts you of a contact. What should you do? It's not accurate enough for you to quarantine yourself for two weeks. And without ubiquitous, cheap, fast, and accurate testing, you can't confirm the app's diagnosis. So the alert is useless.
Similarly, assume you take the app out grocery shopping and it doesn't alert you of any contact. Are you in the clear? No, you're not. You actually have no idea if you've been infected.
The end result is an app that doesn't work. People will post their bad experiences on social media, and people will read those posts and realize that the app is not to be trusted. That loss of trust is even worse than having no app at all.
It has nothing to do with privacy concerns. The idea that contact tracing can be done with an app, and not human health professionals, is just plain dumb.
Notice this is exactly what has been observed in the userbase so far, both for SwissCovid and Immuni: the first days after the app's release we got hit by big news of "millions of downloads in a few hours": people got curious, installed the app, realized it's trash, and uninstalled. This is a funny read (in Italian) about what happens to your life when you get a notification of exposure.
But to tell you the truth, all of the above are just a nuisance for me compared to what in my opinion is the greatest Issue with contact-tracing apps: the idea that I need to carry a smartphone with me (and one running a non-free OS specifically designed to track and manipulate users) in order to conduct a normal life.
In case you were not paying attention: this is what leads us all to Damnation and down the China model. It is a trick used countless times in history, and I am really puzzled how we are still blind to it: even the dumbest People on Earth will rebel to power if deprived of all freedom at once, but will behave sleepy and peaceful if the same freedom is constantly eroded and slowly stripped away. Here's what happened in China: You might have heard of a smartphone app called WeChat, it is not very popular in the West but it is literally impossible to live in China without it. It is a voice/IM app, news feed, payment system, collaboration platform, all in one. It is heavily controlled by the government, with which it shares private information of every citizen and tracks people all around the clock. It is literally The Orwellian Nightmare. For this reason, its mandatory adoption has been pushed heavily by regulators: you cannot call a taxi or do groceries without it, you cannot get housing or schooling without it, you are basically a ghost in society. And when last week I've heard from friends that some bars here in Zurich started denying entry to patrons who don't have SwissCovid installed, I felt a little bit that way. I'm sure it's somehow illegal (at least here in Switzerland) to deny entrance to a public venue depending on a smartphone app, but people are doing it anyway, on the basis that you cannot protest against such a clearly thoughtful decision, you would be a bad person otherwise.
Contact-tracing apps produce various dangerous sociopolitical phenomena. On one side, suddenly everybody seems to have become an expert in contact-tracing technology. On the other side, they polarize people so much that even in the scientific community many are blind to their implications. Medical experts showed support of these apps, but just because for them it makes life easier - they don't think of the deeper ramifications. I mean, it would be great for ME personally if access to the whole Internet was shut down to anybody who cannot prove an academic instruction in cybersecurity or related fields. But, seriously doc, can we have a discussion about this?
Ultimately, the problem is that "better to do something than do nothing" does not apply in cybersecurity: in many cases it is literally better to do nothing, because a careless cure can easily be worse than the disease.
I apologize if you got angry reading this, but I really think the fear of the virus has put critical thinking too much on a second place.
Answers to questions I receive frequently:
Q) Even if these apps are only 10%, or even just 1% accurate, don't you think they are better than nothing?
A) Let me correct myself: "better to do something than do nothing" NOT ONLY does not apply in cybersecurity. Wouldn't it be a good idea to ban all bikes since they cause accidents? You always have to weight in the costs VS the benefits. An app that is 10% effective does NOT weight favorably compared to the many drawbacks I explained above. So, ultimately no: I don't think they are better than nothing.
Q) But the doctors know better, don't you think?
A) The doctors know, on average, NOTHING about cybersecurity, or even UX. They know that these apps can slow down the spread of the virus, fine. But they don't know *how much*, they do not consider that people are people rather than robots, and they have no idea of the costs and risks of the technology. Just to be clear: this has nothing to do with the seriousness of the emergency, which I do not deny. Even if Covid-19 were a terrible death sentence at any age range, contact-tracing smartphone apps would still be a terrible idea to mitigate the problem.
Q) Don't you think you are putting your paranoia before public health?
A) I explained above how the privacy issue is the *least* of my worries here. I know it's a boring read, sorry for that, but please read again.
Q) But then what do you think is the reason why authorities are recommending these apps?
A) This is a good question, I think there are many answers. On one side, control. I think many governments see this as a "test", to check how further down the China path they can go without people being pissed off. On another side, personal incentives: companies have interest in designing and selling these solutions, Google and Apple have interest in strengthening further their mobile market dominance by embedding the functionality at low-level in their OSes, academics have interest in having their names on safety reports or research papers on the topic. And then, of course, the omnipresent desire of virtue-signalling: "Hey, look at me, I want to support this because it is a Good thing and will make the world a better place" - shouting is less effort than actually doing something, no?
Q) Are you also against the use of face masks?
A) No.
Q) What triggered you in writing this post?
A) Mainly that people became super fascist and/or partisan in advocating something they know nothing about. But also the fact that apparently in the modern, anti-intellectual society we live in, working and having a formation in a certain field does not help in having your opinion on the matter being heard. "My ignorance is as important as your knowledge" has become the new mantra here, and I blame social media for this.
(July 29th, 2020) NIST Announces Finalists for the 3rd Round PQC Competition
A few days ago NIST published the list of finalists for the 3rd round of the PQC competition. I'm a bit disappointed that NIST apparently prioritized a lot performance over (estimated) security, but I guess it had to be expected, after all we need standards that must be suitable for a broad range of applications.
EDIT 2020-08-23: Just to be clear, my comment above is not to be meant as a criticism to NIST, they have very smart people evaluating the candidates and I'm sure they are taking very rational decisions.
(May 13th, 2020) Adiabatic Quantum Computing News
There is some big news announced related to the kind of quantum computing technology (adiabatic QC) developed by companies such as D-Wave. For a long time it has been unclear whether such technology could even just in theory be better than a classical computer or not. Now it looks like the answer might be yes. From Scott Aaronson's blog:
"Matt Hastings has announced the first provable superpolynomial black-box speedup for the quantum adiabatic algorithm [...] the first strong theoretical indication that adiabatic [...] can ever get a superpolynomial speedup [...] over all possible classical algorithms"
What it means: basically we cannot say anymore that adiabatic QC is a scam. We still have no evidence, as far as I know, that quantum adiabatic annealers are really useful quantum computers, so someone might say that for what concerns the practical aspects they are still snake oil, and also notice that the scientific paper mentioned above does not give evidence of adiabatic QC being able to solve any real world problem (just a theoretical one with no applications). But still, it means that from now on adiabatic QC is also something we cannot dismiss as pure BS (even if it looks very unlikely that it could have any implications for cybersecurity).
(March 20th, 2020) Personal Coronavirus Update
Just a quick update to say that (luckily) neither I nor my relatives and friends have been so far affected by the infamous virus. I am certainly worried for the virus itself, but I am actually more worried for the panic that it is causing. This brings not only infamous cases of mass hysteria (toilet paper, seriously?), but also vigilantism, intolerance, and willingness to trash any form of civil liberty and understanding of each other's feelings and needs in name of "the emergency situation". To me, this looks like 9/11 psychological effect all over again, and sure thing I would not enjoy to see it happening. That's not to say that people should be careless (please, be safe and make others safe), but welcoming a new wave of fascism and authoritarianism in exchange for a false sense of security is definitely not a good idea.
(March 8th, 2020) Upcoming Speaking Engagements
Provided they do not get canceled because of the spread of the coronavirus CoVid-19, here are my upcoming speaking engagements.
On March 11th I will be in Paris for the Deeptech Week, speaking at an event called "Quantum Cyber-Security : Impact And Challenges".
(March 8th, 2020) Make Quantum Indistinguishability Great Again
New paper together with Juliane Krämer and Patrick Struck from TU Darmstadt, currently online on Eprint and arXiv. I think the results are pretty cool: basically we show that so-called "type-2 operators" or "minimal oracles" for encryption are, perhaps counterintuively, very natural for many real-world quantum-resistant schemes. This allows to define a sound notion of quantum indistinguishability where the challenge phase is quantum, and the new security notion is strictly stronger than commonly used ones but at the same time achievable by "natural" schemes such as the barebone LWE encryption.
Needless to say, the title is purely ironic (but it actually also fits what we are doing, as we "resume" old ideas from CRYPTO 2016 that were kind of abandoned since then).
(March 8th, 2020) Old Article on 01.net
I decided to copy on this webpage, just for the sake of keeping records, articles I previously wrote for other venues. The following appeared in June 2018 on Italian language news website 01.net.
La sicurezza dei dati quantistici nell’Internet del futuro
Tommaso Gagliardoni, 28 giugno 2018
Supponiamo per un momento di ritrovarci improvvisamente nel 1968. La prima cosa che notereste (ovviamente!) è che avreste delle serie difficoltà a leggere questo articolo. Uno dei più potenti supercomputer dell'epoca, l'IBM System/360 Model 85, aveva l'equivalente di ben 4 megabytes di memoria. Era un gioiello di tecnologia, incredibilmente veloce e costoso, tanto che solo poche grandi istituzioni al mondo potevano permettersene uno - ne sono stati prodotti 30 esemplari. Consumava "solo" 4 kW di elettricità, ed era probabilmente più piccolo della vostra cucina. Probabilmente.
Oggi, nel 2018, portiamo nella tasca dispositivi grandi come il palmo di una mano che sono di diversi ordini di grandezza più performanti di tali antiquati behemot, e li usiamo quotidianamente per accedere a una Rete globale in grado di scambiare quantità mostruose di dati. Una rete anzi, a cui tutto oggigiorno è connesso e da cui tutto dipende.
Viviamo in "tempi veloci": 50 anni cambiano molte, molte cose, soprattutto dal punto di vista del mondo IT. Diventa quindi naturale fare il paragone con quelli che oggi sono i primi futuristici prototipi di computer quantistico. Macchine estremamente sofisticate, costose, ingombranti e complesse, avanguardie di una tecnologia rivoluzionaria. Tecnologia che, per quanto indubbiamente giovane, sempre con meno confidenza può definirsi allo stato "embrionale".
Negli ultimi anni si è assistito a una vera e propria esplosione nel campo della ricerca in quantum information processing. Cose che potevano sembrare fantascienza agli inizi del secolo sono ora a portata di mano: riusciamo a spedire e misurare informazione quantistica a centinaia di km di distanza, a correggere in maniera affidabile molti errori di trasmissione e si è passati in breve tempo dal contenere a fatica un singolo qubit ("bit quantistico") ad avere macchine che di qubit ne hanno poco meno di un centinaio.
Considerando che secondo molti ricercatori 90-100 qubit sono il limite oltre il quale un computer quantistico può effettuare operazioni impensabili con il più potente supercomputer classico, la sensazione generale che si ha è che probabilmente non ci sarà bisogno di aspettare ancora 50 anni per assistere a quella che si preannuncia come una nuova rivoluzione informatica e tecnologica.
Bisogna quindi guardare al futuro e iniziare a considerare seriamente quali possibili scenari potrebbero conseguire da questa rivoluzione.
La sicurezza dei dati quantistici
La disciplina della crittografia è tradizionalmente vista come un'area che potrebbe venire impattata in maniera drastica dall'avvento del quantum computer. La possibilità teorica dei computer quantistici del futuro di poter compromettere cifrari che sono oggi usati ubiquitariamente per rendere affidabili infrastrutture critiche è vista come una minaccia globale, per difendersi dalla quale negli ultimi anni si sono moltiplicati gli sforzi di governi e istituzioni pubbliche e private.
Le aree di ricerca della cosiddetta crittografia quantum-safe e crittanalisi quantistica si occupano di preparare le infrastrutture moderne (Internet in primis) a uno scenario futuro in cui computer quantistici in grado di forzare le protezioni crittografiche moderne saranno a disposizione di pochi ma potenti attori - anche se non necessariamente a disposizione del resto della popolazione.
Tale scenario sembra non configurarsi più oramai come qualcosa di troppo remoto, nè troppo futuristico, ma la buona notizia è che già oggi disponiamo di soluzioni adatte. Ad esempio in IBM Research, dove lavoro, stiamo sviluppando e perfezionando un tipo di schemi crittografici che protegge i dati codificandoli all'interno di complessi problemi matematici (strutture algebriche) chiamati "reticoli" ("lattices" in inglese).
Questi problemi sono così difficili che si stima che neanche un potente computer quantistico del futuro sarà in grado di risolverli. Ciò è molto utile per noi crittografi, perché significa che possiamo proteggere già da oggi i nostri dati in uno scenario in cui i computer quantistici diventeranno abbastanza forti da rompere la sicurezza degli schemi tradizionali odierni. Ovvero, non è necessario (né consigliabile!) attendere lo sviluppo di quantum computer potenti per iniziare a migrare le nostre infrastrutture verso una sicurezza a prova di futuro: i nostri schemi di crittografia quantum-safe sono ormai pronti per l'adozione su larga scala e sono già entrati nel processo di standardizzazione. IBM Research è alla continua ricerca di partner interessati a far parte di programmi pilota in questo senso.
Guardare al futuro però significa guardare anche oltre tale scenario. Magari traendo ispirazione proprio dalla storia del calcolo moderno.
Proprio come agli albori dell'era informatica solo poche grandi organizzazioni potevano permettersi di lavorare con un computer, oggi solo poche grandi aziende e centri di ricerca dispongono di un prototipo di computer quantistico. Ma, come tutti noi sappiamo, storicamente questo stato di cose non ha avuto vita lunga: la potenza di calcolo a disposizione è andata aumentando, e ben presto i primi computer sono stati connessi tra di loro, all'inizio in piccole reti, che sono poi cresciute man mano, a formare quella che oggi è la rete delle reti: Internet.
Allo stesso modo, non appena i computer quantistici cominceranno a diffondersi su larga scala, sarà naturale connetterli tra di loro: la tecnologia necessaria a scambiare dati quantistici esiste già e non serve quindi un grande sforzo per immaginare una "Internet quantistica" del futuro, in cui dati quantistici vengono codificati in pacchetti d'onda, fotoni, o particelle, e scambiati da quantum computer a quantum computer a velocità folli tramite laser, o fibre ottiche, o quant'altro la tecnologia del futuro potrà metterci a disposizione. Dopo l'evoluzione quantistica della tecnologia dei computer, una rete per lo scambio di dati quantistici sarebbe la naturale evoluzione delle reti dati moderne.
Tra il dire e il fare c'è di mezzo il mare. Lasciamo da parte per un momento le sfide ingegneristiche e tecnologiche da risolvere per arrivare a realizzare una "quantum Internet", di cui senza una sfera di cristallo possiamo dire ben poco. I problemi da risolvere sono prima di tutto di natura squisitamente teorica.
Il punto è che, come ormai noto da più di un secolo sia nel campo delle discipline fisico-matematiche che ingegneristiche, l'informazione di tipo quantistico si comporta in maniera peculiare, del tutto controintuitiva rispetto ai "dati digitali" classici a cui siamo abituati e su cui i computer tradizionali lavorano, a causa delle leggi fisiche della meccanica quantistica. Progettare una "Internet quantistica" richiederà prima di tutto capire come gestire questi comportamenti "anomali".
Ad esempio, l'informazione quantistica non può essere copiata - quindi risulterebbe difficile effettuare un backup, o un log del traffico. Oppure: dati quantistici possono entrare "in interferenza" tra di loro, cancellandosi o rafforzandosi a vicenda - non solo durante la trasmissione ma anche durante il calcolo. Tutte queste caratteristiche, così "aliene" al nostro modo moderno di concepire le reti di dati, significano che ci sarà bisogno di approcci e protocolli di trasmissione completamente nuovi. Bisognerà rivedere il modo in cui i dati vengono rappresentati, codificati, trasmessi, manipolati. E protetti.
Infatti sarà importante non ripetere gli errori del passato: quando le prime reti di computer sono state create, la sicurezza delle comunicazioni non è stata considerata una priorità. Internet stessa non è stata strutturata pensando alla sicurezza: protocolli per cifrare e autenticare i dati in transito sono stati aggiunti solo in un secondo momento, "a strati", con difficoltà tecniche notevoli di cui ancora subiamo i contraccolpi.
Oggi sappiamo quanto sia un errore tralasciare la sicurezza. Nel creare una Internet quantistica, un ruolo fondamentale dovrà avere la crittografia: quello che servirà saranno protocolli quantistici (da far girare su un quantum computer insomma) in grado di garantire sicurezza, privacy, autenticità, e integrità dei dati. Tali protocolli dovranno lavorare nativamente su dati quantistici, per cui le tecniche crittografiche moderne (inclusa la crittografia quantum-safe) non saranno di aiuto: serviranno schemi completamente nuovi.
Quantum security
La ricerca che porto avanti nel gruppo di Security & Privacy allo Zurich Research Lab di IBM è nel campo della "quantum security". La quantum security è lo studio matematico della sicurezza delle informazioni in presenza di processi quantistici, di qualsiasi tipo. Questo include la crittografia quantum-safe e il modeling di "avversari quantistici", ma un focus particolare è dato allo studio di protocolli crittografici per la sicurezza di dati quantistici.
In questo tipo di ricerca studio, ad esempio, come un algoritmo quantistico possa cifrare un dato in maniera tale che senza avere la giusta chiave di sblocco nessuno, neanche un altro computer quantistico, potrebbe mai recuperarlo.
In uno dei nostri lavori più recenti, pubblicato alla conferenza EUROCRYPT, io e i miei collaboratori abbiamo risolto un problema fondamentale: come garantire l'integrità di un dato quantistico in transito su una rete, anche nel caso che il modello di minaccia includa avversari tecnologicamente molto potenti. Stiamo al momento studiando la sicurezza di altri protocolli (sia per computer classici che quantistici) che siano sicuri contro gli "hacker quantistici" del futuro.
Questo campo di ricerca è giovane e terribilmente stimolante. Il conto alla rovescia è partito, ma assistiamo a continui progressi e sono più che sicuro che arriveremo preparati con strumenti adeguati a rendere l'Internet del futuro più sicura che mai.
Vale infine la pena ricordare che non è necessario attendere sviluppi futuri per poter "toccare con mano" un computer quantistico: con il programma Q Experience di IBM si può imparare a scrivere codice per programmare quantum computer, accedere gratuitamente (via cloud) ai prototipi di quantum computer sviluppati da IBM (attualmente fino a 16 qubit), e far girare algoritmi quantistici su tali macchine.
Questo network è già utilizzato da una miriade di studenti, ricercatori e università in tutto il mondo, e rappresenta uno strumento di importanza fondamentale per acquisire il know-how necessario ad arrivare preparati all'imminente rivoluzione informatica.
(Dec 10th, 2019) Relocation to Zurich + Quantum Supremacy Blog Post
Just wanted to let you know that I succesfully completed my relocation to Zurich! I am continuing to lead the efforts in innovation and research in quantum activities at Kudelski Security, but from here it will be more convenient for me to meet interested stakeholders in the Crypto Valley area. Plus, I love Zurich!
Let me also point you out to a blog post I recently wrote for the KS Research blog on the topic of quantum supremacy (in particular explaining what happened between Google and IBM).
(Aug 12th, 2019) Quantum Vocabulary
Too often I read articles where there is confusion (both in concepts and terminology) between quantum cryptography, quantum key distribution (QKD) and post-quantum cryptography. I wish this confusion vanished in the popular literature, it is not so difficult to grasp after all, and makes the work of us scientists much more difficult in explaining our results.
Let me recap it for you:
Quantum Computing (QC) is the computing technology being researched right now. A few misconceptions: a QC cannot just "factorize 15" (that was long ago), it is not only interesting for breaking cryptography (actually most of the useful applications are civilian), a famous Canadian company does not have a "quantum computer" (they call it like that but it's something different), and building a QC would not "violate the laws of quantum mechanics", nor there is any scientific evidence that it should be impossible (just the engineering effort is hard, as in any new technology). If you are amongst those who think they can show that building a QC is impossible, then congratulations for your 100k USD bet win!
Quantum Cryptography is cryptography that runs on a quantum device. This can be a quantum computer proper, or something more rudimentary but which uses quantum effects. Just like classical cryptography, there are many possible different kind of quantum cryptography applications (symmetric-key encryption, public-key encryption, fully homomorphic encryption, etc), the general rule is that quantum cryptography encrypts quantum information (qubits) rather than classical.
Quantum Key Distribution (QKD) is a particular subfield of quantum cryptography. This is what is usually mistakenly called "quantum cryptography", but it is very different in concept. QKD uses quantum states to establish a classical secret key over a quantum channel. It does not encrypt quantum data. Whereas quantum cryptography "proper" requires a working quantum computer (and it is therefore impossible nowadays), QKD only requires modest quantum hardware, and can be realized today (you can buy it actually). However: QKD only solves a very, very limited cryptographic task, at the cost of expensive infrastructure, it is vulnerable to man-in-the-middle attacks (so it has to be composed with other, less secure protocols), and the actual hardware implementations are usually not as secure as in theory.
Post-Quantum Cryptography is a badly, badly, badly chosen term and it should be avoided because it really creates confusion. Somehow the name stuck because it was cool. A better name would be "quantum-resistant", or "quantum-safe" cryptography. This is cryptography in the classical sense (that is, you can run it on your PC), but that it's based on very hard math problems supposedly resistant against future quantum computers. It has drawbacks in terms of performance in respect to traditional schemes such as RSA, but it is important to adopt it ASAP, even if quantum computers won't be around for other 100 years, otherwise it's gonna be too late.
Hope that helps.
(July 26th, 2019) Debian Sid Initramfs Boot Dependency failed for boot with LUKS after update
If you also had boot problems after performing an update on Debian Sid a few days ago (boot stuck at initramfs shell) here is what worked for me.
Disclaimer 1: this is not guaranteed to work for you as well
Disclaimer 2: this is also not guaranteed to not give you terminal illness or cause widespread thermonuclear war
Disclaimer 3: I am a n00b of Debian and I don't really know what I am doing, so it's basically trial and error
Disclaimer 4: Debian being Debian, *nobody* really knows what they are doing anyway, and if they claim otherwise then they are liars or Reptilians.
Anyway, here you go:
boot a Debian live distro (e.g. from USB drive)
make sure you have networking and DNS running on the live system, and install any tool you might need (vim etc)
sudo su
lsblk -o name,uuid,mountpoint
Sometimes these problems are caused by wrong UUIDs on /etc/fstab or /etc/crypttab. I assume you are a pr0 and this is not your case. Then, identify boot and encrypted partitions on your hard drive, and unmount them if not already dismounted. For the following we assume:
/dev/sda1 EFI partition
/dev/sda2 boot partition
/dev/sda3 encrypted LUKS partition containing the root partition
cryptsetup open /dev/sda3 sda3_crypt
Insert passphrase to unlock the partition (or provide a keyfile). If the underlying partition is an LVM one, you also need to activate the logical volume group and mount the correct logical volume (but I will ignore this here). Then mount everything in a chrooted environment:
mount /dev/mapper/sda3_crypt /mnt
mount /dev/sda2 /mnt/boot
mount /dev/sda1 /mnt/boot/efi
mount --bind /dev /mnt/dev
mount --bind /proc /mnt/proc
mount --bind /sys /mnt/sys
mount --bind /run /mnt/run
chroot /mnt
Now it is a good idea to update the system and firmware modules if needed, especially if you were getting warnings when booting the system before the boot failure. In my case installing firmware-linux removed the warnings. So, check that you have network connection in the chrooted system (if necessary edit resolv.conf to add DNS). Edit /etc/apt/sources.list and make sure that there are the following two lines:
deb http://debian.org/debian/ sid main contrib non-free
deb-src http://debian.org/debian sid main contrib non-free
Now do a system update (as mentioned, install related modules if getting warnings during initramfs generation)
apt update
apt upgrade
depmod `uname -r`
You might get an error at this point. Maybe the kernel version of the live system is different from the one installed on your system. To avoid issues, if this happens to you, build the initramfs against the installed kernel. To check what version you have, do cd /boot and ls -Al. You will see a bunch of files, for example:
total 107976
drwxr-xr-x 5 root root 4096 Jul 26 08:15 ./
drwxr-xr-x 24 root root 4096 Jul 21 21:39 ../
-rw-r--r-- 1 root root 206118 Mar 15 03:16 config-4.19.0-4-amd64
-rw-r--r-- 1 root root 206213 Jul 19 00:23 config-4.19.0-5-amd64
drwx------ 3 root root 4096 Jan 1 1970 efi/
drwxr-xr-x 5 root root 4096 Jul 23 20:54 grub/
-rw-r--r-- 1 root root 40260505 May 1 13:57 initrd.img-4.19.0-4-amd64
-rw-r--r-- 1 root root 52681191 Jul 26 08:15 initrd.img-4.19.0-5-amd64
drwx------ 2 root root 16384 Jan 10 2019 lost+found/
-rw-r--r-- 1 root root 3365519 Mar 15 03:16 System.map-4.19.0-4-amd64
-rw-r--r-- 1 root root 3371003 Jul 19 00:23 System.map-4.19.0-5-amd64
-rw-r--r-- 1 root root 5213424 Mar 15 03:16 vmlinuz-4.19.0-4-amd64
-rw-r--r-- 1 root root 5217520 Jul 19 00:23 vmlinuz-4.19.0-5-amd64
In this case the most recent version is 4.19.0-5-amd64, so in this case do:
depmod 4.19.0-5-amd64
Rebuild the initramfs:
update-initramfs -u
It might complain with warnings about missing locales, in that case do: dpkg-reconfigure locales (and then select `update all`, will take some minutes, then redo update-initramfs -u )
Finish by updating and reinstalling the bootloader:
update-grub
grub-install /dev/sda
exit
Now it is important to unmount everything in a clean way and in the right order before rebooting the system. Also a filesystem check helped in my case:
unmount /mnt/boot/efi
unmount /mnt/boot
unmount /mnt
fsck -f /dev/sda3_crypt
cryptsetup close sda3_crypt
exit
Unplug the live distro media, reboot your machine, and pray your favorite digital gods.
(May 30th, 2019) My Article on Quantum Signatures and Signcryption on the Kudelski Security Research Blog
I wrote an article on the KS Research Blog about some of the recent results I submitted to ASIACRYPT together with Gorjan Alagic and Christian Majenz. The take-home message is twofold. On one hand, cryptographically signing a quantum state (as in public-key digital signatures) turns out to be impossible. This result was considered folklore as a consequence of a result by Barnum et al. in 2002, but it turned out that formally proving it was quite tricky and not a simple extension of the symmetric-key case they consider. On the other hand, we show how to circumvent such impossibility by using signcryption, that is, signing and encrypting at the same time. We give novel security notions and constructions for quantum signcryption, with the caveat that (because of the impossibility result above) non-repudiation is anyway impossible.
(Apr 7th, 2019) My Article on Quantum Cryptography on the Kudelski Security Research Blog
I wrote an article on the KS Research Blog about quantum cryptography. Not to be confused with quantum key distribution (QKD), which is a specific subfield of it, quantum cryptography is the manipulation of data at a quantum level in order to achieve tasks such as encryption, digital signatures, and fully homomorphic encryption. Some of these classical tasks have a natural analog in the quantum realm; some others are impossible classically but possible quantumly, or vice versa. In that blog post I give an introduction to quantum cryptography, as well as presenting in a non-technical way some of the latest scientific breakthroughs in the area.
(Mar 21st, 2019) Email Spam Filter Tightened
I'm really pissed of the amount of academic spam emails I'm receiving recently. Apparently my provider, Gandi.net, is not doing a great job at blacklisting these idiots, so I decided to manually add some keyword-based filtering. If you receive a reject message with an angry text (and you're not a spammer) please try to send it again using a different topic or email address (oh, and sorry for the angry words, I do not really think that your mom will die in her sleep tonight).
(Feb 28th, 2019) My Article on Quantum Computing and the New IT Revolution on the Modern CISO Blog
I wrote an article on the Modern CISO Blog about Quantum Computing that pretty much summarizes my view on the issue. I did my best to concile scientific accuracy with the need of a simple, eye-catching vocabulary. I hope Scott Aaronson won't be mad at me :)
(Jan 20th, 2019) My New Position at Kudelski Security + Quantum Signcryption Paper
I am super excited to announce that I have recently started a new job as Cryptography Expert at Kudelski Security! Looking forward to doing a lot of cool and crazy stuff with my new colleagues! The relocation to Lausanne went smoothly and I'm now pretty settled. I loved my stay at IBM Research and I'm thankful to my former colleagues for the great time spent together!
On an unrelated note, check out this cool paper (collaboration with Gorjan Alagic and Christian Majenz) where we show that: 1) signing a quantum state with a private-public key system is impossible, unless 2) the state is also encrypted, leading to a notion of quantum signcryption, but 3) in any case non-repudiation is impossible to achieve quantumly. I think that's a pretty cool result, and I'm really thankful to my coauthors, this would have not been possible without a lot of teamwork!
(Oct 18th, 2017) Travel to Uzbekistan: Some Updated Info
I've traveled recently to Uzbekistan for holiday, which was quite amazing. But since it is a kinda off-the-beaten-path destination, I figured out first-hand that some of the info on the internet for Western travelers are quite outdated. So, although off-topic, here is some more recent "practical" information.
First of all, it is true that Uzbekistan is a cash society, but it is not true anymore that you need to carry around bags full of banknotes: 20000 and 50000 Som (UZS) bills have been introduced (very) recently.
Moreover, there is no more a difference between "official" and "black market" exchange rate with the dollar. This is because, also very recently, the government de-regulated the rate, and now banks and money exchanges adapted to the market price. This has three immediate consequences: 1) black-market money exchanges stopped operating: now you can safely go to a bank without being ripped off. 2) looking at the chart of the UZS/USD exchange rate looks scary. That peak (from about 4000 to 8000 Som/USD) is not because of a war or a golpe: it's just the de-regulation in effect - I say it because at first it looked surely scary to ME. 3) there is currently a somewhat widespread scarcity of cash. As far as I understand you can only withdraw a limited amount of money at the bank, and only upon showing a valid ID. So, if you visit the country, the old recommendation of carrying some USD in cash still holds.
Also, withdrawing cash is tricky. In Bukhara, for example, there is only one ATM in the city center, and it only accepts VISA credit cards. In general, according to my personal experience, Maestro, MasterCard and any debit/prepaid cards do not work at all, only VISA. But maybe in Tashkent's "western" hotels the situation is better.
Life there, as far as I could see, is cheap, but not crazy cheap. The country feels very safe from a tourist's perspective. It's full of police everywhere, but they did not bother me. Islam is very, very moderate. Infrastructure is meh, but liveable. Driving is crazy if you're never been in Rome. I can say there is a reason why fruit and vegetables from Uzbekistan (especially the fabled melons) are famous in the whole ex-URSS. Climate in September was gorgeously Mediterranean. Overall, to me the whole country looked disturbingly familiar: it's basically like southern Italy, but without pork and with more muslim architecture.
Kidding apart, I really liked the place and the people, so friendly and genuine. The hospitality is simply unbeatable: western tourists are not so common, so everybody wants to talk to you, practice their English, invite you for tea, showing you around to family and friends, etc.
A last piece of advice: your life will always be empty until you try the local plov (osh). According to the locals, the browner the carrots, the better.
(Jul 2nd, 2017) My New Position at IBM Research Zurich
Long time since I've updated this page. Just a couple of words to say how excited I am to having started my new position as a post-doc at IBM Research Zurich. The relocation was pretty intensive business, but now I am finally settled and looking forward to enjoy my new life here in Switzerland.
(Nov 5th, 2016) Norcia and Central Italy Earthquake
I would just like to reassure you that my family, friends, and relatives are all fine after the recent earthquake which struck Central Italy. I want to thank wholeheartedly all the people and friends who asked me if everything was fine. My thought goes to all the families who have not been as lucky as we were. Those places were incredibly beautiful, and I am sure that they will be again very soon.
(Oct 2nd, 2016) Back in Darmstadt
After an intensive period of travelling, I am finally settled back in Darmstadt again - for a while. I am working on my PhD thesis, the time for my graduation has finally arrived, and I would like to finish it ASAP. Therefore, hereby I solemnly commit to: 1) not start other new research projects for a few months (the open ones I have are more than enough) 2) not travel again until Christmas at least - that's gonna be hard! On a side note, our ICITS paper has been presented at QCRYPT - pity I missed the conference, but I'm happy nonetheless!
(Jul 31th, 2016) Trip to the US!
Hey, I'm heading off to the States! I will first go to Tacoma, WA, for attending ICITS, where I'll give a talk about our recent results on the Computational Security of Quantum Encryption (joint work with Gorjan Alagic, Anne Broadbent, Bill Fefferman, Christian Schaffner, and Michael St Jules). Then I'll move to Santa Barbara, CA, where I'm giving a talk at CRYPTO about our work on Semantic Security and Indistinguishability in the Quantum World (joint work with Andreas Huelsing and Christian Schaffner). And then a few days of vacation for some Californian desert adventure time!
(Mar 6th, 2016) Copenhagen
I'm in Copenhagen, visiting my colleague and friend Gorjan Alagic at Matthias Christandl's group of Quantum Information Theory QMATH at the University of Copenhagen. I should also visit Lars Knudsen's group at the Technical University of Denmark one of these days. Looking forward to some productive time!
(Dec 19th, 2015) Incoming Event: First CROSSING Winter School on Quantum Security
I want to point you out to this winter school which is going to be held in Darmstadt, Germany, from January 25th to 29th, 2016.
Marc Fischlin (my advisor) and I initially devised this school as a nice academic event to be hosted by CROSSING here at the Technical University. We made sure that the school would be free of charge to attend, but at the same time we managed to keep at a very high level the quality of applications.
Apparently, people liked the idea. Very renown speakers accepted our invitation, and we have been overwhelmed with requests of participation from all around the world. We planned around 30-35 participants, we received almost three times that amount of applications. We worked very hard to find a suitable venue and now we managed to extend the list of participants to more than 70. This includes now not only students, but professors, professionals from private companies, military organizations and so on. So, long story short: the whole thing turned out much bigger than we expected!
I am very excited, it's also a completely new experience for me to be part of the organization of such a big event, there are a lot of things to do and to take care of. It's really hard work too, especially considering that we are trying to do in 6 months what usually takes 12. But I'm sure it's going to be a great success, thanks to the amazing speakers we will have. Looking forward to the end of January, but for now I wish you all happy winter holidays (I am myself enjoying some rest at my hometown in Italy finally!)
All the best!
(May 6th, 2015) Lugano, Switzerland: ICITS 2015 and visiting USI
I am in Lugano for ICITS 2015 and visiting the USI. I also gave a talk at Stefan Wolf's group about our work `Semantic Security and Indistinguishability in the Quantum World` (joint work with Andreas Hülsing and Christian Schaffner, full version available on the Eprint).
(Apr 7th, 2014) Buenos Aires, Argentina: PKC'14
I was in Buenos Aires for the PKC'14 conference. Feel free to check out the slides of my talk `General of Group Homomorphic Encryption in the Quantum World` (joint work with Frederik Armknecht, Stefen Katzenbeisser and Andreas Peter, full version available on the Eprint).
(Dec 5th, 2013) Bangalore, India: Asiacrypt'13
I am currently in Bangalore for the Asiacrypt'13 conference. Feel free to check out the slides of my talk `The Fiat-Shamir Transformation in a Quantum World` (joint work with Özgür Dagdelen and Marc Fischlin, full version available on the Eprint).
(Apr 29th, 2013) Eric Schmidt about Google Glass privacy: society will adapt
You may have heard about this Erik-guy: he's the big boss of some non-evil tech company everybody likes. The same guy who says its company is basically reading your mind, but it's OK because they do it with your permission, and in any case you could always change your name in the future to avoid association with your digital past. The same guy who gave us this pearl of wisdom:
"If you have something that you don't want anyone to know, maybe you shouldn't be doing it in the first place"
except, maybe it's better if you don't try to out-creep him by publishing some of his (publicly available) personal data, or he may get pissed.
On a sidenote, you may have heard about Google Glasses: the new, revolutionary, ultrasmart, uberhipster thing for sexy geek people who love tech, freedom, democracy, and most importantly, sharing. The new, cool people everybody wants obviously to be like.
You may also have heard about some nonsense luddist criticism about the feature of these cool glasses of having a small camera potentially turned on all the time, recording your life and the life of people around you 24/24H. Criticism obviously devoid of any argument, made by old, uncool, paranoid haters never leaving their damp basement full of polluting Debian machines. Oh, and never getting laid. But worry not, the Heric-guy has a proper response to such nonsense:
"criticisms are inevitably [sic] from people who are afraid of change or who have not figured out that there will be an adaptation of society"
Good. Now, the point is: you may also have heard about the Enric-guy's opinion about the use of commercial flying drones by civilians:
"It's got to be regulated. [...] It's one thing for governments, who have some legitimacy in what they're doing, but have other people doing it... It's not going to happen."
and then you may have naively wondered: "how comes that being against the idea of normal people flying their own, cheap drones thanks to the advancement of technology is not just fear of change and failure to adapt to the society?".
A lot of readers noticed the above fallacy and raged against it (see for example the comments in the Slashdot article). But I have the feeling that stopping at this observation is dangerously short-sighted. I'm not going to discuss here the use of drones by civilians, I admit I don't have yet strong opinions about it - while I definitely do about people wearing surveillance equipment 24/24H: not in my house anyway. My point is another:
suppose more and more people react against Schmitt's words, pointing at his opinion about private drones as a proof of his hypocrisy. Then one day he pops up with apologizes: "Yeah, sorry, you're right: maybe private drones are not so bad after all". Satisfied? Not a big damage for him, main argument of his detractors dismissed. Uh... what was so bad about those glasses apart from that thing, anyway? Now you have to explain it over again to me and all my lazy-minded friends on Facebook...
My suggestion: never lose sight of the big picture of things. Eerie Smith's argument is so laughable that I can understand people enjoy bashing him on that point. But to focus on this strategy is to accept candies from the enemy: there may be poison. Whatever you may think about private drones, the implications of a society full of dorks wearing those glasses are FAR more important. Call me paranoid, but I wouldn't be surprised if this were just a smart marketing move to defuse the much more serious criticisms about this dystopian view of (still more) ubiquitous surveillance.
(Mar 17th, 2013) HowTo: OpenVPN with Elliptic Curve Cryptography (ECC) and SHA2 on Linux Debian
UPDATED VERSION: fixed OpenSSL vulnerability from Nadhem Alfardan and Kenny Paterson. Notice that the old version 1.0.1c and previous are vulnerable . Thanks to the anonymous reader who pointed that out (I had already attended a talk by Kenny in Darmstadt about the issue last year but I was still waiting for a fix). If you are affected you should recompile OpenSSL (the new version) and then OpenVPN, all should work as before. Please upgrade!
In this howto I will explain how to setup a typical OpenVPN infrastructure with an atypical cryptographic protocol involving Elliptic Curve Cryptography (ECC) and the more recent SHA2 cryptographic hash family on Linux Debian. The problem lies in the fact that this setup is not (still) natively supported by OpenVPN, and some workarounds are necessary. Proof of this is the fact that you won't find a lot of informations on the internet about a similar setup, and those few are either incomplete or not working. It took me a lot of effort to make this tutorial, I really hope it can help some of you having a similar situation.
Summary
We will first install the latest version of OpenSSL on a Debian system (everything also works fine for Ubuntu and similar derivates). Then we will compile OpenVPN against the newly installed OpenSSL and add a manual patch, which makes possible the use of ECC authentication schemes with SHA2. We will then create a Certification Authority (CA), server and client certificates, and then setup a VPN by enabling routing and NATting over a virtual interface on the server side.
Open problems
The encryption protocol for secure key-exchange is still the traditional Diffie-Hellmann (DH) and not the more secure ECDH (Elliptic Curve Diffie-Hellmann). This cannot be fixed until OpenVPN won't natively support ECDH (e.g., with an "ecdh" directive in the server.conf instead of the "dh" directive).
Moreover, it is not still 100% clear if SHA2 is used over both OpenVPN's channels (control and data) or just over the control channel (see thread at https://forums.openvpn.net/topic8404.html).
Premise
I will have to assume that the reader is familiar with the basic concepts of public-key cryptography, authentication and hash functions. The typical public-key encryption and signature schemes, such as RSA, Diffie-Hellmann (DH) and DSA, do not offer the same advantages (both in terms of security as well as performances) as ECC does: ECC is faster (on the average hardware) and needs smaller key sizes to obtain comparable security, hence saving bandwidth etc.
Many ECC applications are unfortunately plagued by the draconian North American patent system (there is a lot of mess on some of these aspects here, which I will not address). I am based in Europe, so am not going to take into account such considerations in this tutorial, but if you are a US/Canadian citizen maybe you should care, I'm not exactly sure which of the following steps and to what extent may be deemed unappropriate. Please check if in doubt.
SHA2 cryptographic hash functions family comes basically in three variants: SHA-256, SHA-384 and SHA-512, depending on the message digest size. They are all much more secure of the more well-known MD5 and SHA1 (SHA-160), which are both to be considered insecure for today's standards. It is worthwhile repeating: do not use SHA1 or MD5 for secure applications, ever.
The main problem about OpenVPN's most common setups is that they usually employ SHA1 as a digest. There is an undergoing public competition by NIST for a new standard called SHA3 (in a similar way to the competition for AES), but it won't be due until mid 2012.
I will give this tutorial for a Debian stable system, but it shouldn't be difficult to adapt it to other distributions. I assume that all the job is done via the root account for simplicity.
I will assume that there are three machines:
- the secure working machine where the CA certificates are stored, which should ideally be disconnected from the network
- a reasonably secure server machine, where the OpenVPN server daemon will run
- a client machine, which wants to connect to the internet by routing all its traffic through the server machine
Also for simplicity, in this tutorial all the keys and certificates will be generated on the secure machine, and then moved to client and server. Of course the standard way would be instead to generate, e.g., the client key on the client an then submit it to the CA for the certificate generation. I will just simulate this process by using directories on the secure machine, and then copying or moving the certificates and keys as needed.
The issue
OpenVPN uses the encryption routines provided by OpenSSL. ECC and SHA2 crypto primitives are relatively new and have been only recently added to the set of OpenSSL's primitives. The problem is that a composite scheme using both has not yet been added in OpenVPN: with the latest stable release you can either choose an RSA setup with SHA2 as a message digest, or opt for an ECC setup with the standard SHA1, but there is no way to mix both. After having asked around in both OpenVPN forum and OpenSSL mailing list, user janjust has kindly provided a rough patch (see here ) which solves the issue. The patch has been submitted, but AFAIK not yet included in the official version, so we'll have to do the fix manually, but it is likely that it will be included starting from the next stable release.
Preliminaries
First of all open terminal and open a root session with su . On Ubuntu and similar you don't have a root account by default, so either you always use sudo before administrative commands, or:
sudo su -
Another option would be to create a root account with:
sudo passwd root
now you can use su. Remember to close all the root session you open with exit when you have finished.
Install the following packages on all of the machines involved:
apt-get install wipe build-essential
Keep in mind that we are going to build some big stuff, so it might take a lot of time on a slow machine.
Installing updated OpenSSL
The following must also be done on all the machines. First of all install and compile the latest version of the LZO library, we will need it later:
cd /root
mkdir .ssl
cd .ssl
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz
tar -zxf lzo-2.06.tar.gz
rm lzo-2.06.tar.gz
cd lzo-2.06
./configure
make
make test
make install
cd ..
rm -R lzo-2.06
Then we are going to install OpenSSL. Be aware that OpenSSL is a vital part of any Linux distribution, so it is not possible to simply uninstall the default version and compile the new one without having a lot of problems. For this reason we are just going to install the latest version in a non-system directory, which in this case is /usr/local but you have to change it if for any reason it is not suitable to your situation. It would be much simpler if the latest release was found in the Debian repositories but I'm not aware of any Debian repository for updated versions of OpenSSL.
The latest OpenSSL stable release at the moment is the 1.0.1e.
wget http://www.openssl.org/source/openssl-1.0.1e.tar.gz
tar -zxf openssl-1.0.1e.tar.gz
rm openssl-1.0.1e.tar.gz
cd openssl-1.0.1e
./config --prefix=/usr/local/openssl --openssldir=/usr/local/openssl
make
make test
make install
cd ..
rm -R openssl-1.0.1e
Now we are going to add an alias, so that every time we run the openssl command, the freshly installed version will be called, and not the default system one. I will use the nano editor for this tutorial.
nano ../.bashrc
Add the following line at the bottom:
alias openssl='/usr/local/openssl/bin/openssl'
then activate the alias:
source ../.bashrc
Check that everything is OK:
openssl version
Should be something like:
OpenSSL 1.0.1e x Yyy zzz
Now we have to use a slightly modified version of the openssl.cnf configuration file. Put this file in the current directory ( /root/.ssl ), so we don't have to overwrite the default conf file (though it would probably be a good idea anyway, since the one we will use is a more appropriate version tuned up for better security). In case you wonder, the main modification is the addition of a [server] section to give the right permissions to the certificates generated for the server.
Installing and patching OpenVPN
This is also going to be done on all the machines.
The latest OpenVPN stable release at the moment is the 2.2.1
NOTICE: I'm still using an old version, but maybe the patch has already been included in one of the latest versions, it would be nice to check.
wget http://swupdate.openvpn.net/community/releases/openvpn-2.2.1.tar.gz
tar -zxf openvpn-2.2.1.tar.gz
rm openvpn-2.2.1.tar.gz
cd openvpn-2.2.1
Now add the following patch to the file ssl.c (you can do it manually: plus signs at the beginning of a line means that the line must be added, minus signs means that the line must be removed, while @@ is a marker for the line position in the file).
We finally build OpenVPN by linking it to the newly installed OpenSSL version:
./configure --with-ssl-headers=/usr/local/openssl/include --with-ssl-lib=/usr/local/openssl/lib --enable-iproute2
make
make install
cd ..
rm -R openvpn-2.2.1
Check that everything is OK:
openvpn --version
must be something like:
OpenVPN 2.2.1 x86_64-unknown-linux-gnu [SSL] [LZO2] [EPOLL] [eurephia] built on ...
Create the configuration directory for OpenVPN in case it has not been created automatically:
mkdir /etc/openvpn
Optionally, reboot.
Creating a Certification Authority
Recall that in this tutorial we are going to create the keys and certificates in three separate directories, each one for CA, server and client, and just move the certificates around for simplicity, but the "safe" way to do this is to have three separate machines and to keep the CA machine unplugged from the network.
cd /root/.ssl
mkdir CA
cd CA
mkdir newcerts
echo "01" > serial
touch index.txt
mkdir private
chmod 700 private
cd private
Now we are going to generate a public/private EC key. Beware especially to the -conv_form compressed option: it will produce smaller curve representation which are also faster for point multiplication, but this representation is covered by a Canadian patent. I am using the Koblitz curve sect571k (571 bit binary field), but you can choose other curves, just run:
openssl ecparam -list_curves
to see a list of available curves.
openssl ecparam -genkey -name sect571k1 -text -conv_form compressed -out cakey_tmp.pem
openssl ec -in cakey_tmp.pem -out cakey.pem -aes256
Choose a passphrase for unlocking the CA key. You will need this key every time you want to generate a server or client certificate.
wipe -f cakey_tmp.pem
chmod 600 cakey.pem
cd ..
Now we are going to create the main CA certificate. This will be needed by every client and server to authenticate the CA. Edit the fields in the command below according to your needs.
openssl req -new -x509 -key private/cakey.pem -config ../openssl.cnf -extensions v3_ca -subj '/C=CaState(TwoLetters)/ST=CaState/L=CaCity/CN=www.yourauthorithy.com/O=YourName/emailAddress=your@email.address' -days 36500 -sha512 -out cacert.pem
Insert the CA passphrase to generate the certificate. You can see the certificate's attributes with:
openssl x509 -text -in cacert.pem
openssl x509 -fingerprint -noout -in cacert.pem -sha256
cd ..
Take note of the hash value and make sure it is publicly accessible by anybody who wants to check the authenticity of the cacert.pem in their possession.
Creating a server certificate
First of all we are going to create a Diffie-Hellmann key exchange parameter file. This might change in the future, when OpenVPN will support the ECDH key exchange protocol. We are going to generate a quite large DH modulus, since this tutorial is aimed at obtaining the best possible security, but keep in mind that this will take a long time (several minutes or possibly hours on a 2.3 GHz quadcore machine). Also keep in mind that this parameter needs not to be secret, so you can share and reuse it for as many other server installations as you want, as long as you don't care that the servers could be linked to the same generating entity.
mkdir server
cd server
openssl dhparam -out dh.pem 4096
Now import the CA certificate and generate a secret TA key which we'll need later to authenticate the control channel for further security.
cp ../CA/cacert.pem ./
mkdir private
chmod 700 private
cd private
openvpn --genkey --secret ta.key
Now we are going to generate the server's private key for authentication. Unlike in the CA step, we are not going to encrypt it, because otherwise we would be prompted for a password every time a service on the server side needs to access the key to be started. E.g., it would be impossible to automatically restart our OpenVPN server without manually inserting a passphrase or delegating this step to a script that would contain the passphrase in cleartext (which is almost equivalent to have an unencrypted key for the most of practical applications). Considered that the services accessing this key in plaintext will be running almost all the time, I think it's not worthwhile to encrypt the server key, unless you REALLY trust the security of all those services OR you think that they won't need frequent restarts OR you employ very secure process isolation policies via virtual machines (e.g., on a Qubes environment or similar).
openssl ecparam -genkey -name sect571k1 -text -conv_form compressed -out serverkey.pem
chmod 600 serverkey.pem
cd ..
Now we need to generate a certificate request, send it to the CA, have it signed by the CA and then sent again back to our server. As usual, in this tutorial these steps will be simulated.
openssl req -new -key private/serverkey.pem -config ../openssl.cnf -extensions server -subj '/C=ServerCountry(TwoLetters)/ST=ServerCountry/L=ServerCity/CN=www.myserver.com/O=ServerName' -days 36500 -sha512 -out req.pem
openssl req -in req.pem -noout -text
cd ../CA
mv ../server/req.pem ./
openssl ca -config ../openssl.cnf -extensions server -policy policy_anything -out ../server/servercert.pem -md sha512 -cert cacert.pem -keyfile private/cakey.pem -infiles req.pem
Insert the CA passphrase to sign the server certificate.
rm req.pem
cd ../server
openssl x509 -in servercert.pem -noout -text -purpose
cd ..
Creating one or more client certificates
The following must be repeated for every client who wants to connect to the VPN and at this point should be self-explainatory:
mkdir client
cd client
cp ../CA/cacert.pem ./
mkdir private
chmod 700 private
cd private
cp ../../server/private/ta.key ./
openssl ecparam -genkey -name sect571k1 -text -conv_form compressed -out clientkey_temp.pem
openssl ec -in clientkey_temp.pem -out clientkey.pem -aes256
Insert a passphrase to protect the client key.
wipe -f clientkey_temp.pem
chmod 600 clientkey.pem
cd ..
openssl req -new -key private/clientkey.pem -config ../openssl.cnf -extensions client -subj '/C=ClientCountry(TwoLetters)/ST=ClientCountry/L=ClientCity/CN=ClientName/O=ClientOwnerName/emailAddress=client@e.mail' -days 36500 -sha512 -out req.pem
Reinsert the client passphrase.
openssl req -in req.pem -noout -text
cd ../CA
mv ../client/req.pem ./
openssl ca -config ../openssl.cnf -policy policy_anything -extensions client -out ../client/clientcert.pem -md sha512 -cert cacert.pem -keyfile private/cakey.pem -infiles req.pem
Insert the CA passphrase.
rm req.pem
cd ../client
openssl x509 -in clientcert.pem -noout -text -purpose
cd ..
Server configuration
This must be done on the server machine. Create the following two folders if they have not been already created:
mkdir /etc/openvpn
mkdir /etc/default
Copy all the content of the directory /root/.ssl/server on the trusted machine we used in the previous step in the server's /etc/openvpn directory. Also, add this file, but substitute xx.xx.xx.xx with your server's IP, and yy.yy.yy.0 will be the VPN address pool (the server will create a virtual interface on yy.yy.yy.1). Also note that with this configuration you can override the DHCP discoveries of your clients being sent through the VPN (i.e.: the DHCP queries of your clients will remain inside their respective networks and will not travel through the VPN). The DNS option allows you to specify your own DNS servers for the VPN, in this case I have put the OpenDNS servers, but you can also choose others or comment out that option (then DNS queries through the VPN will use the same OpenVPN server's DNS).
Now we must make sure that the OpenVPN server's interface is started whenever the server reboots. First of all create a file called openvpn in /etc/default (if it is not present already) and make sure it contains the following line:
AUTOSTART="all"
Then put this script file in /etc/init.d . Notice the line DAEMON=/usr/local/sbin/openvpn instead of DAEMON=/usr/sbin/openvpn : this is because we installed OpenVPN manually at that position. Now run the following:
service openvpn add
Then open the /etc/sysctl.conf file and look for the following line (add it if it doesn't exist):
net.ipv4.ip_forward = x
Where x can be 0 or 1. Change x to 1 if it is set to 0. This will basically turn your server into a router, meaning that it will be able to route packets through different network interfaces. This behaviour will be reset at every reboot though, so we need to make the modification permanent with:
sysctl -p /etc/sysctl.conf
Check that everything is OK:
cat /proc/sys/net/ipv4/ip_forward
must be 1.
Now we need to abilitate a NAT translation from the OpenVPN virtual interface to the server's network interface. To do this, edit the script at /etc/network/if-up.d/iptables (or create it if it doesn't exist, making it executable with chmod +x /etc/network/if-up.d/iptables ). Make sure that it begins with:
#!/bin/sh
and then add the following lines:
iptables -t nat -A POSTROUTING -s yy.yy.yy.0/24 -o eth0 -j MASQUERADE
iptables -A INPUT -i tun+ -j ACCEPT
iptables -A OUTPUT -o tun+ -j ACCEPT
iptables -A FORWARD -i tun+ -j ACCEPT
where eth0 should be your primary network interface, the one which is bound to the xx.xx.xx.xx address (check it with ifconfig if unsure).
Finally, restart networking and OpenVPN:
service networking restart
service openvpn restart
Now the OpenVPN service should automatically run at every reboot, and with ifconfig you should also see the new yy.yy.yy.yy interface.
Client configuration
This must be done on the client machine. Login as a normal user and create the following folder if it has not been already created:
mkdir ~/.openvpn
Copy all the content of the directory /root/.ssl/client on the trusted machine we used in the previous step in the client's ~/.openvpn directory. Also, add this file, but replace xx.xx.xx.xx with your server's IP.
Update: a useful feature for ease of configuration is to bundle all of the configuration files, keys, and certs in a single .ovpn file. Just creat a file client.ovpn which is basically a copy of client.conf, with the following modifications:
1) instead of using ca, cert, key, tls-auth parameters, paste inline directly the content of the related files as in the following example:
<ca>
-----BEGIN CERTIFICATE-----
# insert base64 blob from cacert.pem
-----END CERTIFICATE-----
</ca>
<cert>
-----BEGIN CERTIFICATE-----
# insert base64 blob from clientcert.pem
-----END CERTIFICATE-----
</cert>
<key>
-----BEGIN PRIVATE KEY-----
# insert base64 blob from client.key
-----END PRIVATE KEY-----
</key>
<tls-auth>
-----BEGIN OpenVPN Static key V1-----
# insert ta.key
-----END OpenVPN Static key V1-----
</tls-auth>
2) add the key-direction 1 directive; and
3) use remote-cert-tls server instead of ns-cert-type server.
Connect
From the client, you can connect to the new VPN with the command:
openvpn ~/.openvpn/client.conf
(you need to provide the password to unlock the client's secret key).
If you bundled the files using the .ovpn method above, you can use openvpn ~/.openvpn/client.ovpn instead.
Revoking a client certificate
In order to revoke a certificate, first we have to update the CA's index and generate an updated Certificate Revocation List (CRL), then instruct all the servers who use that CA to use the crl-verify options, and finally upload the new updated CRL to those servers.
cd /root/.ssl/CA
cat index.txt
This will give us a list of the recorded certificate, plus a serial number in front of it. Let's assume we want to revoke client certificate number 03. Then check to be sure:
openssl x509 -text -noout -in newcerts/03.pem
If it is correct we can revoke it:
openssl ca -config ../openssl.cnf -revoke newcerts/03.pem
(insert the CA's passphrase). We can confirm the revocation with:
cat index.txt
(the R stands for "Revocated"). Now we can generate an updated CRL. If this is the first time we revoke a certificate we have to prepare a counter:
echo "01" > crlnumber
Then generate the CRL:
openssl ca -config ../openssl.cnf -gencrl -out crl.pem
(insert the CA's passphrase). Check the CRL with:
openssl crl -text -noout -in crl.pem
Now we have to copy the crl.pem file into the server directory of EVERY server which uses that CA. Usually it's sufficient to just replace an old crl.pem with the new one without restarting OpenVPN, because the CRL is checked whenever an host tries to connect. But since this is the first time we have also to add the following line to the server.conf:
crl-verify ./crl.pem
and then reboot the service. It is also possible to un-revoke a certificate but it is not advisable (there are other ways to block temporarily an user).
Enjoy!
Feedbacks via email at tommaso[at)gagliardoni(dot]net very welcome :)
(Feb 20th, 2013) HowTo: Remote LUKS unlock via SSH/dropbear with multiple ethernet interfaces on Linux Debian
In this howto I will explain how to setup a minimal SSH server on a Debian system with LUKS full disc encryption (i.e.: the root directory is also encrypted) and with multiple ethernet interfaces. In fact, when using the standard howtos, it is always assumed that there is just a single ethernet interface. The difference is not negligible as we will see, since at the stage where dropbear starts the order in which the interfaces are raised is random - udev is not loaded yet. I will not explain in details here the typical scenario where you want to use this setup, but basically what you want to do is being able to reboot a remote machine where the discs are fully encrypted with LUKS. The solution is to install a minimal SSH server (dropbear) in the cleartext boot partition, connect to it and enter the password to unlock the rest of the filesystem, continuing the normal boot procedure.
Remote LUKS: the standard procedure
You can find the standard howto in the Debian cryptsetup documentation:
zcat /usr/share/doc/cryptsetup/README.remote.gz
First of all install the needed tools:
apt-get install dropbear busybox wipe
Check that /etc/initramfs-tools/initramfs.conf contains BUSYBOX=y and does NOT contain DROPBEAR=n .
The host keys used for the initramfs are dropbear_dss_host_key and dropbear_rsa_host_key, both located in/etc/initramfs-tools/etc/dropbear . The RSA key is "too small" by default. If you feel paranoid, delete it and create a new one:
rm /etc/initramfs-tools/etc/dropbear/dropbear_rsa_host_key
dropbearkey -t rsa -s 4096 -f /etc/initramfs-tools/etc/dropbear/dropbear_rsa_host_key
Now you want to generate an user (root) private SSH key to connect to the server. Only thing, it must be first created in Dropbear format:
dropbearkey -t rsa -s 4096 -f /etc/initramfs-tools/root/.ssh/id_rsa_dropbear
Then extract the public part:
dropbearkey -y -f /etc/initramfs-tools/root/.ssh/id_rsa_dropbear | grep "^ssh-rsa " > /etc/initramfs-tools/root/.ssh/id_rsa_dropbear.pub
and include it in the initrd authorized_keys file:
cat /etc/initramfs-tools/root/.ssh/id_rsa_dropbear.pub >> /etc/initramfs-tools/root/.ssh/authorized_keys
At this point (assuming you use OpenSSH to connect) you want your private key converted to OpenSSH format to connect:
/usr/lib/dropbear/dropbearconvert dropbear openssh /etc/initramfs-tools/root/.ssh/id_rsa_dropbear /etc/initramfs-tools/root/.ssh/id_rsa
and then we can delete the old Dropbear one, since we will use OpenSSH to connect:
wipe -f /etc/initramfs-tools/root/.ssh/id_rsa_dropbear
Now assume you want to use the interface eth0 (with DHCP enabled) to unlock your system. You have to add the following line in /etc/initramfs-tools/initramfs.conf :
DEVICE=eth0
Finally, recompile the server's initrd and reboot:
update-initramfs -u ALL
reboot
Let's assume your server is at www.myserver.com and the passphrase to unlock your LUKS setup is "hello world" (without quotes). I am assuming you have a LUKS setup with a single partition, or in any case you are requested for just ONE passphrase at boot (i.e. you use keyfiles stored in the first partition to unlock other partitions). Then, once your server is rebooted and hanged at boot waiting for the passphrase, you can unlock it remotely with the following command:
ssh -o "UserKnownHostsFile=~/.ssh/a_new_file_known_hosts" -i "~/.ssh/id_rsa" root@www.myserver.com "echo -ne \"hello world\" >/lib/cryptsetup/passfifo"
So far, so good.
Multiple ethernet interfaces
Now the problem: let's assume you have TWO (physical) ethernet interfaces, eth0 and eth1. Here you will find an issue: the order in which they are renamed at boot is random. This is because udev (which usually takes care of assigning the interfaces the correct name) is not started yet when Dropbear starts. So, sometimes the above solution will fail. One solution could be to tell Dropbear to listen over ALL the interfaces, but 1) it seems that Dropbear has a hard time doing so, since it was created for embedded environments where usually you cannot afford multiple servers 2) it may be not desirable (maybe one of the interfaces is a DMZ).
Luckily there is another, elegant solution: force some of the udev rules to be loaded in the initrd. Namely, if you open /usr/share/initramfs-tools/hooks/udev with an editor, look for around line 37:
for rules in 50-udev-default.rules 50-firmware.rules 60-persistent-storage.rules 80-drivers.rules 95-udev-late.rules; do
add 70-persistent-net.rules to the list, so it looks like this:
for rules in 50-udev-default.rules 50-firmware.rules 60-persistent-storage.rules 80-drivers.rules 95-udev-late.rules 70-persistent-net.rules; do
Save file. Regenerate initramfs and reboot:
update-initramfs -u ALL
reboot
Enjoy!
(Aug 23rd, 2012) An overview of position-based quantum cryptography.
An overview of position-based quantum cryptography.
Introduction
Imagine a secure cryptographical protocol where you can use your geographical position as a credential. For example, you could register your home location at your bank to secure your on-line banking account from connections not originating from your home PC. Or, as a military organization, you could send an encoded message that only troops deployed at a certain location could read. In general, this would link the security of the digital world to that of the physical world - the Holy Grail of on-line security. This is exactly what position-based cryptography (PBC) tries to achieve, and its goal has proven to be all but trivial. In fact, in order for this model to be meaningful, the geographical position cannot be obtained by external measurement services, which would then become the weak link of the security chain. I.e., it would not make sense to rely on something like the GPS satellite system to obtain coordinates, since this would open a plethora of new attack scenarios. The position should instead depend on some intrinsic properties of the system involved, something as cheating-proof as possible. In practice, this means to exploit some physical law which we are guaranteed to be unmodifiable by any known attacker - just as the GPS system relies on the constant speed of light to pinpoint position.
Cryptosystems relying on the idea of exploiting the physical world are theoretically unbreakable as long as the physical law holds, as their security does not depend, in principle, on any computational assumption. They are, of course, prone to implementation issues like any other cryptosystem, but we are guaranteed that as long as we understood correctly the physics we must not fear any surprise.
Must we?
The gap between theory and practice has always proven to be unpredictably wide and, as often happens, the good and the bad guys can use the same tools. The same physical properties which allow to create strong cryptograms also allow to devise new powerful attacks. In this article we will give an overlook of the rise, evolution, fall and resurrection of position-based cryptography augmented with the magic of quantum physics, keeping in mind that there is no final word to the everlasting arms race of security.
Classical PBC
A formalized model for PBC was first introduced - and proven to be insecure - in [CGMO09]. The idea of the original protocol was to achieve secure position verification via a distance bounding protocol based on relativistic assumptions (namely, the speed of light) and involving multiple verifiers to authenticate an honest prover.
Let us see an example in the 1-dimensional case. Consider a segment of space [0,1] and two verifiers, V_0 and V_1, sitting at positions 0 and 1 respectively. Then we have an honest prover P, standing at position 0.6, whose goal is to convince the two verifiers that he is located exactly at that position. We assume the following:
- there is a fixed and publicly known Boolean function f:{0,1}^n X {0,1}^n -> {0,1} which is very easy to compute and takes virtually no time to be evaluated for reasonable values of n
- the two verifiers V_0 and V_1 share a private channel which they can use to securely communicate with each other and synchronize their clocks
- all the parties are able to communicate just at a fixed, bounded speed (i.e.: we assume that they can broadcast radio waves or laser pulses at the speed of light)
Under these assumptions we can design many different position verification protocols, here is an example:
- P initializes the protocol, sending a request to the verifiers to be authenticated at position 0.6
- V_0 generates a random n-bit string x and shares it with V_1 through the private channel, V_1 does the same with another random n-bit string y
- V_0 generates a random bit b and, if f(x,y) = 1, sends a copy of b to V_1 through the private channel
- V_0 sends x and b to P, and V_1 sends y to P; they time their messages so that x, y and b arrive all at the same time at position 0.6
- P evaluates f(x,y): if the result is 0 then P routes back b to V_0, otherwise he routes b to V_1
- the verifiers accept the round if and only if V_f(x,y) receives the correct b at a time which is consistent with the claimed position 0.6 given the speed of light of the signal
- repeat the previous steps for k times (where k is a security parameter) for security amplification and authenticate P's position if and only if all the k rounds are passed.
It is pretty clear that a single malicious prover standing at a position different from what claimed cannot cheat with probability greater than 1/2 at each round. But it is easy for two colluding malicious provers, M0 and M_1 standing, e.g., at positions 0.3 and 0.8 respectively, to trick the verifiers into believing that there is a single honest prover at position 0.6, namely:
- as soon as M_0 receives x and b from V_0, she forwards a copy of both to M_1; M_1 does the same by forwarding a copy of y to M_0
- as soon as M_0 receives y from M_1, she computes f(x,y) and, if 0, sends b to V_0, otherwise does nothing; at the same time, as soon as M_1 receives b and x from M_0, she sends b to V_1 if f(x,y) = 1, otherwise does nothing.
It is easy to check that by summing up the travel time of the malicious attacker's messages, either V_0 or V_1 will receive the right b at the right time, hence the attackers can convince the verifiers that there is a honest prover at any given position between them.
This argument (formally proved in [CGMO09]) can be extended to any distance bounding protocol, concluding therefore that secure classical PBC against multiple adversaries is unachievable.
Quantum PBC
First ideas for quantum PBC (QPBC) appeared in the academic literature in 2010 [KMS10]. The idea is the following: since the above multi-adversary attack to classical PBC protocols relies on creating copies of some bit and keeping them before relying to the correct verifier, this attack fails if we use quantum bits (qubits) instead.
It is well known that a quantum state cannot be copied. In mechanical physics this is called the "No-Cloning Theorem", and it is a consequence of the thermodynamical Landau's Principle stating that in order to erase information embedded in a physical system one has to spend energy. Since in a closed physical system the total energy must be conserved, and since in order to copy a qubit one has first to "free space" (erase another qubit) to copy the given state into it, it turns out that it is impossible to copy a qubit in a reversible way. The other option is to have the system interact with another system (the observer) in order to measure the given qubit and then prepare another qubit from scratches in the measured state. But by the postulates of quantum mechanics, the process of measurement destroys the original quantum state with very high probability, it is therefore impossible to make a perfect copy of a qubit. This "magic" property of quantum mechanics has been exploited to design new, innovative, unconditionally secure cryptographical schemes and it is at the base of quantum cryptography [BB84].
In QPBC, part of the information exchanged by prover and verifiers consists of some quantum state |phi> which must be measured at a certain step of the protocol and act as a "guarantee" that the particular step can be only performed once for every round. Under the same conditions as the protocol in the previous section, let us consider the following quantum variation:
- P initializes the protocol, sending a request to the verifiers to be authenticated at position 0.6
- V_0 generates a random n-bit string x and shares it with V_1 through the private channel, V_1 does the same with another random n-bit string y
- V_0 generates an entangled EPR pair |ab> = (|00>+|11>)/sqrt(2); if f(x,y) = 1, he sends the first half of the registry, |a>, to V_1 through the private channel, otherwise keeps this half for himself
- V_0 sends x and the other half of the EPR registry, |b>, to P, and V_1 sends y to P; they time their messages so that x, y and |b> arrive all at the same time at position 0.6
- P evaluates f(x,y): if the result is 0 then P routes back |b> to V_0, otherwise he routes |b> to V_1
- the verifiers accept the round if and only if V_f(x,y) receives the qubit |b> at a time which is consistent with the claimed position 0.6 given the speed of light of the signal and it is consistent with a Bell measurement performed together with the other half |a>
- repeat the previous steps for k times (where k is a security parameter) for security amplification and authenticate P's position if and only if all the k rounds are passed.
A Bell measurement over two qubits in this case is just a "test" to see whether the two qubits have preserved entanglement or not. Since measuring any of the two qubits destroys entanglement, if this test is passed it means that the qubit |b> has not been measured (and hence has not been replaced nor partially copied). Under this condition it is clear that no coalition of malicious attackers can impersonate a honest P with good probability. In fact, the attack to the classical protocol relies on the fact that the bit b can be copied and distributed amongst the attackers without the verifiers noticing it, which turns out to be impossible with the quantum state |b>. Notice that this protocol only needs a single EPR pair for each of the k round in order to achieve k bits of security, which is pretty efficient.
Breaking QPBC
QPBC looks really unbreakable so far, but unfortunately it does not keep into account the fact that entanglement can also be used by malicious attackers to perform one of the weirdest feats of quantum information: distributed computation via teleporting. This is a consequence of the fact that entanglement between qubits is a non-classical interaction, very different from anything we have been knowing in the last few centuries, like electromagnetic or gravitational interactions. One of its consequences is that if two parties share an entangled EPR pair, then one of the parties can teleport an additional qubit to the other party by sending two classical bits of information and destroying the EPR pair by performing a Bell measurement over the qubit and one of the halves of the EPR pair [NC00]. Let us now see how this can be used by malicious attackers M_0 and M_1 to break the QPBC protocol above in the case where n=1 and f(x,y) = x XOR y:
- M_0 and M_1 share three entangled EPR pairs, labelled 0, 1 and 2 respectively, and initialize the protocol
- let's assume that f(x,y) = 0, then M_0 receives x (a 1-bit string) and |b>, while M_1 receives the 1-bit string y
- M_0 uses the EPR pair labelled x to teleport |b> to M_1, and sends x and the two classical bits for teleportation to M_1 (notice that these three classical bits will travel at the speed of light)
- at the same time, M_1 teleports her half of the EPR pair labelled y using EPR channel 2, and sends y and her two classical teleportation bits to M_0 (again, these three bits will travel at the speed of light)
- when the classical bits arrive at their destinations (in a single round of simultaneous communication), both cheaters can compute f(x,y)
- if f(x,y) = 0, then it is easy to check that |b> has been teleported in M_0's EPR register 2 (and M_0 is able to recover it since she has also received M_1's teleportation bits); otherwise it is easy to check that |b> has been teleported in M_1's EPR register labelled x (and M_1 is able to recover it, since she has received both x and M_0's teleportation bits)
- in both cases, it is easy to check that, with a single round of simultaneous communication, the "correct" cheater has received |b> just in time to route it to the "correct" prover, hence breaking the security of the protocol.
This attack can be generalized to any n and any suitable f, the basic idea being the following: if the two attackers share an arbitrary amount of EPR pairs, then they compute the function f "in parallel", like if they were using a single (quantum) computer made of a split (quantum) register physically separated in space.
This is an intrinsic property of quantum computing: non-classical correlations are not limited to the speed of light (in a sense which is still not completely understood). For example it could be possible to have a two-qubit quantum computer where one of the qubits resides on Earth ant the other one is located on Mars, and still it would work perfectly like if we had a single joint register. It is proven, however, that it is impossible to exploit this property to make "miracles" - e.g.: to violate Einstein's relativity principle. Namely, even if the two registers are quantum-jointed (and it is thus possible to perform operations on both simultaneously), it is impossible to access the information of a remote register without transmitting classical information. This is exactly what the classical teleportation bits are for, the interesting part being that the process of computation can be "parallelized" through the EPR channels and can then be performed by using a single round of classical communication - which is enough to break our QPBC protocol.
Future directions
QPBC is thus proven to be insecure in case of multiple colluding attackers sharing an arbitrary amount of EPR pairs. But we must consider that EPR pairs are a costly resource (they are currently, and there is no evidence that they shouldn't be in the future). This has led to an interesting observation.
Let us forget for a second about entangled-capable adversaries and let consider the role of the parameter n in the QPBC protocol above. It has basically no importance, in the sense that the security of the protocol does not depend on it - while depending on the parameter k instead. This means that, in theory, there is nothing wrong in setting n = 1 and using a very simple function f, like the XOR example above. But if we consider the entanglement attack, while the same observation remains true for honest prover and verifiers, n makes a difference for the malicious attackers instead. Namely, the larger n, the more and more EPR pairs M_0 and M_1 need to share in order to compute f.
The QPBC protocol above is then interesting for the following fact: while it only requires a single EPR pair to be used by honest parties for each round, it requires some larger amount of entangled resources to be used by malicious attackers, and this amount in general depends on n. This trade-off can be stated as: the more (cheap) classical computing resources are needed by honest parties, the more (costly) entangled resources are needed by the attackers, which is a pretty nice feature.
This is not an absolute statement though, because it also depends on the function f. Namely, there exist easy to compute functions f where the amount of EPR pairs needed to compute f is small (such as logarithmic in n, or even constant). In order to exploit the aforementioned trade-off in real scenarios we have hence to find some - easy to compute, i.e. in P - functions where the number of EPR pairs needed for its evaluation grows as fast as possible in n.
The Garden-Hose Game is a computational model introduced exactly for this purpose: to model the EPR-related complexity of a function. It basically consists of two players (with their respective inputs x and y) separated by some distance who want to compute a Boolean function f(x,y) in the following way: they have some fixed pipes running between them, plus they have pieces of garden-hose which they can use to connect the ends of the pipes at their location into a pattern dependant on their input only (no communication allowed). There are no T-shaped (or more complex) pieces of hose, just one-to-one connections, but not all the pipes need to be connected. One of the players then has a source of water (tap) which is connected to one of the loose ends of the pipes. The players can arrange their hose pieces in such a way that f(x,y) = 0 if the water eventually reaches one of player 0's ends, 1 else. It is easy to see that water will eventually exit from one side or another, and that this model is closely related to the teleportation technique used to break QPBC. The Garden-Hose complexity GH(f) of a function f:{0,1}^n X {0,1}^n -> {0,1} is then defined as the minimum number of pipes necessary for the two players to compute its output for any input in the above way.
Some computational-theoretic results are known about bounds on GH(f), namely:
- GH(f) <= 2^n + 1, for any Boolean function
- if f is in L (computable in logarithmic space on a deterministic Turing Machine), then GH(f) is at most polynomial in n
- if GH(f) is polynomial in n, then f is in L (up to local preprocessing)
- if there exists an f in P such that GH(f) is super-polynomial in n, then P != L (notice that L is a subset of P, but it is currently unknown if the equivalence hold)
- there exist functions f such that GH(f) is exponential in n, but it is unknown whether they are also in P or not.
So, if we could find a function f which is in P, but has an exponential GH(f), that one would be a perfectly good candidate for use in QPBC, making the above attack infeasible for reasonable values of n. But the existence of such a function would imply a major breakthrough in computational complexity. Up to now only functions with polynomial Garden-Hose complexity are known, but the road is open to new, exciting directions.
References
- [BB84] Bennet, Brassard: "Quantum cryptography: Public key distribution and coin tossing", Proceedings of IEEE International Conference on Computers, System and Signal Processing
- [BCF+11] Buhrman, Chandran, Fehr, Gelles, Goyal, Ostrovsky, Schaffner: "Position-based quantum cryptography: Impossibility and constructions", CRYPTO 2011
- [BFSS11] Buhrman, Fehr, Schaffner, Speelman: "The Garden-Hose Game", arXiv:1109.2563v2
- [CGMO09] Chandran, Goyal, Moriarty, Ostrovsky: "Position-based cryptography", CRYPTO 2009
- [KMS10] Kent, Munro, Spiller: "Quantum Tagging: authenticating location via quantum information and relativistic signalling constraints", arXiv/quant-ph:1008.2147
- [NC00] Nielsen, Chuang: "Quantum Computation and Quantum Information", Cambridge University Press, 2000.
(Jun 25th, 2012) Waterloo (ON), 12th Canadian Summer School on Quantum Information, 9th Canadian Student Conference on Quantum Information, 2nd AQuA Student Congress on Quantum Information and Computation.
I've just come back from this big event in Waterloo, Canada. The past two weeks have been quite intensive, though I had the opportunity of visiting some nice places (Niagara Falls are cool, but I prefer Toronto, especially by night). Waterloo is one of the leading places in the world for quantum stuff, with its three main research centers: the University of Waterloo, the Perimeter Institute and the Institute for Quantum Computing. The university campus is really cool, with a lot of wild animals around (beavers, squirrels, groundhogs, bunnies, eagles... but beware of the damn aggressive gees and small birds attacking people at random!), although everything is quite expensive (especially food, and by the way I didn't see many overweight people around...) and the accommodation was... embarrasingly uncomfortable. I've also given a talk about provable security in the quantum random oracle model. Nightlife in Waterloo is not very intensive. Best places to visit: The Flying Dog (salsa place, young people on Thurday night) and the Revolution (disco club).
(Oct 1st, 2011) A general mathematical principle to achieve `perfect' social justice
Some random thoughts about the `fairness' of a punishment in respect to a crime. The principle `the harsher the crime, the harsher the punishment' is not given for granted, but should be a consequence of a deeper principle. Also, I think that the principle in according to which `a punishment only serves to re-habilitate the criminal' is somehow incomplete, since it can be abused: re-habilitation comes automatically once the criminal has repaid all the `damage' caused by his/her crime. Moreover, a punishment is not `fair' if the personal gain obtained in performing a crime is exaclty balanced by the punishment but should be harsher, since not every crime is prosecuted (not every criminal is caught, or else we wouldn't have criminals). I am not a jurist, so maybe I am telling something trivial, but IMHO the only general `fair' rule should be the following:
The punishment for a certain crime should be equal to the `social damage' caused by that crime, divided by the probability of that crime to be prosecuted.
where:
- `social damage' is assessed on empirical bases by a competent, indipendent organism, and should include the costs needed for the prosecution, moral and physical damages caused by the crime, its consequencies and so on
- 'punishment' should always be commuted in appropriate forms, e.g., it is completely pointless to physically punish a murderer since this does by no mean `repay' the social damage caused by the murder; a murderer should instead, e.g., do useful, harsh, underpaid jobs for many years to the benefit of the victim's family, friends, colleagues and whatever, until a `fair' balance (estabilished by a judge) has been reached between the crime and the repaid social gain (in most of the cases a `fair' social gain, according to the victim's family, could only be reached with the murderer's execution, but a mathematical principle should not include emotionality in its formulation)
- `probability' of a crime to be prosecuted should be computed over historical records for known crimes, and over empirical considerations for emerging crimes, in collaboration with police forces or, however, with organisms competent in performing such an estimate.
EXAMPLE:
A businessman is caught evading 100k EUR of taxes.
The total annual cost of the legal and bureaucratic organisms fighting tax evasion is, say, 500M EUR, but it must be weighted against the ratio between mean total tax evasion (let's say 10G EUR per year) and the amount we are taking here into account (so: 100k * 500M / 10G = 5k EUR).
Plus the judge establishes that there is an additional "mean social damage" (due, i.e., to emulation phenomena) of 2k EUR.
So: the total "social damage" amounts to 107k EUR. This must be divided by the probability of being caught evading taxes, let's say 15%. Then: 107k / 0.15 = 713k EUR (rounded down). This is the total amount the criminal has to repay as a punishment to make complete atonishment, either through fines (provided he has enough money) or social works (which should then be paid much more than now), or a balance between the two. This looks a lot, but it is the only amount statistically effective.
This principle is `fair', in the meaning that it makes both the crime and the prosecution of the crime `statistically non-convenient'. It is also `rational', for there is no room allowed for more or less `hated' crimes (usually subject to manipulation, emotional reactions, demagogy and so on), though it is `elastic', since the definition of `social damage' can take into account many factors.
Note that a corollary of this principle is the following: once a criminal has completely made atonishment for his/her guilt, he/she is really `free'. All the damage has been repaid, in every possible rational and practical meaning, so that subsequent discriminations because of his/her police records should not be allowed. Also, the criminal's rehabilitation is automatic. Tests to see if he/she is still capable of crimes should not be necessary, because after the atonishment we don't have a criminal anymore: we have a common citizen who has repaid to the society more than the damage caused. He/she should already be `rehabilitated' enough. Recidivism has never to be taken into account too.
These are just my thoughts anyway, and a test for the making of a blog on this website if and when I will have some time to set it up. Feedbacks appreciated via email :)
(May 27th, 2011) My thesis and slides : `Classical simulation of quantum circuits'
Here are my Master thesis (in English) and related slides (in Italian), should some visitor be interested.